Download
1 / 66
790 likes | 1.22k Views
Interfacing Processor and Peripherals. Overview. Introduction. I/O often viewed as second class to processor design Processor research is cleaner System performance given in terms of processor Courses often ignore peripherals Writing device drivers is not fun

E N D
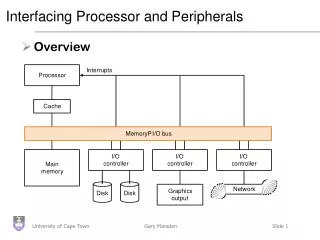
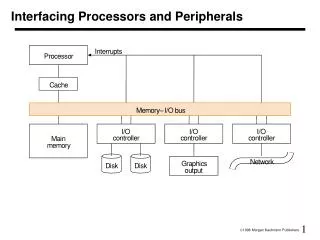
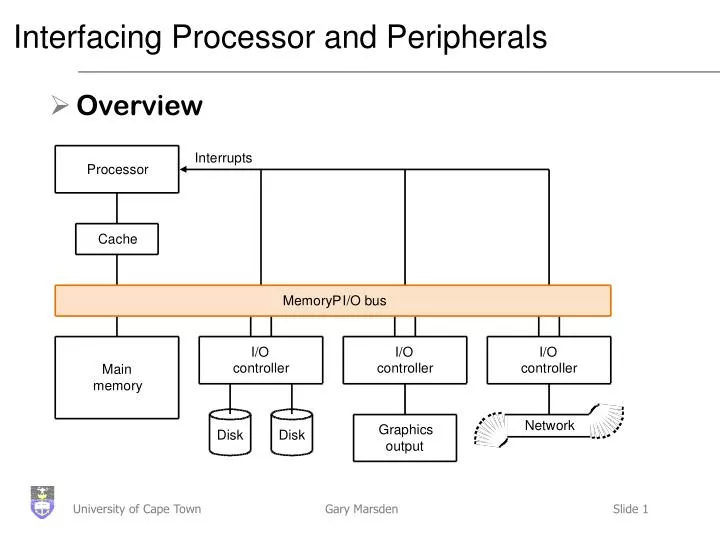
Interfacing Processor and Peripherals • Overview
Introduction • I/O often viewed as second class to processor design • Processor research is cleaner • System performance given in terms of processor • Courses often ignore peripherals • Writing device drivers is not fun • This is crazy - a computer with no I/O is pointless
Peripheral design • As with processors, characteristics of I/O driven by technology advances • E.g. properties of disk drives affect how they should be connected to the processor • PCs and super computers now share the same architectures, so I/O can make all the difference • Different requirements from processors • Performance • Expandability • Resilience
Peripheral performance • Harder to measure than for the processor • Device characteristics • Latency / Throughput • Connection between system and device • Memory hierarchy • Operating System • Assume 100 secs to execute a benchmark • 90 secs CPU and 10 secs I/O • If processors get 50% faster per year for the next 5 years, what is the impacr
Relative performance • CPU time + IO time = total time (% of IO time) • Year 0: 90 + 10 = 100 (10%) • Year 1: 60 + 10 = 70 (14%) • : • Year 5: 12 + 10 = 22 (45%) • !
