Download

1 / 24
250 likes | 420 Views
UCL Department of Computer Science. A Coherent Grid Traversal Algorithm for Volume Rendering. Ioannis Makris Supervisors: Philipp Slusallek*, C é line Loscos * Computer Graphics Lab , Universität des Saarlandes. UCL Department of Computer Science. Overview. Introduction

E N D
UCL Department of Computer Science A Coherent Grid Traversal Algorithm for Volume Rendering Ioannis Makris Supervisors: Philipp Slusallek*, Céline Loscos *Computer Graphics Lab, Universität des Saarlandes
UCL Department of Computer Science Overview • Introduction • Previous work in software Direct Volume Rendering • Introduction to the Cell Broadband Engine • The Coherent Grid Traversal Algorithm • Parallelisation Schemes
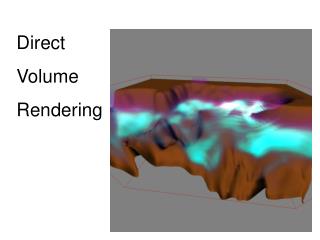
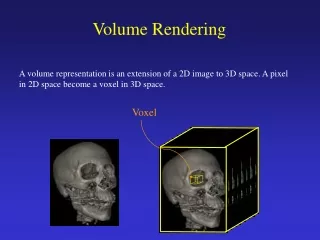
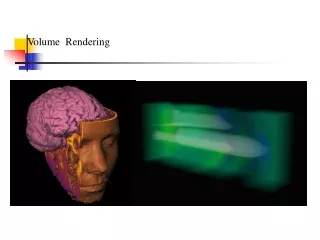
Introduction to Direct Volume Rendering • Technique of displaying a 2D projection of a 3D sampled dataset (volume), by accumulating samples across lines of sight with some transfer function. • Several types of sampled data. We will only deal with rectilinear grids.
UCL Department of Computer Science Direct Volume Rendering • Ray Casting (Levoy 1988, 1990) • Image order algorithm • Splatting (Westover 1990) • Object order • Shear Warp (Lacroute 1994, 1996) • Hybrid order
UCL Department of Computer Science Ray Casting • Cast a ray from the viewpoint to the volume for all pixels • Obtain samples from the volume in equal intervals, by trilinearly interpolating neighbouring voxels. Accumulate with some operator to get final colour. • Several acceleration techniques have been suggested (early ray termination (Levoy 1990), adaptive sampling, octrees (Ogata et al. 1998), kd-trees(Wald et al 2005)
UCL Department of Computer Science Shear-Warp • Considered the fastest known Direct Volume Rendering algorithm. • Steps: • Transform volume to sheared object space • Project sheared slices on an intermediate image • Transform the intermediate image to image space • Requires 3 copies of the data, for every principal axis, but RLE compression can help.
Characteristics of modern x86 processors • Deep instruction pipeline. • Very sophisticated hardware branch prediction • 2 levels of cache, supports software prefetching • Rich SIMD instruction set
UCL Department of Computer Science The CELL processor • Developed jointly by IBM, Sony and Toshiba • Combines a PowerPC general purpose processor with 8 separate SIMD execution units (SPUs). • Exceptional FLOPS / cost ratio and more powerful than the Itanium! • Needs fast memory, which is relatively expensive
UCL Department of Computer Science Notable Characteristics of the SPUs • Software managed local store (i.e. no caches) • No branch prediction, expensive branch misses • SIMD loads/stores ONLY • Favors streaming code
UCL Department of Computer Science Motivation for a new algorithm • Ray Casting algorithms are typically not cache friendly. Performance depends on viewing axis. • Acceleration structures may produce non-streaming code and several overheads. • Shear Warp may require too much memory for certain data.
UCL Department of Computer Science A Coherent Grid Traversal Algorithm for Volume Rendering (1) • Original idea from “Ray Tracing Animated Scenes using Coherent Grid Traversal” (Wald et al, SIGGRAPH 2006). • Bundles (frustums) of coherent rays are traced in grid space, by incrementaly computing the overlap with grid slices. The overlap of the frustum is computed with a SIMD addition and a SIMD truncation only
UCL Department of Computer Science A Coherent Grid Traversal Algorithm for Volume Rendering (2) • The volume rendering version of the algorithm uses a “bricked” volume (Sakas et al 1994), bricks replace the grid elements. • Bricks are referenced by 3 maps, one for each principal axis. • Compression is achieved by not storing empty bricks.
A Coherent Grid Traversal Algorithm for Volume Rendering (3)
UCL Department of Computer Science A Coherent Grid Traversal Algorithm for Volume Rendering (4) • Traversal is performed on the principal axis, using the corresponding map. • Indices are computed incrementally. • If all the overlapping bricks of a slice are empty, the slice is skipped. • If some bricks are empty, they are associated with a locally stored empty brick and processed redundantly (but not fetched).
UCL Department of Computer Science A Coherent Grid Traversal Algorithm for Volume Rendering (examples)
UCL Department of Computer Science Bundle Parallelisation • Bundle Parallelisation is trivial. On a x86 C++ OpenMP implementation, it only required 1 line of code. • It is possible to have some blocks fetched multiple times from neighbouring bundles.
UCL Department of Computer Science Slice Parallelisation • A slice parallelisation is less likely to exhibit this problem, but traversal of brick slices is not incremental! • So, how would the processing element know which bundles to process for a given slice?
UCL Department of Computer Science Slice Parallelisation • Most bundles will start on k=0, or end on k=kmax (or both). • During tracing, we create 2 vectors of references to bundles, we shall call them A and D, along with 2 index tables for the corresponding slices we shall call P and Q. • The bundles that run through a given slice s can be expressed as • Only 2 memory reads are required for that, or no memory reads if the bundles are large enough for A and D to fit in the cache/local store.
UCL Department of Computer Science Slice Parallelisation • Remaining bundles can take up to 33% (they are about 14% average). • We use two more lists, we shall call S and E with index tables M and N. S holds references to the remaining bundles sorted by the first slice they intersect, and E sorted by the last. • Remaining bundles that run through s are: • We need to run through both these lists to find that out, but this does not hit performance.
A notable problem of the CGT algorithm as described in [Wald 2006] • When the “roll” angle of the bundles to the respective angle of the volume is close to π/4, the number of blocks fetches can be double than the number required. • There is a good solution to that (not yet published).
UCL Department of Computer Science Results First results demonstrated an speed increase of up to 2 orders of magnitude from ray-casting. This may increase with further optimisations
Conclusion • We have developed a scalable algorithm for coherent volume traversal with performance on-par with the Shear – Warp, with reduced memory requirements. • We demonstrated parallel implementations.
Future Work • Investigate mixed parallelisation schemes • Optimise the computation performed per brick.
UCL Department of Computer Science The End Thank you for your attention Questions?