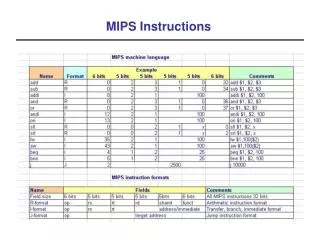
Download

1 / 102
1.03k likes | 1.18k Views
Processador MIPS. Datapath e Unidade de Controle. Datapath Componente do processador que realiza operações aritméticas Unidade de Controle Componente do processador que comanda o datapath, memória e dispositivos de E/S de acodo com as instruções de um programa.

E N D
Processador MIPS Datapath e Unidade de Controle
Datapath • Componente do processador que realiza operações aritméticas • Unidade de Controle • Componente do processador que comanda o datapath, memória e dispositivos de E/S de acodo com as instruções de um programa
Etapas para execução de uma instrução • Independente da classe da instrução, as duas primeiras etapas para sua execução são as mesmas: • Enviar o PC para a memória e buscar a instrução. • Ler um ou dois registradores (usando o campo da instrução para selecionar os registradores a serem lidos) • Os passos seguintes dependem da classe da instrução (referência à memória, lógica-aritmética e desvios) • alguns destes passos são bastantes semelhantes e independem do opcode
Por exemplo, todas as instruções, independente da classe utilizam a ALU após a leitura de um registrador. • Instrução de referência à memória: utiliza para cálculo do endereço • Instruções lógica-aritméticas: utiliza para execução • Instruções de desvios: utiliza para comparação. • Após a utilização da ALU, os passos são diferentes para as diferentes classes.
D a t a R e g i s t e r # A d d r e s s P C I n s t r u c t i o n R e g i s t e r s A L U A d d r e s s R e g i s t e r # I n s t r u c t i o n D a t a m e m o r y m e m o r y R e g i s t e r # D a t a Implementação do MIPS – visão em alto nível
Revisão/Convenções adotadas • Sinal lógico alto – ativado • Elementos combinacionais, exemplo: ALU • Elementos de estado, exemplo: Registradores e Memória • Sinal de Clock: usado para determinar quando se pode escrever em um elemento de estado. A leitura pode ser a qualquer momento
S t a t e S t a t e e l e m e n t C o m b i n a t i o n a l l o g i c e l e m e n t 1 2 C l o c k c y c l e • Metodologia de sincronização • sincroniza o elemento de estado para a permissão de leitura e de escrita (Por que é necessário?) · Lógica combinacional, elemento de estados e clock (sensível à subida).
S t a t e C o m b i n a t i o n a l l o g i c e l e m e n t A metodologia edge-triggered permite a um elemento de estado ler e escrever no mesmo período de clock.
Datapath • OBS.: Primeiro implementaremos um Datapath utilizando apenas um clock com ciclo grande. Cada instrução começa a ser executada em uma transição e acaba na próxima transição do clock (na prática isto não é factível, pois temos instruções de diferentes classes e portanto de diferentes números de ciclos de clock) • Recursos em um Datapath: • Um lugar para armazenar as instruções do programa (Memória de instruções) • Um lugar para armazenar o endereço da instrução a ser lida na memória (Program Counter - PC) • Somador para incrementar o PC para que ele aponte para a próxima instrução
I n s t r u c t i o n a d d r e s s P C I n s t r u c t i o n A d d S u m I n s t r u c t i o n m e m o r y a . I n s t r u c t i o n m e m o r y b . P r o g r a m c o u n t e r c . A d d e r Elementos necessários a armazenar e acessar informações mais um somador para calcular o endereço do próximo estado.
Instruções R-type • Instruções aritméticas e lógicas:add, sub, slt • 32 registradores chamado de register file, que é um conjunto de registradores que podem ser acessados (lidos ou escritos) especificando seu número. • Instruções de formato R tem 3 operandos registradores (add $t1,$t2,$t3): necessidade de ler 2 dados do register file e escrever um dado nele, para cada instrução • Para ler um dado do register file é preciso de uma entrada (número do registrador) e uma saída (o dado lido) • Para escrever um dado no register file, são necessárias duas entradas: o número do registrador e o dado a ser escrito • Para escrever: sinal de controle (RegWrite) • A ALU é controlada por um sinal de controle (ALU control)
A L U c o n t r o l 5 3 R e a d r e g i s t e r 1 R e a d d a t a 1 5 R e g i s t e r R e a d Z e r o r e g i s t e r 2 n u m b e r s R e g i s t e r s D a t a A L U A L U 5 W r i t e r e s u l t r e g i s t e r R e a d d a t a 2 W r i t e D a t a d a t a R e g W r i t e a . R e g i s t e r s b . A L U Elementos necessários para a implementação de operações na ALU: instruções do tipo-R.
