Download

1 / 30
300 likes | 319 Views
Relational Cloud. 桑成良 2011.5.10. 相关文章. Carlo Curino, Evan Jones, Yang Zhang, Eugene Wu, Samuel Madden. Relational Cloud: The Case for a Database Service . NEDB 2010

E N D
Relational Cloud 桑成良 2011.5.10
相关文章 • Carlo Curino, Evan Jones, Yang Zhang, Eugene Wu, Samuel Madden. Relational Cloud: The Case for a Database Service. NEDB 2010 • C. Curino, E. Jones, Y. Zhang, and S. Madden. Schism: A Workload-Driven Approach to Database Replication and Partitioning.In VLDB, 2010 • Carlo Curino,Evan P. C. Jones,Raluca Ada Popa,Nirmesh Malviya. Relational Cloud: A Database-as-a-Service for the Cloud.In CIDR 2011.
author • MIT Computer Science and Artifical Intelligence lab, Database Group • Postdoc • Ph.D • Faculty
(1)Background, introduction • (2)Graph-based partitioning • (3)Workload placement • (4)Privacy • (5)Experiment
1.Background and introduction • a story of DB drama:
HW resources are under utilized: • peak-provisioning • HW for infrequent tasks • low power-efficiency • Same problems solved over and over: • hw/sw selection • configuration and tuning • scalability and load balancing • Existing Commercial DB Services: • Amazon RDS, SQL Azure (and many others) • What they got right: • simplified provisioning/deployment • reduced administration/tuning headaches What is still missing?
Key Features : • Efficient muti-tenancy: • Workload placement • Elastic scalability • Automic partitioning • Live migration • Privacy • run SQL over encrypted data Not mix data of two different tenants into a common database or table!
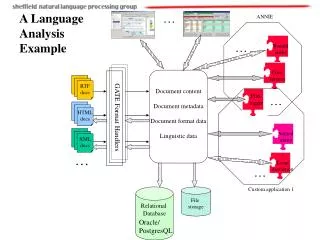
Client nodes • Special driver,encrypt,decrypt • Frontend nodes • Monitor access patterns,load on the server • Analyses SQL,execution nodes and plan • Coudinates muti-node transactions • Provides a degree of performance isolation • Backend nodes • Unmodified DBMS • CryptDB • Placement and migration engine • Monitors statistics.db server,os,hardware • Use historic statistics to predicate • Live migration ,under implementation • Partitioning engine • partitioning
2.Partitioning • Distributed transaction is expensive KEY TO SCALABILITY (OLTP/Web): • Limit percentage of distributed transaction
Graph-based partitioning Make best choice Graph partitioning (METIS) Classification (Decision tree) Input (logs+processing)
Optimization • Transaction sampling • Tuple level sampling • Blanket-statement filtering • Relevance filtering • Star shape replication • Tuple-coalescing • Partitioning results→lookup table
Explanation phase • (range-prediacte partitioning) • Decision tree • Creationg a training set(extracts queries and tuples) • Attribute selection(parse statement) • Build the classifier (c4.5) • Get rules • (id=1) →partitions={0,1} • (2<=id<4) →partition={0} • (id>=4) →partition={1} • No rules→lookup table
Final validation • Per tuple partitioning • Range-predicate partitioning • Hash partitioning • Full table replication • Number of distribute transaction • Complexity
3.Workload placement • The way we advocate • A single database server on each machine,hosts mutiple logical databases • Periodically determines which db shoud be placed on which machine(a non-liner opertimization formulation,a cost model) • A light weight mechanism(live migration) • Each instance a VM • 2*,3* more machine • 6*,12*less performance
Our monitoring and consolidation engine: Kairos • 1.resource monitor(statistics collection process) • 2.combined load predictor • 30*better than simply disk I/O • 3.consolidation engine • Min the num of machine for a given workload mix • Balance load across back end machines
Objective function • Min server(use SIGNUM) • Max balance(use EXP)
Live migration • (1)improve native strategy • Partitioning the data to be moved into a number of small partitions,incrementally migrating these smaller partitions. • Migrating an exsiting snapshot/checkpoint and selectively rolling-forward logs. • Exploiting existing replicas to serve read-only queries during migration • Prefetching of data to prepare warm stand-by copies. • (2)our strategy • New processing node added,immediately start routing transactons to it. • New node fetches data needed from the old node, caches them in its local storage,and processes reads and writes locally
4.Privacy • Several approachs • RND(randomized encryption) • DET(deterministic encryption) • OPE(order-preserving encryption) • HOM(homomorphic encryption) • Adjustable security
CryptDB • Encrypts all data items in a column using same set of keys. • Encryption algorithms are symmetric. • The server receive the symmetric onion key from JDBC client
What’s next? • Live Migration • Dynamic reallocation/repartitioning
5.Experiments • Efficient muti-tenancy
Conclusion • We can use for reference • Graph-based partitioning? • Combined placement model; • Onion privacy? • Live migration