Download

1 / 31
310 likes | 447 Views
PlanetLab: A Platform for Planetary-Scale Services. Mic Bowman (mic.bowman@intel.com). Agenda. What Is PlanetLab? Planetary-Scale Services Evolving the Internet Why PlanetLab?. PlanetLab Is…. Technology: An open, global network test-bed for inventing novel planetary-scale services.

E N D
PlanetLab: A Platform for Planetary-Scale Services Mic Bowman(mic.bowman@intel.com)
Agenda • What Is PlanetLab? • Planetary-Scale Services • Evolving the Internet • Why PlanetLab?
PlanetLab Is… • Technology: • An open, global network test-bed for inventing novel planetary-scale services. • A model for introducing innovations into the Internet through the use of overlay networks. • Organization: • A collaborative effort involving academic and corporate researchers from around the world • Hosted by Princeton, Washington, Berkeley, and MIT; sponsored by Intel, HP, and Google • Socially • Cutting edge research infrastructure made available to the global community
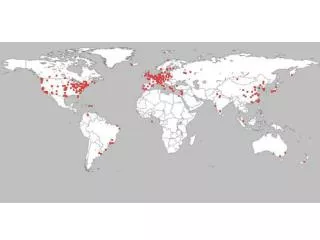
PlanetLab Is… • IA32 servers (836 1000’s) connected to the Internet at 412 sites • Federated with PlanetLab Europe • Mostly standard Linux distribution and dev environment • A few global services
Academic Partipants Other brands and names are the property of their respective owners.
Industry Participants Other brands and names are the property of their respective owners.
Agenda • What Is PlanetLab? • Planetary-Scale Services • Evolving the Internet Architecture • Why PlanetLab?
Content Distribution, 1993 • NCSA’s “What’s New” the most viewed page on the web (100K accesses per month). • All clients access a single copy of the page stored on a single server. End-to-End design works pretty well for store-and-forward applications
Content Distribution, 1998 • IBM web “server” handles a record 100K hits per minute at the Nagano Olympics • DFS running on SP2’s used to distribute 70K pages to 9 geographically distributed locations End-to-End design breaks down at scale (flash crowds, global distribution, …)
Content Distribution TodayA Planetary-Scale Service • Edge services provide 1000’s of points of presence throughout the Internet • Overlay networks are constructed to move the content around efficiently The transition from “end-to-end” to “overlay” enables reliable planetary-scale services
Planetary-Scale Services • Pervasive • Runs everywhere, all the time • Robust • Robust system from flaky components • Adaptive • Aware of and adapts to changing environment • Scalable • Scales to a global workload
To Build One, You Need… • Multiple vantage points on the network • Near the edge—low latency to clients • Near the core—good connectivity • Global presence • A little computation at many locations • Computation beyond a single machine • Computation beyond a single organization • Management services appropriate to the task • Resource allocation • Provisioning and configuration • Monitoring nodes, services, networks • But who can afford it? • No single app can justify the infrastructure costs • Network today is like big-iron before timeshare
Solution: Share the Platform • Everyone contributes a piece of the platform; everyone can use the whole platform • Build a “time-sharing” network-service platform • Cost shared among all the apps using it • Model of future public computing utility • Nodes owned by many organizations • Shared cooperatively to provide resilience • Platform must provide • Isolation to protect services from one another • Market-based resource allocation
Mgmt. VM Service Virtual Machines VMM Hardware PlanetLab Service Architecture Node 1 Node 3 Node 2 Node 4 Node 5
PlanetLab Services are Running Infrastructure Services & End-user Services Event Processing Network Mapping Distributed Hash Tables Content Distribution Web Casting Node 1 Node 3 Node 2 Node 4 Node 5
Resource Reservations • CPU resources can be scarce during certain periods (before paper deadlines) • The Sirius Resource Calendar Service allows PlanetLab users to schedule an increase a slice’s CPU priority for certain time periods • Only CPU and not work • Seems to work well: • Rarely 50% subscribed • Services often deal with CPU loading themselves
PlanetLab Today… • 836 IA32 machines at 412 sites • Principally universities, some enterprise • Research networks: I2, CANet/4, RNP, CERNet • Globally distributed • Some co-location centers • Federated with PlanetLab Europe • Machines virtualized at syscall level • Name space isolation for security • Network, CPU, memory, file system isolation • Interface is a Linux machine with minimal install • Complete access to the network
What We Got Right • Immediate impact • Within 18 months 25% of publications at top OS & Comm conferences were PlanetLab experiments • Became a “expectation” for validation of large system results • And we learned some very interesting things
What We Got Right (continued) • Incident response • Early: very conservative • Don’t get turned off before value is established • Later: less restrictions • Local administrators defend their researchers • Education • Researchers: the kind of experiment that causes alarms • Administrators: touchy IDS implementations
We Could Have Done Better • Community contributions to the infrastructure • Infrastructure development remained centralized, we are paying the price now • Support for long-running services • Researchers aren’t motivated to keep services running for multiple years • Decreased the amount of service composition (can’t trust the dependent services will continue to run)
We Could Have Done Better (continued) • Admission control • Good practices make it possible to run many experiments, but very easy to consume all resources
Open Challenges • Community ownership of availability • Need to motivate decentralized management • Who keeps the nodes running? • What happens when the nodes aren’t running? • Resource allocation aligned objectives • Performance, innovation, stability
Open Challenges (continued) • Standardization • Standard interfaces platform stability • Open architecture improved innovation • Tech Transfer
Agenda • What Is PlanetLab? • Planetary-Scale Services • Evolving the Internet Architecture • Why PlanetLab?
PlanetLab and Industry • Global communications company • Incubator for future Internet infrastructure • Emerging services become a part of the Internet • Global computer vendor • Platform for planetary-scale services • Need to understand for our customers • Software company • Testbed for next generation applications • Cost-effective way to test new ideas • Fortune 500 company • Next generation opportunities for IT staff • Leverage deployed PlanetLab services for CDN, object location, network health…
Summary • PlanetLab is: • A globally distributed testbed that facilitates experimentation and deployment of scalable Internet services. • The testbed has successfully established itself as a platform for cutting edge research. • Active research community using it for a wide variety of technologies. • Multiple papers published top academic conferences, e.g. OSDI, SOSP, NSDI, Sigcomm, … • 300+ active projects • Come join the fun (www.planet-lab.org)
CCC BBB A A A A C C C C AA B B B B Princeton: CoDeeN • Content distribution • Partial replication of content • Redirect requests to optimal location of content • PlanetLab Deployment • 100 nodes, 150+ GB of data moved among the sites • Working to build service redirector • Key Learnings • First service targeted for end users (proxy cache) • Maintaining server health is hard and unpredictable
UWashington: Scriptroute • Distributed Internet debugging and measurement • Distribute measurement points throughout the network • Allow user to connect & make a measurement (upload scripts) • PlanetLab Deployment • Running on about 100 nodes • Basic service used by other services • Observations • Experiments look like port scan attacks • Low BW traffic to lots of addrs breaks some routers • Scriptroute adjusted spray of packets to avoid the problem
Cornell: Beehive • DHT for object location • High performance • Self-organizing • Scalable • Proactive-replication • Hash buckets replicated • O(1) lookup times for queries • CoDoNs: DNS replacement • High performance P2P • Adaptive, load balancing • Cache coherent
Usage Stats • Slices: 600+ • Users: 2500+ • Bytes-per-day: 4 TB • IP-flows-per-day: 190M • Unique IP-addrs-per-day: 1M (source: Larry Peterson, May 2007)