Download
1 / 37
370 likes | 598 Views
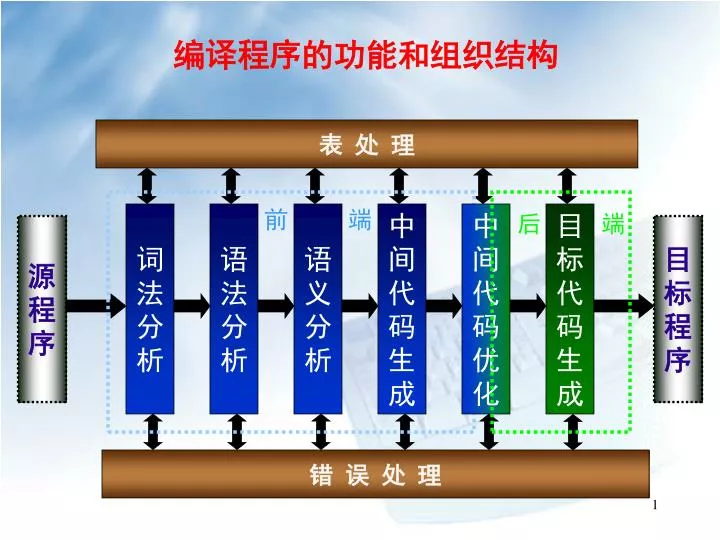
编译程序的功能和组织结构. 表 处 理. 前 端. 词 法 分 析. 语 法 分 析. 语 义 分 析. 中 间 代 码 生 成. 中 间 代 码 优 化. 后 端. 目 标 代 码 生 成. 源 程 序. 目 标 程 序. 错 误 处 理. 第六章 语义分析及中间代码生成. 6.1 语义分析概况 6.2 语法制导翻译的概述 6.3 中间代码的形式. 6.1 语义分析概况. 语义分析在编译程序中的位置

E N D
编译程序的功能和组织结构 表 处 理 前 端 词 法 分 析 语 法 分 析 语 义 分 析 中 间 代 码 生 成 中 间 代 码 优 化 后 端 目 标 代 码 生 成 源 程 序 目 标 程 序 错 误 处 理
第六章 语义分析及中间代码生成 • 6.1 语义分析概况 • 6.2 语法制导翻译的概述 • 6.3 中间代码的形式
6.1 语义分析概况 • 语义分析在编译程序中的位置 • 程序的语义涉及两个方面,即数据结构的语义、控制结构的语义。 • 数据结构的语义主要指域标识符相关联的数据对象,也即量的含义。控制结构的语义是语言定义的。 单词记号 语法分析器 语法树 语义分析器 语法树 中间代码生成器 中间代码
量涉及类型与值,值在程序运行时刻确定,而类型则由程序的说明部分来规定。 例如, int x, y; float z; char array[100]; • 把x、y、z和array分别与整型、整型、实型和字符数组型关联起来,它们分别代表相应类型的数据对象。 • 不同类型的数据对象有不同的机器内部表示,占用不同的存储空间,有不同的取值范围,对它们所能进行的运算也不同。只有相同类型、因而具有相同机内表示的数据对象,或符合特定要求的数据对象才能进行相应的运算。 • 当考虑标识符的相关含义时还必须要考虑到作用域的问题。 • 确定标识符所关联的类型、作用域等属性信息,进行类型正确性的检查成为语义分析的一个基本工作。
例如,对于C的while循环语句: while (<表达式>) <循环语句体>; • 规定了首先计算<表达式>的值,如果为真(或非0)时,就执行<循环语句体>; • 然后再计算<表达式>的值,并重复以上过程,直到<表达式>的值为假(或为0),便结束循环语句,执行while语句之后的语句。 • 语义分析将分析各个语法结构的含义并做出相应的语义处理。
语义分析的基本功能 • (1)确定类型 确定标识符所关联对象的数据类型。这部分工作有时由扫描器完成,扫描器将处理源程序的声明部分。 • (2)类型检查 按照语言的类型规则,对参加运算的运算分量进行类型检查,检查运算的合法性、运算分量类型的一致性(相容性),对于不相容的运算对象,报告错误,必要时进行相应的类型转换。 • 例如,对于数组变量个函数变量的加法运算额出现,报告语义错误;对于整型与实型数据对象的加法,把它们转换成同一类型。 • (3)控制流检查 对于任何引起控制流离开一个结构的语句,程序中必须由该控制转移可以转到的地方。 • 例如,C的break语句引起控制离开最小包围的while、for或switch语句,如果这样的包围语句不存在,则是一个错误。
(4)唯一性检查 有些场合,对象必须正好被定义一次。例如,集合中的元素只能出现一次,对象类的名字不能重复,分支语句的分情形常量必须区分. • 在Pascal语言中,标识符只能唯一第定义一次。 • (5)关联名字检查 有时,同样的名字必须出现两次或更多次。 • 例如,在C++语言中,构造函数的名字必须和类型一致;在Ada语言中,循环或程序块可以有名字出现在其开始和结束,编译程序必须检查两个地方的名字是否相同。 • (6)识别含义 根据程序语言的形式或非形式语义规则,识别程序中各个构造成分组合到一起的含义,并做相应的语义处理,
属性的引入 • 为了解释程序的语义、把程序翻译成可执行的代码,需要对文法符号引进一些表示程序语言结构性质的属性。 • 例如变量数据类型、表达式值、存储地址、过程体代码以及数的有效数字个数等. • 计算属性的值并把它和语言结构联系起来的过程称作属性的绑定。属性绑定发生在编译或运行过程的时刻叫做绑定时刻。不同属性的绑定时刻不同,对于不同的语言,甚至同样的属性也有不同的绑定时刻。 • 在程序运行前绑定的属性称为静态的,只能在程序运行期间才能绑定的属性是动态的。
