Download
1 / 57
570 likes | 756 Views
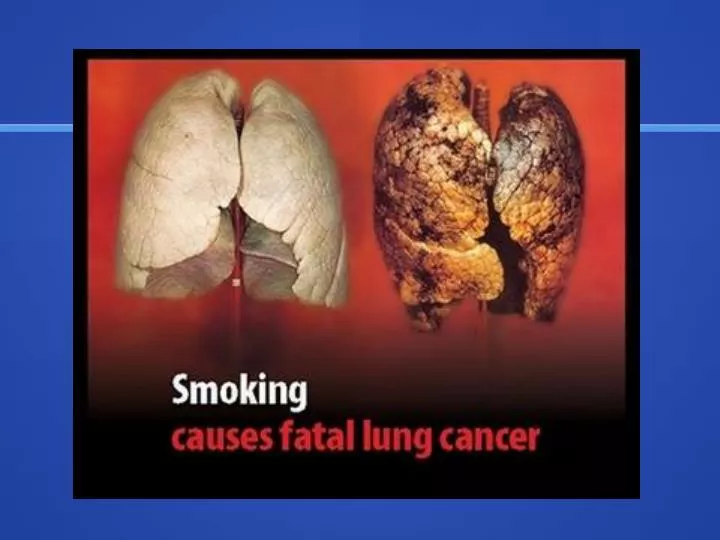
http://www.youtube.com/watch?v=Co7dvbhtsJg. Smoking Habits. There are over 1 billion people in the world that smoke tobacco Of these 5-6 million will die on an annual basis This habit increases the likelihood of developing lung cancer to 20 times that of a non-smoker.

E N D
Smoking Habits • There are over 1 billion people in the world that smoke tobacco • Of these 5-6 million will die on an annual basis • This habit increases the likelihood of developing lung cancer to 20 times that of a non-smoker
Outline • Sequencing of SCLC cell line • Somatic mutation • Mutation signatures in NCI-H209 • DNA repair pathways • Genomic Rearrangement-specifically CHD7
Sequencing of a SCLC cell line • Why use SCLC? • Not surgically resected • Cell line • NCI-H209 • Immortal cell line • 55-year-old male with SCLC • Smoking history not recorded • Showed histologically typical small cells • >97% of such tumors associated with tobacco smoking • Taken before chemotherapy
Sequencing: The SOLiD Platform • Massively parallel next-generation sequencing • Greater than 99.94% accuracy • Relatively inexpensive • Allows for: • Whole genome sequencing • Targeted resequencing • Gene expression data
Sample preparation • Fragment library or mate pair libraries • Libraries are sheared and adaptor molecules are ligated to each unique molecule
Each molecule attached to a bead • Amplified using emulsion PCR • 3’ end modification • Beads are covalently attached to a glass slide
A universal sequencing primer, ligase, and a set of fluorescently labeled di-base probes are introduced
Multiple cycles of ligation, detection, and cleavage performed • After the template has been read, synthesized strand removed • Primer attaches to template offset by 1 nucleotide
Coverage • Figure 1A • Minimum 30x coverage • Figure 1B • 39x coverage for tumour • 31x coverage for normal cell line
Bioinformatics • Identify somatically acquired mutations from sequence data • 77 coding substitutions • 333 random variants • Indels difficult to detect Supplementary Fig.1
Somatically acquired genomic variants • 22,910 somatically acquired (not inherited) mutations • 70% intergenic • 28% intronic • 0.8% non-coding translated • 0.6% coding
Figure 1C • Somatic mutations of NCI-H209 genome • Deletions, insertions, heterozygous and homozygous substitutions, mis-sense, nonsense, and rearrangements
Point mutations in coding regions • RB1 C706F Point Mutation • Nonconservative amino acid substitution • Inhibits phosphorylation and abolishes protein function • TP53 Splice Site Disruption • TP53 encodes p53, a tumor suppressor • Combination of RB1 and TP53 characteristic of SCLC
Non-synonymous vs. Synonymous • Non-synonymous • Codes for different amino acid • Synonymous • Amino acid produced not modified • Accumulation of mutations increasing fitness will be shown as an excess of non-synonymous • Observed ratio not different than that expected by chance • Suggests that the majority of coding variants do not confer selective advantage
Mutations in regulatory regions • Little known about mutations occurring on either side of transcription start sites • Supplementary Fig. 2A • Find somatic substitutions within 2kb of known transcription start sites
Apply hidden Markov models • AI program that can be trained to find sequences • Predict which substitutions might affect transcription factor binding sites • Supplementary Fig. 2B • Distribution observed no different than that those mutations seen in random “simulated sets” of mutations
May still be mutations that alter transcription factor binding and affect gene regulation • Example Supplementary Fig. 2C • T>G in RAS oncogene family gene, RAB42 • Disrupts potential binding motif
Big picture of somatic mutations • Data indicates that most of the mutations in the coding and promoter regions are passenger events • Events that don’t contribute to the development of cancer, but have occurred during cancer growth • Mutations confer no selective advantage to the cells
Tobacco smoke contains more than 60 carcinogens which bind and chemically modify DNA.
-Change the alpha helix • Allow non-Watson–Crick pairing • Get in the way The carcinogen binds to the DNA forming a bulky adducts at purine bases (guanine and adenine).
