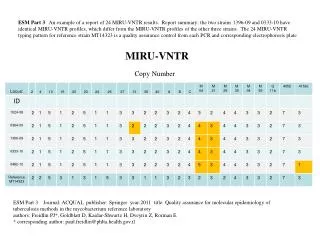
Download

1 / 18
180 likes | 383 Views
EFFICIENT ALGORITHM FOR COPY NUMBER VARIATION RECONSTRUCTION. CS224 Project Dan He. CNV (COPY NUMBER VARIATION). One type of SV (Structural Variation). Reference. Donner. RE-SEQUENCING USING SHORT READS. Donner. COVERAGE RATIO.

E N D
EFFICIENT ALGORITHM FOR COPY NUMBER VARIATION RECONSTRUCTION CS224 Project Dan He
CNV (COPY NUMBER VARIATION) • One type of SV (Structural Variation) Reference Donner
COVERAGE RATIO • Coverage Ratio indicates the region of the copies and the number of the copies Coverage Ratio Reference Donner
CNV RE-CONSTRUCTION • Input: Reference sequence, Set of paired-end reads randomly sampled from donner sequence, Coverage ratio. • Output: Donner sequence such that (1) The number of CNV is consistent with the coverage ratio (2) The number of mismatches between the set of paired-end reads and the donner sequence is minimized.
STEP 1 • Select Un-Mapped reads Reference Donner
STEP 2 • Find junctions between copies using Un-Mapped Reads: (1) split the Un-Mapped Read into 2 parts at each internal position of the Read.(2) match both parts to the reference sequence. If both parts match the reference sequence, record the matched positions. start end Reference Donner junction
STEP 3 • Order the junctions such that the donner sequence is valid, when you have more than 2 copies and the copies are of difference length.
A SIMPLE EXAMPLE • Set length threshold for the two parts of the split reads such that the matches are “significant”, namely not happen by random chance. • Given reference sequence length L, the threshold can be computed by selecting a n such that L/4^n (number of expected occurrence for a length n string in the reference) is very small, say, less than 0.001. Reference ACTGGTCACTGTCGATC Donner ACTGGTCACTGTCGCTGTCGCTGTCGATC Un-Mapped Reads TCGCTCGCTG
A MORE COMPLICATED EXAMPLE • 3 copies with various lengths Reference ACTGGTCACTGTCGATC Donner ACTGGTCACTGTCGTGTCGCTGTCATC Un-Mapped Reads TCGTGCGCTGTCATC
EFFICIENT IMPLEMENTATIONS • Suffix Tree on the reference sequence such that search for match positions will be much faster. • Search Tree for the un-mapped reads such that redundant comparisons can be avoided.
DIFFICULTIES IN REAL APPLICATIONS • Reads contain errors • Copies can contain heterozygous SNPs • Distinguish repeats regions from CNV region • CNV may occur together with other SVs
ERRORS ALLOWED IN THE READS • Still the same steps but allow mismatches when map the split parts of reads to the reference sequence. • The number of candidate matched positions increases as the number of allowed mismatches increases. • Apply clustering on the candidate matched positions such that positions adjacent to each other are clustered into one group. The groups with maximal sizes are selected.
EXPERIMENTAL RESULTS • Reference sequence length: 1000 • CNV length: around 100 • Length threshold for significant match: 10 • Reads length: 36 • Compare cases for 3 copies and 4 copies, with allowed errors as 0, 1, 2, respectively • Simulate reference sequence, CNV and reads using Nick’s simulator