属性的引入 • 在静态类型语言诸如C和Pascal中,变量或表达式的数据类型是主要的编译时刻的属性,类型检查器就是一个语义分析器,它计算语言实体的数据类型属性并验证这些类型符合语言的类型规则。 • 而LISP或Smalltalk中的数据类型是动态的,它们的编译必须产生计算类型的代码,然后在程序的运行过程中进行类型检查。 • 表达式的值通常是动态的,编译只产生在程序运行期间计算表达式的值的代码。然而,有些表达式可能是常数,例如,3.12*5+10,语义分析器可以在编译的时候计算它们的值。
属性的引入 • 对于不同的语言或者变量自身的性质,变量的存储分配可以是静态的、也可以是动态的。由于属性的计算依赖与程序的运行环境,甚至时目标机的细节,所以编译通常把属性的计算推迟到代码生成期间。 • 过程的目标码显然是静态属性。编译的代码产生器全权负责这类属性的计算。 • 数的有效数字个数这个属性一般不在编译期间处理,它隐含在编译程序构造期间对这些数值实现的处理,通常是运行环境的一部分。然而,如果要正确地翻译常数,扫描器也需要知道允许的有效数字的个数。
6.2 语法制导翻译的概述(如何把源程序翻译成相应的中间代码) • 基本思想: 在语法分析过程中,随着分析的步步进展,每当使用一条产生式进行推导(对于自上而下分析)或归约(对于自下而上分析),就执行该产生式所对应的语义动作,完成相应的翻译工作。 语法制导翻译就是把语言的一些属性附加到代表语言结构的文法符号上,这些属性值是由附加到文法产生式的“语义规则”中计算的,也就是为每个产生式配备翻译子程序,即语义子程序。 • 语法制导翻译法不论对自上而下分析或自下而上分析都适用
翻译的任务:语法结构的静态语义分析和正确性检查,若正确,则翻译成中间代码或目标代码。翻译的任务:语法结构的静态语义分析和正确性检查,若正确,则翻译成中间代码或目标代码。 • 使用的方法:称作语法制导翻译。 • 基本思想(简言之):根据翻译的需要设置文法符号的属性(这些属性代表与文法符号相关的信息),以描述语法结构的语义。 例如,一个变量的属性有类型,层次,存储地址等。表达式的属性有类型,值等。属性值的计算和产生式相联系。随着语法分析的进行,执行属性值的计算,完成语义分析和翻译的任务。
属性一般分为两类:综合属性和继承属性。简单的说,综合属性用于“自下而上”传递信息,而继承属性用于“自上而下”传递信息。属性一般分为两类:综合属性和继承属性。简单的说,综合属性用于“自下而上”传递信息,而继承属性用于“自上而下”传递信息。 属性加工加工的过程即是语义处理的过程,对于文法的每一个产生式都配备了一组属性的计算规则,则称为语义规则。
语法制导定义的形式 一个属性文法它包含一个上下文无关文法和一系列语义规则,这些语法规则附在文法的每个产生式上。 在一个语法制导定义中,A→P都有与之相关联的一套语义规则,规则形式为 b:= f(c1,c2,…,ck), f是一个函数,而且 1.b是A的一个综合属性并且c1,c2,…,ck是中的符号的属性,或者 2.b是中的符号的一个继承属性并且c1,c2,…,ck是A或中的任何文法符号的属性。 在两种情况下,都说 属性b依赖于属性c1,c2,…,ck。
一般来讲,对出现在产生式右边的继承属性和出现在产生式左边的综合属性都必须提供一个计算规则,属性计算规则中只能使用相应产生式的文法符号的属性,这有利于产生式范围内“封装”属性的依赖性。然而,出现在产生式左边的继承属性和出现在产生式右边的综合属性不由所给的产生式的属性计算规则进行计算,它们由其它产生式的属性规则计算,由属性计算器的参数提供。一般来讲,对出现在产生式右边的继承属性和出现在产生式左边的综合属性都必须提供一个计算规则,属性计算规则中只能使用相应产生式的文法符号的属性,这有利于产生式范围内“封装”属性的依赖性。然而,出现在产生式左边的继承属性和出现在产生式右边的综合属性不由所给的产生式的属性计算规则进行计算,它们由其它产生式的属性规则计算,由属性计算器的参数提供。 特例:开始符号没有继承属性,在开始时要确定; 终极符则只能有综合属性,而不能有继承属性。 非终结符既可有综合属性也可有继承属性
