Download

1 / 43
430 likes | 543 Views
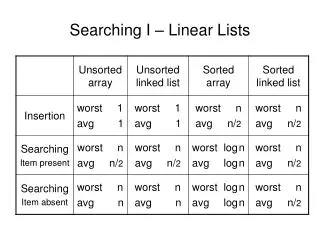
Searching Featured Lists. Mercer University Libraries. Jeremy Brown Linda Chen. About Mercer University. Academic University 11 Schools 10,000+ students. Featured Lists. User Manual Page #107098 Supports review files of bib or item records Do Not support other record types

E N D
Searching Featured Lists MercerUniversity Libraries Jeremy Brown Linda Chen
About Mercer University Academic University 11 Schools 10,000+ students
Featured Lists User Manual Page #107098 Supports review files of bib or item records Do Not support other record types Need to keep the list(s) from the Creating List
2 Steps Create a list Set up a WWWOption
Step 2 - WWWOption User Manual Page # 106908 WWWOPTION: FEATURED_LIST
Example 1 WWWOPTION: FEATURED_LIST=[list]|[table_header]| [revfile_header]|[#recs_header] FEATURED_LIST= 01,03,12,17
Example 2 WWWOPTION: FEATURED_LIST=[list]|[table_header]| [revfile_header]|[#recs_header] FEATURED_LIST=01,03,12,17|SELECTED TITLES|TOPIC|# TITLES
Our WWWOption FEATURED_LIST=[list]|[table_header]| [revfile_header]|[#recs_header] FEATURED_LIST=03,02,05,06,36|February 2012| Collections|# Titles
Feature List What do we use it for? Monthly New Book Lists Special Projects Display Different Collections Anyone has other suggestion?
Feature List This is ok, but.. Something is missing… Cannot search the list
What We Wanted Menu of Feature Lists to Search Keyword Search function
What We Noticed Feature List URLs always contain “ftlist” Review file number Result Record URLs always contain Review file number Bibliographic record number
This Sounded Indexable! Each URL contains the list review file Each URL contains the bib number Bibliographic records have lots of key words.
Technologies Used Nutch: http://nutch.apache.org/ SOLR: http://lucene.apache.org/solr/ jQuery/AJAX: http://jquery.com
Crawl The WebPAC
What Does Nutch Do? Read list of URLs Download one of the URLs Extract all the links on the page, add to list of URLs Extract the full text of the page Repeat until done with URLs Send Pages to SOLR for indexing
Set up WebPAC for Crawling We need to let our crawler look at the WebPAC Name the crawler in [nutch_home]/conf/nutch-site.xml Edit /iiidb/http/robots.txt Add: User-agent: MercuSpider Disallow:
Goals of Nutch URL Configuration Only want bibs from the featured lists We do not want to crawl: MARC view Save record screens Request item screens Probably others… We do not want to index the whole WebPAC
Set up Nutch for Crawling the WebPAC Edit nutch/conf/regex-urlfilter.txt Add: -^http://library.mercer.edu/.*request.* -^http://library.mercer.edu/.*save.* -^http://library.mercer.edu/.*marc.* +^http://library.mercer.edu/search~S1.*ftlist
Indexing with SOLR
What Is SOLR? A search engine in a box Put documents in Creates a full text index Answers queries
Set up Solr for Crawling the WebPAC SOLR comes ready to run It works well with Nutch Easy to use as search engine back end
The Single, Solitary SOLR Modification Add to solr-example/solr/conf/solrconfig.xml <requestHandlername="/mercuFtlist" class="solr.StandardRequestHandler"> <lstname="defaults"> <intname="rows">10</int> <strname="echoParams">explicit</str> <strname="fl">url,id</str> </lst> <lstname="appends"> <strname="fq">(url:ftlist)+(url:\+\+ftlist/\+\+ftlist)</str> </lst> <lstname="invariants"> <boolname="facet">false</bool> </lst> </requestHandler>
SOLR Request Handler, Explained We only want the URL and ID in our results We only want to search items that appear in the feature list <strname="fl">url,id</str> <strname="fq">(url:ftlist)+(url:\+\+ftlist/\+\+ftlist)</str>
Architecture Standard web form AJAX calls to SOLR for results AJAX results enhancement
More Information Our Featured Lists:http://library.mercer.edu/search~S1?/ftlist Visit our Systems page:http://libraries.mercer.edu/university-libraries/systems-department/iug-2012or: http://goo.gl/3q3QV MAJAX is located here:http://libx.org/majax/