Download

1 / 21
210 likes | 331 Views
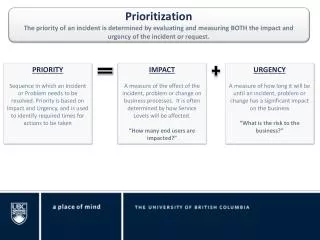
Mining Social Network for Personalized Email Prioritization. Language Techonology Institute School of Computer Science Carnegie Mellon University Shinjae Yoo, Yiming Yang, Frank Lin, and Il-Chul Moon. Outline. Problem Description Approaches Experiments Contributions. Problem Description.

E N D
Mining Social Networkfor Personalized Email Prioritization Language Techonology Institute School of Computer Science Carnegie Mellon University Shinjae Yoo, Yiming Yang, Frank Lin, and Il-Chul Moon
Outline • Problem Description • Approaches • Experiments • Contributions
Problem Description • Email Overload is severe problem • Identifying Importance of email will alleviate email overload • Challenges • No access to other people’s emails and labels • Personalized labeling is time consuming • The same message may have different priority labels for different recipients • We want to leverage the sparse training data by using social network of each user Sparse Training Data
Outline • Problem Description • Approaches • Social Clustering • Social Importance • Semi-supervised Importance Propagation • Experiments • Conclusion and Future Work
Social Clustering – Motivation • Personal Email Inbox • Lots of unlabeled emails • No privacy issue • Observations • The sender can be important • Some senders are not appeared in the training set at all or very few instances • Need generalization of sender Let’s find similar senders from social network
Social Clustering – Contact Network • Personal Contact Network • G =(V,E ) • All the network is constructed from personal inbox Agent /Person 1 2 3 4 5
Social Clustering – Newman Clustering • Newman Clustering Algorithm [Newman, 04] • Find social cliques or cohesive social groups • Based on edge betweeness • The number of shortest path that go through the edge / the total number of shortest path • Drop edges from highest edge betweeness • Hard clustering 9 1 4 4 4 4 4 2 3 5 6 1 1 Group A Group B
Social Clustering– Validations • Clusters are coherent!
Social Clustering – Feature Incorporation • Extended Vector Space • text: social network: • combined: • The combined vector space is used as enriched feature set to the email prioritizer
Social Importance – Motivations • Social Importance • A person in the center of a cluster might be more important than others • Betweeness • Edge betweeness for Newman Clustering • Vertex betweeness • The degree of communication bottleneck from social network • Contact points among the network • Might be important person • We may try other kinds of social importance metrics too
Social Importance – Metrics • Metrics • Degree (in, out, total) [Wasserman and Faust, 94] • Clique Counts (ClqCnt) [Wasserman and Faust, 94] • The number of clique sub-graphs which contain a node v • Betweeness (BetCent) [Freeman, 77] • HITS Authority (Authority) [Kleinberg, 99] • λ: the greatest Eigen value • r : the Eigen vector similar to PageRank scores • Neighborhood Connectivity (“Clustering Coefficient”, ClustCoef) [Boykin and Roychowdhury, 05] • measure the connectivity among the neighbor of a node v
Social Importance – Validations • Correlation coefficients with priority levels
SIP- Motivations Agent /Person ? ? ? ? ? Emails 4 3 2 ? ? • Semi-supervised Importance Propagation (SIP) • Can we propagate importance labels? • Bi-partite graph, Labels only in Emails
SIP- Email Network Agent /Person ? ? ? ? ? Emails A: Sender to Emails (N x M) BT: Email to Recipients (M x N) xk: kth importance labels for emails(M x 1) yk=Bxk(N x 1) 14 4 3 2 ? ?
SIP - Algorithm • Problems of the above propagation • may not be irreducible • is insensitive to (not personalized) • Apply Personalized PageRank with • Normalize and column-wise normalize C :C’
Outline • Problem Description • Approaches • Experiments • Contributions
Experiments – Data Collection • Collected Data • 25 subjects are recruited from Canegie Mellon University • 7 users who submitted more than 200 emails • 1 faculty, 2 staffs, 4 students Training Testing time
Experiments – Metrics • Mean Absolute Error (MAE) • 1.0 MAE means on average the prediction is deviated from the truth by one priority level • MAE considers the difference among the errors • It ranges from 0 to 4 when we use five importance level • 1 vs. 5 and 4 vs. 5 • Micro-MAE • Pooling the test instances from all users to obtain a joint test set • Macro-MAE • Compute each user MAE first and then take the average of per-user MAE
Experiments – Setups • Features : four subsets • Basic Feature (BF) : from, to, cc, title, body • Newman Clustering (NC) • Social Importance (SI) • Semi-supervised Importance Propagation (SIP) • Ten times random shuffling among training data • Linear SVM • 10 Fold C.V. for parameter tuning • Tuned regularization parameter [10-3.. 103]
Contributions • The first study on personalized email prioritization • Using statistical classification and clustering • Based on fine-grained personal judgments with multiple users • Enriched representation through personal Social Network • Social Clustering • Social Importance Estimation • Semi-supervised Importance Propagation • Fully personalized methodology • Technical development and Evaluation





![21 Recipes for Mining Twitter [Social Network Analysis ]](https://cdn1.slideserve.com/1620481/21-recipes-for-mining-twitter-social-network-analysis-dt.jpg)