Most Common Transversions G>T/C>A (34%) G>A/C>T (21%) A>G/T>C (19%) Top 3 transversions are all purines…
This distribution of transversions is consistent with the literature • Shows there is consistenency with mutational patterns. • Control for in vivo mutation
(34%) of total mutations • G>T transversions occur more frequently at methylatedCpGdinucleotides
CpG Sites cytosine-phosphate- guanine
(34%) of total mutations • G>T transversions occur more frequently at methylatedCpGdinucleotides • In mammals, 70% to 80% of CpG are methylated
5’ 3’ 3’ 5’ CpG Island: High frequency of cytosine connected to guanine. • CpG islands are regions that contain a high CpG content. • They are in and near approximately 40% of promoters of mammalian genes.
It’s getting complicated so lets recap: • Most transversion mutations (34% of total) are G>T • The G >T mutations happen often at CpG sites • The G >T mutations which happen at CpG sites are often methylatedCpG sites
When looking at guanines in the genome, how often is the nucleotide preceding it a cytosine? This often in the genome, a C is expected to precede a G
When looking at guanines in the genome, how often is the nucleotide preceding it a cytosine? This often in a G>T mutations, a C precedes the G
Wait, what? 3’ 5’ 5’ 3’ -N-N-N-N-?-G-N-N-N-N-N-N-N-C-G-N-N-N-N-?-G>T-N-N-N-N-N-?-G-N-N-N- The expected fraction of CpG’s per Guanine in genomic DNA The fraction of G>Ts mutations on CpG’s per guanine in CpG islands. If everything was random, we would expect the G>T mutations to have an equal make up of CpG/G, as genomic CpG/G… …but that is not so!
When looking at guanines in the genome, how often is the nucleotide preceding it a cytosine? This often in a G>T mutations, a C precedes the G
When looking at guanines in the genome, how often is the nucleotide preceding it a cytosine? This often in a G>A mutation, a C precedes the G • Often occur outside CpG islands. • Unusually high fraction likely due to spontaneous deamination of methylated cytosine to thymine
When looking at guanines in the genome, how often is the nucleotide preceding it a cytosine? This often in a G>C mutation, a C precedes the G • similar to G>T but these were significantly more likely to occur within CpG islands
WHAT DOES THIS ALL MEAN? “Thus, the sequence context of the 23,000 mutations in the NCI-H209 genome provides tremendous power to identify multiple distinctive mutation signatures, not evident from targeted re-sequencing studies of limited genomic regions.”
It’s getting complicated (still) so lets recap: • Most transversion mutations (34% of total) are G>T • The G >T mutations happen often at CpG sites • The G >T mutations which happen at CpG sites are often methylatedCpG sites.
So how does the Methylation play into all this? • Only 10–20% of CpGdinucleotides in CpG islands are methylated while 60–70% CpG sites are methylated outside the islands. • This provides a model to see how methylation of CpG sites affects C>T mutations.
In other words, lets compare the frequency of G>C mutations here and here to see how methylation effects mutation. Non CpG Island CpG Island 5’ 3’ 3’ 5’ 60-70 Percent Methylated 10-20 Percent Methylated
Non CpG islands CpG islands Less CpG mutations in CpG islands than CpGs in non CpG islands.
Non CpG Island 60-70 Percent Methylated More C>T Mutation CpG Island 10-20 Percent Methylated Less C>T Mutation 5’ 3’ 3’ 5’ Less G>C mutations in the islands…and there is less methylation in the islands….. …suggesting that C>T mutations preferentially occur at methylatedCpGs
Can’t we fix this??? • Bulky adducts on purines are the most common source of DNA damage from tobacco carcinogens. • These bulky adducts get in the way of the RNA polymerase. • When the RNA polymerase stops, it recruits nucleotide excision repair machinery, leading to excision of the altered nucleotide, preventing mutation.
The more expression, the more the repair. • Mutation repair in non transcribed regions occurred less frequently than transcribed regions (good!).
This suggests at least two separate DNA repair pathways • Which suggests “distinct physicochemical effects on DNA structure, with variable recognition and excision by the genome surveillance machinery.”
Genomic Rearrangements & Copy Number NCI-H209 genome has 58 somatic genome rearrangements 18 deletions (31%) 9 tandem duplications (16%) 15 Inverted intrachromosomal rearrangements (26%) 9 non-inverted intrachromosomal rearrangements (16%) 7 interchromosomal rearrangements
Figure 3. • Rearrangements between chromosomes 1 & 4 • Intrachromosomal inversions • Non-inverted intrachromosomal rearrangements • Interchromosomal rearrangements • Not classical inversions: • Clear boundaries separating changes in copy number in genes on both chromosomes • Breakpoints between chromosomes aren't reciprocal • Unbalanced rearrangements
Oncogenic Fusion Genes • Oncogenic Fusion Gene: A hybrid gene formed from two genes previously separated • Chromosomal rearrangements can result in an oncogenic fusion gene if: • 2 genes side by side • Intact ORF • Genes in the same orientation • NCI-H209 • Fusion gene: 240 bp deletion on chromosome 16: • 1st 2 exons of CREBBP • 3' portion of BTBD12 • RT-PCR showed expression of fusion transcript • This wasn't expressed in 55 other SCLS • Direct further studies here????
Figure 4. CHD7 significance • CHD7 codes for a chromatin helicase DNA binding protein • NCI-H209: • 39.5kb tandem duplication of • exons 3-8 of CHD7 (Figure 4a &4c.) • NCI-H2171: • Fusion gene of exons 1-3 of PVT1 (non-coding RNA gene immediately downstream of MYC) & exons 4-38 of CHD7 (Figure 4c.)-MYC amplification • LU-135: • Fusion gene of exon 1 of PVT1 (non-coding RNA gene immediately downstream of MYC) & exons 14-38 of CHD7(Figure 4c.) -MYC amplification • This suggests that CHD7 rearrangements are a regular phenomenon in SCLC