A L U o p e r a t i o 3 R e a d r e g i s t e r 1 R e a d d a t a 1 R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n R e g i s t e r s A L U A L U W r i t e r e s u l t r e g i s t e r R e a d d a t a 2 W r i t e d a t a R e g W r i t e O datapath para instruções do tipo R n
Instruções LOAD e STORE • lw $t1,offset_value($t2) e sw $t1,offset_value,($t2) • Endereço de memória = value_offset + $t2 • Value_offset: offset sinalizado de 16 bits • É preciso um register file e uma ALU • Unidade que transforme valor de 16 bits sinalizado em um valor de 32 bits • Unidade de memória de dados com controle de leitura (MemRead) e escrita (MemWrite)
M e m W r i t e R e a d A d d r e s s d a t a 1 6 3 2 S i g n e x t e n d D a t a W r i t e m e m o r y d a t a M e m R e a d a . D a t a m e m o r y u n i t b . S i g n - e x t e n s i o n u n i t Unidades para implementação de lw e sw
Instrução beq e jump • beq $t1,$t2,offset: 2 registradores que são comparados e um offset de 16 bits usado para calcular o endereço relativo, alvo do branch • A base para o cálculo do endereço alvo de branch é o endereço da próxima instrução em relação à instrução branch • O campo offset é deslocado de 2 bits para aumentar o alcance do desvio (multiplicado por 4) • Além do cálculo do endereço do branch, deve-se determinar qual endereço será escolhido, o do branch (taken) ou o armazenado em PC (not taken) dependendo do resultado da comparação • OBS.: Instrução jump: os 28 bits menos significativos de PC são substituídos pelos 26 bits do imediato, deslocado de 2 bits ( X 4 ).
P C + 4 f r o m i n s t r u c t i o n d a t a p a t h A d d S u m B r a n c h t a r g e t S h i f t l e f t 2 A L U o p e r a t i o n 3 R e a d r e g i s t e r 1 I n s t r u c t i o n R e a d d a t a 1 R e a d r e g i s t e r 2 T o b r a n c h R e g i s t e r s A L U Z e r o c o n t r o l l o g i c W r i t e r e g i s t e r R e a d d a t a 2 W r i t e d a t a R e g W r i t e 1 6 3 2 S i g n e x t e n d Datapath para branchs
A L U o p e r a t i o n 3 R e a d r e g i s t e r 1 M e m W r i t e R e a d d a t a 1 M e m t o R e g R e a d A L U S r c Z e r o r e g i s t e r 2 I n s t r u c t i o n R e g i s t e r s A L U R e a d A L U R e a d W r i t e d a t a 2 A d d r e s s r e s u l t d a t a r e g i s t e r M M u u W r i t e x D a t a x d a t a m e m o r y W r i t e R e g W r i t e d a t a 1 6 3 2 S i g n M e m R e a d e x t e n d Datapath geral - Instruções de memória + instruções R-type (instruções da ALU)
A d d 4 R e g i s t e r s R e a d A L U o p e r a t i o n 3 M e m W r i t e r e g i s t e r 1 R e a d P C R e a d M e m t o R e g R e a d a d d r e s s d a t a 1 r e g i s t e r 2 A L U S r c Z e r o I n s t r u c t i o n A L U R e a d A L U R e a d W r i t e A d d r e s s r e s u l t d a t a 2 r e g i s t e r d a t a M M u I n s t r u c t i o n u W r i t e x D a t a x m e m o r y d a t a m e m o r y W r i t e R e g W r i t e d a t a 1 6 3 2 S i g n M e m R e a d e x t e n d Fetch da instrução + execução de instruções de memória e da ALU
P C S r c M A d d u x A L U A d d 4 r e s u l t S h i f t l e f t 2 R e g i s t e r s A L U o p e r a t i o n 3 R e a d M e m W r i t e A L U S r c R e a d r e g i s t e r 1 P C R e a d a d d r e s s R e a d M e m t o R e g d a t a 1 Z e r o r e g i s t e r 2 I n s t r u c t i o n A L U A L U R e a d W r i t e R e a d A d d r e s s r e s u l t M d a t a r e g i s t e r d a t a 2 M u I n s t r u c t i o n u x W r i t e m e m o r y D a t a x d a t a m e m o r y W r i t e R e g W r i t e d a t a 3 2 1 6 S i g n M e m R e a d e x t e n d Datapath para as classes de instruções do MIPS
Projeto da Unidade de Controle Principal Classes de instruções - tipo-R, load, store e branch)
Campo opcode: bits 31-26 • Dois registradores a serem lidos rs e rt: bits 25-21 e 20-16 • Registrador base (load e store): bits 15-0 • O valor a ser guardado no PC que pode vir do cálculo de um endereço de salto ou simplesmente do PC + 4. • O registrador destino (a ser escrito), que deverá ser selecionado dentre 2 opções, o que requer um multiplexador: • para um load: bits 20-16 (rt) • para instruções R-type: bits 15-11 (rd) • O valor guardado no banco de registradores que pode vir da ALU (R-type) ou da memória (sw)