IO bandwidth • Measured in 2 ways depending on application • How much data can we move through the system in a given time • Important for supercomputers with large amounts of data for, say, weather prediction • How many IO operations can we do in a given time • ATM is small amount of data but need to be handled rapidly • So comparison is hard. Generally • Response time lowered by handling early • Throughput increased by handling multiple requests together
I/O Performance Measures • Look at some examples from the world of disks: all sorts of factors and uses • Different examples of performance benchmarks for different applications: • Supercomputers • I/O dominated by access to large files • Batch jobs of several hours • Large read followed by many writes (snapshots in case process fails) • Main measure: throughput
More Measures • Transaction processing (TP) • TP Involves both a response time requirement and a level of throughput performance • Most accesses are small, so chiefly concerned with I/O rate (# disk accesses / second) as opposed to data rate (bytes of data per second) • Usually related to databases: graceful failure required, and reliability essential • Benchmark: TPC-C • 128 pages long • Measures T/s • Includes other system elements (e.g. terminals)
File system I/O benchmarks • File systems stored on disk have different access patterns (each OS stores files differently) • Can ‘profile’ accesses to create synthetic file system benchmarks • E.g. for unix in an engineering environment: • 80% of accesses to files < 100k • 90% of accesses to sequential addresses • 67% reads • 27% writes • 6% read-modify-write
Typical File benchmark • 5 phases using 70 files, totalling 200k • Make dir • Copy • Scan Dir (recursive for all attributes) • Read all • Make
Device Types and characteristics • Key characteristics • Behaviour: Input / Output / Storage (read & write) • Partner: Human / Machine • Data rate: Peak data transfer rate
Mouse • Communicates with • Pulses from LED • Increment / decrement counters • Mice have at least 1 button • Need click and hold • Movement is smooth, slower than processor • Polling • No submarining • Software configuration
Hard disk • Rotating rigid platters with magnetic surfaces • Data read/written via head on armature • Think record player • Storage is non-volatile • Surface divided into tracks • Several thousand concentric circles • Track divided in sectors • 128 or so sectors per track
Access time • Three parts • Perform a seek to position arm over correct track • Wait until desired sector passes under head. Called rotational latency or delay • Transfer time to read information off disk • Usually a sector at a time at 2~4 Mb / sec • Control is handled by a disk controller, which can add its own delays.
Calculating time • Seek time: • Measure max and divide by two • More formally: (sum of all possible seeks)/number of possible seeks • Latency time: • Average of complete spin • 0.5 rotations / spin speed (3600~5400 rpm) • 0.5/ 3600 / 60 • 0.00083 secs • 8.3 ms
More faking • Disk drive hides internal optimisations from external world
Networks • Currently very important • Factors • Distance: 0.01m to 10 000 km • Speed: 0.001 Mb/sec to 1Gb/sec • Topology: Bus, ring, star, tree • Shared lines: None (point to point) or shared (multidrop)
Example 1: RS-232 • For very simple terminal networks • From olden times when 80x24 text terminals connected to mainframes over dedicated lines • 0.3 to 19.2 Kbps • Point to point, star • 10 to 100m
Example 2: Ethernet LAN • 10 - 100 Mbps • One wire bus with no central control • Multiple masters • Only one sender at a time which limits bandwidth but ok as utilisation is low • Messages or packets are sent in blocks of 64 bytes (0.1 ms to send) to 1518 bytes (1.5 ms) • Listen, start, collision detection, backoff
Example 3: WAN ARPANET • 10 to n thousand km • ARPANET first and most famous WAN (56 Kbps) • Point to point dedicated lines • Host computer communicated with interface message processor (IMP) • IMPs used the phone lines to communicate • IMPs packetised messages into 1Kbit chunks • Packet switched delivery (store and forward) • Packets reassembled at receiving IMP
Some thoughts • Currently 100 Mbps over copper is common and we have Gbps technology in place • This is fast! • We need systems than process data as quickly as it arrives • Hard to know where the bottlenecks lie • Network at UCT has / will have Gigabit backplane • Our international connection is only 10 Mbps
Buses: Connecting I/O devices • Interfacing subsystems in a computer system is commonly done with a bus: “a shared communication link, which uses one set of wires to connect multiple sub-systems”
Why a bus? • Main benefits: • Versatility: new devices easily added • Low cost: reusing a single set of wires many ways • Problems: • Creates a bottleneck • Tries to be all things to all subsystems • Comprised of • Control lines: signal requests, acknowledgements and to show what type of information is on the • Data lines:data, destination / source address
Controlling a bus • As the bus is shared, need a protocol to manage usage • Bus transaction consists of • Sending the address • Sending / receiving the data • Note than in buses, we talk about what the bus does to memory • During a read, a bus will ‘receive’ data
Types of Bus • Processor-memory bus • Short and high speed • Matched to memory system (usually Proprietary) • I/O buses • Lengthy, • Connected to a wide range of devices • Usually connected to the processor using 1 or 3 • Backplane bus • Processors, memory and devices on single bus • Has to balance proc-memory with I/O-memory • Usually requires extra logic to do this
Synchronous and Asynchronous buses • Synchronous bus has a clock attached to the control lines and a fixed protocol for communicating that is relative to the pulse • Advantages • Easy to implement (CC1 read, CC5 return value) • Requires little logic (FSM to specify) • Disadvantages • All devices must run at same rate • If fast, cannot be long due to clock skew • Most proc-mem buses are clocked
Asynchronous buses • No clock, so it can accommodate a variety of devices (no clock = no skew) • Needs a handshaking protocol to coordinate different devices • Agreed steps to progress through by sender and receiver • Harder to implement - needs more control lines
Increasing bus bandwidth • Key factors • Data bus width: Wider = fewer cycles for transfer • Separate vs Multiplexed, data and address lines • Separating allows transfer in one bus cycle • Block transfer: Transfer multiple blocks of data in consecutive cycles without resending addresses and control signals etc.
