Download

1 / 17
180 likes | 386 Views
Inverting Matrices. Determinants and Matrix Multiplication. Determinants. Square matrices have determinants, which are useful in other matrix operations, especially inversion . For a second-order square matrix , A , the determinant is. Consider the following bivariate raw data matrix.

E N D
Inverting Matrices Determinants and Matrix Multiplication
Determinants • Square matrices have determinants, which are useful in other matrix operations, especially inversion. • For a second-order squarematrix, A,the determinant is
Consider the following bivariate raw data matrix from which the following XY variance-covariance matrix is obtained:
Think of the variance-covariance matrix as containing information about the two variables – the more variable X and Y are, the more information you have. Any redundancy between X and Y reduces the total amount of information you have -- to the extent that you have covariance between X and Y, you have less total information.
Generalized Variance • The determinant tells you how much information the matrix has about the variance in the variables – the generalized variance, • after removing redundancy among variables. • We took the product of the variances and then subtracted the product of the covariances(redundancy).
Imagine a Rectangle • Its width represents information on X • Its height represents information on Y • X is perpendicular to Y (orthogonal), thus rXY = 0. • The area of the rectangle represents the total information on X and Y. • With covariance = 0, the determinant = the product of the two variances minus 0.
Imagine a Parallelogram • Allowing X and Y to be correlated with one another moves the angle between height and width away from 90 degrees. • As the angle moves further and further away from 90 degrees, the area of the parallelogram is also reduced. • Eventually to zero (when X and Y are perfectly correlated). • See the Generalized Variance video clip in BlackBoard.
Consider This Data Matrix Variance-Covariance Matrix Since X and Y are perfectly correlated, the generalized variance is nil.
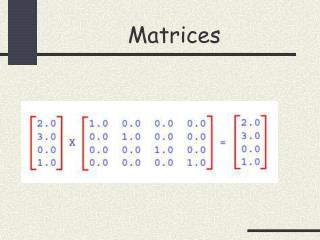
Identity Matrix • An identity matrix has 1’s on its main diagonal, 0’s elsewhere.
Inversion • The inverted matrix is that which when multiplied by A yields the identity matrix. That is, AA1= A1A =I. • With scalars, multiplication bythe inverse yields the scalar identity. • Multiplication by an inverseis like division with scalars.
Inverting a 2x2 Matrix • For our original variance/covariance matrix:
Multiplying a Scalar by a Matrix • Simply multiply each matrix element by the scalar (1/177.75 in this case). • The resulting inverse matrix is:
SAS Will Do It For You • ProcIML; • reset print; display each matrix when created • XY ={ enter the matrix XY • 25621.5, comma at end of row • 21.52.5}; matrix within { } • determinant = det(XY); find determinant • inverse = inv(XY); find inverse • identity = XY*inverse; multiply by inverse • quit;
XY 2 rows 2 cols 256 21.5 21.5 2.5 DETERMINANT 1 row 1 col 177.75 INVERSE 2 rows 2 cols 0.0140647 -0.120956 -0.1209560 1.440225 IDENTITY 2 rows 2 cols 1 -2.22E-16 -2.08E-17 1

![[MATRICES ]](https://cdn4.slideserve.com/144276/matrices-dt.jpg)