语义规则所描述的工作可以包括属性计算、静态语义检查、符号表操作、代码生成等。语义规则可能产生副作用(如产生代码),也可能不是变元的严格函数(如某个规则给出可用的下一个数据单元的地址)。这样的语义规则通常写成过程调用,或过程段。语义规则所描述的工作可以包括属性计算、静态语义检查、符号表操作、代码生成等。语义规则可能产生副作用(如产生代码),也可能不是变元的严格函数(如某个规则给出可用的下一个数据单元的地址)。这样的语义规则通常写成过程调用,或过程段。 综合属性: 在语法树中,一个结点的综合属性的值由其子结点的属性值确定。因此,通常使用自底向上的方法在每一个结点处使用语义规则计算综合属性的值。仅仅使用综合属性的属性文法称S—属性文法。 继承属性: 在语法树中,一个结点的继承属性由此结点的父结点和/或兄弟结点的某些属性确定。用继承属性来表示程序语言结构中的上下文依赖关系很方便。
例6.1 台式计算器程序的语法制导定义(表6.1) 产生式 语义规则 S’E print(Eval) E E1+T E val := E1 val+T val E T E val := T val T T1*F T val := T1 val*F val T F T val := F val F (E) F val := E val F digit F val := digitlexval 例如:把左例中的类型扩充到 int和real。 每个文法符号和一个属性值val 联系,属性值的设置和语法结构的语义以及翻译程序的需要有关。
综合属性 S-属性定义 唯独只使用综合属性的语法制导定义。 结点属性值的计算正好和自底向上分析建立分析树结点同步进行。 例 6 .2 输入:3*5+4n
例 6 .2 输入:3*5+4n Eval:=19 Eval:=15 + Tval:=4 Tval:=15 Fval:=4 digitlexval:=4 Tval:=3 * Fval:=5 LEn E E1+T E T T T1*F T F F (E) F digit Fval:=3 digitlexval:=5 digitlexval:=3
◆综合属性值的计算方法 对于s-属性定义 通常使用自底向上的分析方法 使用语义规则来计算 在建立 每一个 结点处 综合 属性值 即在 用哪个产生式进行归约后,就执行那个产生式的s-属性定义计算属性的值, 从叶结点到根结点进行计算。
继承属性 继承属性值是由此结点的父结点和/或兄弟结点的某些属性值来决定的。 例 描述说明语句中各种变量的类型信息的语义规则。 文法定义了一种说明语句,该说明语句的形式由关键字int或real开头,后跟一个标识符表,每个标识符间有逗号隔开。非终结符号T有一个综合属性type,它的值由关键字int或real决定。与产生式D->TL相联的语义L.in:=T.type将L.in的属性值置为该说明语句指定的类型。属性L.in将沿着语法树传递到下边的结点使用,与L产生式相联的规则里使用了它。过程addtype的功能是把每个标识符的类型信息登录在符号表中相关项中。
表6.2 带有继承属性L.in的语法制导定义 产生式 语义规则 DTL Lin:=T type T int T type :=integer T real T type :=real L L1,id L1in :=L in addtype(id entry,L in) L id addtype(id entry,L in)
分析real i1, i2, i3 D T.type L.in T L real i3.entry L.in real i3 L i2.entry L.in i2 L i1.entry i1
语法制导翻译的实现途径 以自下而上( LR分析)的语法制导翻译来说明 • 将LR分析器能力扩大,增加在归约后调用语义规则的功能 • 增加语义栈,语义值放到与符号栈同步操作的语义栈中,多项语义值可设多个语义栈 ,栈结构为:
例 简单算术表达式求值的属性文法 • L →E {print(E.val)} • E→E1+T { E.val :=E1.val +T.val } • E→T { E.val :=T.val } • T→T1*digit { T.val :=T1.val * digit.lexval } • T→digit { T.val :=digit.lexval }