Obtaining bus access • Need one, or more, bus masters to prevent chaos • Processor is always a bus master as it needs to access memory • Memory is always a slave • Simplest system as a single master (CPU) • Problems • Every transfer needs CPU time • As peripherals become smarter, this is a waste of time • But, multiple masters can cause problems
Bus Arbitration • Deciding which master gets to go next • Master issues ‘bus request’ and awaits ‘granted’ • Two key properties • Bus priority (highest first) • Bus fairness (even the lowest get a go, eventually) • Arbitration is an overhead, so good to reduce it • Dedicated lines, grant lines, release lines etc.
Different arbitration schemes • Daisy chain: Bus grant line runs through devices from highest to lowest • Very simple, but cannot guarantee fairness
Centralised Arbitration • Centralised, parallel: All devices have separate connections to the bus arbiter • This is how the PCI backplane bus works (found in most PCs) • Can guarantee fairness • Arbiter can become congested
Distributed • Distributed arbitration by self selection: • Each device contains information about relative importance • A device places its ID on the bus when it wants access • If there is a conflict, the lower priority devices back down • Requires separate lines and complex devices • Used on the Macintosh II series (NuBus)
Collision detection • Distributed arbitration by collision detection: • Basically ethernet • Everyone tries to grab the bus at once • If there is a ‘collision’ everyone backs off a random amount of time
Bus standards • To ensure machine expansion and peripheral re-use, there are various standard buses • IBM PC-AT bus (de-facto standard) • SCSI (needs controller) • PCI (Started as Intel, now IEEE) • Ethernet • Bus bandwidth depends on size of transfer and memory speed
Giving commands to I/O devices • Processor must be able to address a device • Memory mapping: portions of memory are allocated to a device (Base address on a PC) • Different addresses in the space mean different things • Could be a read, write or device status address • Special instructions: Machine code for specific devices • Not a good idea generally
Communicating with the Processor • Polling • Process of periodically checking the status bits to see if it is time for the next I/O operation • Simplest way for device to communicate (via a shared status register • Mouse • Wasteful of processor time
Interrupts • Notify processor when a device needs attention (IRQ lines on a PC) • Just like exceptions, except for • Interrupt is asynchronous with program execution • Control unit only checks I/O interrupt at the start of each instruction execution • Need further information, such as the identity of the device that caused the interrupt and its priority • Remember the Cause Register?
Transferring Data Between Device and Memory • We can do this with Interrupts and Polling • Works best with low bandwidth devices and keeping cost of controller and interface • Burden lies with the processor • For high bandwidth devices, we don’t want the processor worrying about every single block • Need a scheme for high bandwidth autonomous transfers
Direct Memory Access (DMA) • Mechanism for offloading the processor and having the device controller transfer data directly • Still uses interrupt mechanism, but only to communicate completion of transfer or error • Requires dedicated controller to conduct the transfer