Download

1 / 22
230 likes | 266 Views
Explore the use of deep learning to automate the reasoning process and infer new triples from existing facts in RDF graphs. This approach utilizes recurrent networks to generate the materialization of RDF data, enhancing the semantic web capabilities. The process involves preparing ground-truth data, designing recurrent networks, encoding and decoding input data, and incremental materialization to infer new relationships. Results show high accuracy and efficiency in generating new triples.

E N D
Semantic Machine Learning Deep Learning of RDF rules
Outline • Deep Learning motivation • Semantic Reasoning • Deep learning of RDFS rules • Results • Discussion 2
Deep Learning motivation After a few decades of low popularity relative to other machine learning methods, neural networks are trending again with the deep learning movement. Other machine learning techniques rely on the selection of pertinent features of the data, Deep neural networks learn the best features for each task. 3
Deep Learning Auto-encoder • Input data = target data • Learning efficient encodings. • Typically for dimensionality reduction. 4
Deep Learning MNIST example • MNIST (Mixed National Institute of Standards and Technology database) large database of handwritten digits. • Learning pen strokes with auto-encoder 5
Deep LearningPanoply of Applications: Computer vision • Convolutional nets: Loosely based on (what little) we know about the visual cortex • Deeper layers learn more complex features: • Edges → Shapes → Objects 6
Deep LearningPanoply of Applications: ImageNet Challenge • ImageNet is an image database organized according to the WordNet hierarchy • Classification error dropping from 25.8 % in 2011 to 3.46 % in 2015 7
Deep Learning Recurrent neural networks • Convolutional nets are more suitable for static images. To learn from sequential data (Texts, Speech, Videos), we typically use Recurrent Neural Networks. • Neural networks with loops, so the previous inputs affect the current output. • BackPropagation Through Time (BPTT) 8
Deep Learning Sequence-To-Sequence Learning • When input and target are sequences, such in machine translation, we use Sequence-to-sequence training. • Encoding RNN and decoding RNN 9
Rules Learning Main Idea • Input: a, transitive_property, b, b, transitive_property, c • Target: a, transitive_property, c 10
Semantic Web • Semantic Web: Extends the Web of documents to the Web of Data, where computers can reason about the data. • Semantic Web Stack: A set of Standards and technologies that aims to realize this vision 11
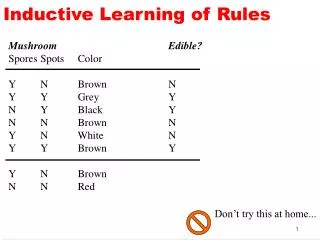
RDFS reasoning • Inferring new triples from existing facts. Example: <http://swat.cse.lehigh.edu/onto/univ-bench.owl#advisor> <http://www.w3.org/2000/01/rdf-schema#range> <http://swat.cse.lehigh.edu/onto/univ-bench.owl#Professor> . <https://tw.rpi.edu/web/person/bassemmakni> <http://swat.cse.lehigh.edu/onto/univ-bench.owl#advisor> <https://tw.rpi.edu//web/person/JimHendler> . <https://tw.rpi.edu//web/person/JimHendler> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://swat.cse.lehigh.edu/onto/univ-bench.owl#Professor> . • RDFS Materialization: Given an RDF Graph, generate all the inferred triples. 12
Approach • Goal: • Design recurrent networks able to learn the entailments of RDFS rules. • Use these networks to generate the materialization of an RDF graph. • Steps: • Preparing the RDFS ground-truth • Recurrent network design • Encoding/Decoding • Incremental materialization 13
Preparing the RDFS ground-truth For each pattern we collected 10 thousands samples from Dbpedia and the BBC SPARQL endpoint. 14
Recurrent network design Using Keras: a deep learning framework that facilitates the design of neural network models and can run models using Theano or TensorFlow as a back end. 15
Encoding decoding • One hot encoding (global): We assign an ID for each RDF resource in the full ground truth, and we use these IDs to generate one hot encoded vectors for each input and output. This leads to very big vectors and learning becomes very slow. • Word2Vec: We encode the full ground truth using the Word2Vec algorithm where we treat each triple as one sentence. Good performance in the training set, but suffers from overfitting. • One hot encoding (local): A simpler approach that performs much better with good accuracy and learning speed is to encode each input separately. 16
Incremental materialization • After the training of our network on the DBpedia+BBC ground truth, we use the network to materialize the LUBM graph. • LUBM: Benchmark ontology describing the academic world concepts and relations. • Algorithm: • Running a SPARQL query to collect all rules patterns against an RDF store hosting the LUBM graph. • Encoding the collected triples. • Using the trained network to generate new triples encodings. • Decoding the output to obtain RDF triples. • Insert the generated triples back in the RDF store. • We repeat these steps till no new inferences are generated. 17
Results • Training accuracy: From the data collected in the DBpedia ground truth, we use 20% for validation test. The training process takes less than 10 minutes with 10 iterations over the data, and we reach 0.998 validation accuracy 19
Results • LUBM1 is generated using one university, and contains 100 thousands triples. OWLIM generates 41 113 thousands inferred triples. • When running our incremental materialization, we needed 3 iterations to achieve the stagnation of the materialization. We missed 369 triples • (RDFS axioms). 20
Conclusions • Our prototype proves that sequence-to-sequence neural networks can learn RDFS and be used for RDF graph materialization. • The advantages of our approach: • Our algorithm is natively parallel, and can profit from the advances in the deep learning frameworks and the GPU speeds. • Deployment on neuromorphic chips. Our lab is in the process of getting access to the IBM TrueNorth chip, and we are planning to run our reasoner on TrueNorth chip. 21