6.3 中间代码(源程序的中间形式) 何谓中间代码: (Intermediate code/ Intermediate representation/Intermediate language) 可以使编译程序的结构清晰、简单、明确。源程序的一种内部表示,不依赖目标机的结构,易于机械生成目标代码的中间表示。 为什么要此阶段及使用原则 主要优点是可移植(与具体目标程序无关),且易于目标代码优化 原则:1、形式比较简单,容易翻译成相应的目标机器代码。 2、能充分反映源程序的特点。 中间代码的几种形式 逆波兰、四元式、三元式、树型
6.3.1 逆波兰记号(后缀式) • 将运算对象写在前面,把运算符号写在后面 (a+b) (a+c) 的后缀式为 ab+ac+ a+b+c/d (a+c) 的后缀式为 abcd/ac+++ not A or not (C and not B) 的后缀式为 A not CB not and not or
后缀式的计算机处理 • 后缀式的最大优点是易于计算机处理 • 处理过程: 从左到右扫描后缀式,每碰到运算对象就推进栈;碰到运算符就从栈顶弹出相应目数的运算对象施加运算,并把结果推进栈。最后的结果留在栈顶。 例:表达式-b+c*d的后缀式 b@cd*+的计值过程 t1= - b t2= c*d t3= t1+t2
逆波兰表示法的扩充 逆波兰表示法很容易扩充到表达式以外的范围 例如(a+b)*c的逆波兰为ab+c*
逆波兰示例 • 例: • 把下述产生式定义的算术表达式映射到后缀波兰表示: • 产生式 • 翻译成分 • E=ET+ • EE+T • E T E=T • T=TF T TF • T=F • T F F (E) F=E • F a F=a
确定输入a+aa的输出: • (E,E)(E+T,ET+) • (T+T,TT+) • (F+T,FT+) • (a+T,aT+) • (a+TF,aFF+) • (a+FF,aFF+) • (a+aF,aaF+) • (a+aa,aaa+)
= a + * * b c b d 6.3.2 三元式和树形表示 • 格式:(算符, 第一运算对象, 第二运算对象) • 如:a=b*c+b*d(1) (*,b,c)(2) (*,b,d)(3) (+,(1),(2))(4) (=,(3),a)
6.3.3 四元式 • 由于三元式中的结果是用它的编号表示的,当在三元式进行优化后,就要用一定的时间重新安排三元式的编号,很费时间。为了防止优化后的重新编址,在三元式基础上增加了一个存放结果的单元,这就形成了四元式子,是一种最常用的形式。 • 格式:(算符, 第一运算对象, 第二运算对象, 结果) • 如:a=b*c+b*d(1) (*,b,c,t1)(2) (*,b,d,t2)(3) (+,t1,t2,t3)(4) (=,t3,-,a)
四元式的特点 • 类似于三地址指令 • 四元式虽然比三元式多了一结果的引用,但有利于优化和代码生成 • 为了便于书写四元式也可以写成如下形式: • <结果>:=<运算对象1><运算符><运算对象2> • 则表达式a+(-b*c+d)*e的四元式为: (1) t1:=-b (2) t2:=t1*c (3) t3=t2+d (4) t4=t3*e (5) t5=a+t4 • 同样要将算法语言翻译成相应的四元式,也要将四元式扩充到其他运算符,如(jmp,_,L)表示无条件转向第L条四元式。
例题:写出算术表达式A+B*(C-D)+E/(C-D)**N的四元式三元式例题:写出算术表达式A+B*(C-D)+E/(C-D)**N的四元式三元式 四元式序列 • (1) (-,C,D,T1) • (2) (*,B,T1,T2) • (3) (+,A,T2,T3) • (4) (-,C,D,T4) • (5) (**,T4,N,T5) • (6) (/,E,T5,T6) • (7) (+,T3,T6,T7) 三元式序列 • (1) (-,C,D) • (2) (*,B,(1)) • (3) (+,A,(2)) • (4) (-,C,D) • (5) (**,(4),N) • (6) (/,E,(5)) • (7) (+,(3),(6))
6.4.4 汇编代码 汇编语言是依赖于机器的低级程序设计语言,它是面 向具体的计算机系统或相应的计算机系列的,它和三元式相比 有以下优点: (1)能方便地翻译成目标机器指令。 (2)不必直接计算转移地址。 (3)可以使用各种数据表示法。