P C S r c 1 M A d d u x A L U 0 4 A d d r e s u l t S h i f t R e g W r i t e l e f t 2 I n s t r u c t i o n [ 2 5 – 2 1 ] R e a d r e g i s t e r 1 R e a d M e m W r i t e R e a d P C d a t a 1 I n s t r u c t i o n [ 2 0 – 1 6 ] a d d r e s s R e a d M e m t o R e g A L U S r c r e g i s t e r 2 Z e r o I n s t r u c t i o n R e a d A L U 1 [ 3 1 – 0 ] A L U R e a d W r i t e 1 d a t a 2 1 A d d r e s s r e s u l t M r e g i s t e r d a t a M M I n s t r u c t i o n u u I n s t r u c t i o n [ 1 5 – 1 1 ] W r i t e u x m e m o r y x R e g i s t e r s x d a t a 0 0 D a t a 0 W r i t e m e m o r y R e g D s t d a t a 1 6 3 2 S i g n I n s t r u c t i o n [ 1 5 – 0 ] e x t e n d M e m R e a d A L U c o n t r o l I n s t r u c t i o n [ 5 – 0 ] A L U O p Datapath com os multiplexadores necessários
0 M u x A L U A d d 1 r e s u l t A d d S h i f t P C S r c l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e A d d r e s s M d a t a 2 r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 1 1 ] W r i t e x D a t a 1 x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 0 ] Datapath com a Unidade de Controle
Operação do Datapath • instrução R-type add $t1,$t2,$t3 • fetch da instrução • leitura de $t2 e $t3 • operação na ALU com os dados lidos • resultado da ALU escrito em $t1
0 M u x A L U A d d 1 r e s u l t A d d S h i f t l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 – 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 – 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 – 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e M d a t a 2 A d d r e s s r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 – 1 1 ] W r i t e x 1 D a t a x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 – 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 – 0 ] Fetch e incremento de PC – instrução R-TYPE
0 M u x A L U A d d 1 r e s u l t A d d S h i f t l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 – 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 – 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 – 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e M d a t a 2 A d d r e s s r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 – 1 1 ] W r i t e x D a t a 1 x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 – 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 – 0 ] Leitura dos registradores e decodificação – instrução R-TYPE
0 M u x A L U A d d 1 r e s u l t A d d S h i f t l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] R e a d 0 W r i t e M d a t a 2 A d d r e s s r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 1 1 ] W r i t e x 1 D a t a x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 0 ] Operação na ALU – instrução R-TYPE
0 M u x A L U A d d 1 r e s u l t A d d S h i f t l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e M d a t a 2 A d d r e s s r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 1 1 ] W r i t e x 1 D a t a x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 0 ] Escrita no registrador – instrução R-TYPE
Instrução load word • lw $t1, offset($t2) • Instruction Fetch • $t2 é lido • ALU calcula a soma do valor lido e o imediato de 16 bits • O resultado é usado como endereço da memória de dados • O dado da memória de dados é escrito no register file
0 M u x A L U A d d 1 r e s u l t A d d S h i f t l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 – 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 – 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 – 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e A d d r e s s M d a t a 2 r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 – 1 1 ] W r i t e x D a t a 1 x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 – 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 – 0 ] Operação de um lw com um esquema simples de controle
Instrução branch • beq $t1,$t2,offset • Fetch da instrução • $t1 e $t2 são lidos • ALU faz subtração dos valores lidos. PC+4 é adicionado ao imediato de 16 bits, deslocado de 2 bits resultado é o endereço do desvio • A saída Zero é usada para decidir qual endereço será armazenado em PC
0 M u x A L U A d d 1 r e s u l t A d d S h i f t l e f t 2 R e g D s t 4 B r a n c h M e m R e a d M e m t o R e g I n s t r u c t i o n [ 3 1 – 2 6 ] C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 – 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 – 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e M d a t a 2 A d d r e s s r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 – 1 1 ] W r i t e x D a t a 1 x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 – 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 – 0 ] Datapath para a instrução beq
Instrução jump • J L1 • Fetch da instrução • PC é formado pelos 4 bits mais significativos + 26 bits do imediato + 00 (deslocamento de 2)
J u m p a d d r e s s [ 3 1 – 0 ] I n s t r u c t i o n [ 2 5 – 0 ] S h i f t l e f t 2 2 6 2 8 0 1 M M P C + 4 [ 3 1 – 2 8 ] u u x x A L U A d d 1 0 r e s u l t A d d S h i f t R e g D s t l e f t 2 J u m p 4 B r a n c h M e m R e a d I n s t r u c t i o n [ 3 1 – 2 6 ] M e m t o R e g C o n t r o l A L U O p M e m W r i t e A L U S r c R e g W r i t e I n s t r u c t i o n [ 2 5 – 2 1 ] R e a d R e a d r e g i s t e r 1 P C R e a d a d d r e s s d a t a 1 I n s t r u c t i o n [ 2 0 – 1 6 ] R e a d Z e r o r e g i s t e r 2 I n s t r u c t i o n 0 R e g i s t e r s A L U R e a d A L U [ 3 1 – 0 ] 0 R e a d W r i t e M d a t a 2 A d d r e s s r e s u l t 1 d a t a I n s t r u c t i o n r e g i s t e r M u M u m e m o r y x u I n s t r u c t i o n [ 1 5 – 1 1 ] W r i t e x 1 D a t a x d a t a 1 m e m o r y 0 W r i t e d a t a 1 6 3 2 I n s t r u c t i o n [ 1 5 – 0 ] S i g n e x t e n d A L U c o n t r o l I n s t r u c t i o n [ 5 – 0 ] Datapath para instrução jump
Implementação em um ciclo de clock (não usada) • Funciona corretamente mas não é eficiente • Para single-cycle o ciclo do clock deve ter o mesmo comprimento para todas as instruções CPI = 1 para isto, o ciclo de clock é determinado pelo maior caminho no datapath da máquina ( instrução de load que usa 5 unidades funcionais em série: instruction memory, register file, ALU, data memory e register file)
Exemplo 1: • Sejam os seguintes tempos de operação: • unidade de memória : 2 ns • ALU e somadores: 2ns • register file (read ou write) : 1 ns • unidade de controle, multiplexadores, acesso ao PC, circuito para extensão do sinal e linhas não tem atraso, quais das seguintes implementações seria mais rápida e quanto ?
Exemplo 1: • Uma implementação na qual cada instrução opera em um ciclo de clock de tamanho fixo • Uma implementação onde cada instrução é executada usando clock de tamanho de ciclo variável (exatamente do tamanho necessário para a execução da respectiva instrução também não utilizado na prática) • OBS.: Para comparar o desempenho, assuma a execução de um programa com a seguinte distribuição de instruções : 24% de loads, 12% de store, 44% instruções tipo R, 18% de branches e 2% de jumps.
Exemplo 1: • Solução: • tempo de execução CPU = número de instruções X CPI X período do clock • CPI = 1 • tempo de execução CPU = número de instruções X período do clock • Temos que encontrar o período do clock para as duas implementações, pois o número de instruções e a CPI são iguais para ambas implementações.
Exemplo 2: • FP unit 8ns para add e 16ns para mul • todos os loads tem o mesmo tempo e são 33% das instruções (8 ns) • todos os stores tem mesmo tempo e são 21% das instruções (7 ns) • instruções tipo R são 27 % das instruções (6 ns) • Branches são 5 % (5 ns) e jumps 2% das instruções (2 ns) • FP add e sub tem o mesmo tempo e juntos tem 7% das instruções (12 ns) • FP mul e div tem o mesmo tempo e são 5% das instruções (20 ns)