Download
1 / 19
190 likes | 205 Views
Learn about cluster analysis, a technique for partitioning data into groups based on similarity and dissimilarity, and its applications, requirements, and evaluation methods.

E N D
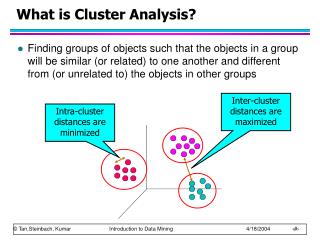
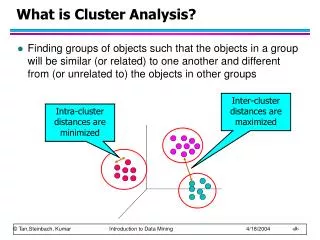
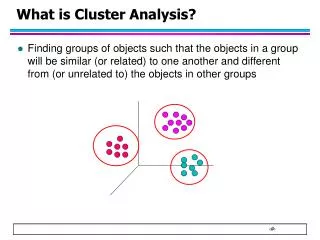
What is Cluster Analysis • Clustering– Partitioning a data set into several groups (clusters) such that • Homogeneity: Objects belonging to the same cluster are similar to each other • Separation: Objects belonging to different clusters are dissimilar to each other. • Three fundamental elements of clustering • The set of objects • The set of attributes • Distance measure
Supervised versus Unsupervised Learning • Supervised learning (classification) • Supervision: Training data (observations, measurements, etc.) are accompanied by labels indicating the class of the observations • New data is classified based on training set • Unsupervised learning (clustering) • Class labels of training data are unknown • Given a set of measurements, observations, etc., need to establish existence of classes or clusters in data
What Is Good Clustering? • Good clustering method will produce high quality clusters with • high intra-class similarity • low inter-class similarity • Quality of a clustering method is also measured by its ability to discover some or all of hidden patterns • Quality of a clustering result depends on both the similarity measure used by the method and its implementation
Requirements of Clustering in Data Mining • Scalability • Ability to deal with different types of attributes • Minimal requirements for domain knowledge to determine input parameters • Able to deal with noise and outliers • Discovery of clusters with arbitrary shape • Insensitive to order of input records • High dimensionality • Incorporation of user-specified constraints • Interpretability and usability
Application Examples • A stand-alone tool: explore data distribution • A preprocessing step for other algorithms • Pattern recognition, spatial data analysis, image processing, market research, WWW, … • Cluster documents • Cluster web log data to discover groups of similar access patterns
Co-expressed Genes Gene Expression Data Matrix Gene Expression Patterns Co-expressed Genes • Why looking for co-expressed genes? Co-expression indicates co-function; Co-expression also indicates co-regulation.
Examples of co-expressed genes and coherent patterns in gene expression data Gene-based Clustering Iyer’s data [2] • [2] Iyer, V.R. et al. The transcriptional program in the response of human fibroblasts to serum. Science, 283:83–87, 1999.
Data Matrix • For memory-based clustering • Also called object-by-variable structure • Represents n objects with p variables (attributes, measures) • A relational table
Two-way Clustering of Micoarray Data • Clustering genes • Samples are attributes • Find genes with similar function • Clustering samples • Genes are attributes. • Find samples with similar phenotype, e.g. cancers. • Feature selection. • Informative genes. • Curse of dimensionality.
Dissimilarity Matrix • For memory-based clustering • Also called object-by-object structure • Proximities of pairs of objects • d(i,j): dissimilarity between objects i and j • Nonnegative • Close to 0: similar
Distance Matrix Distance Matrix Original Data Matrix
How Good Is the Clustering? • Dissimilarity/similarity depends on distance function • Different applications have different functions • Inter-clusters distance maximization • Intra-clusters distance minimization • Judgment of clustering quality is typically highly subjective
Types of Data in Clustering • Interval-scaled variables • Binary variables • Nominal, ordinal, and ratio variables • Variables of mixed types
Interval-valued Variables • Continuous measurements of a roughly linear scale • Weight, height, latitude and longitude coordinates, temperature, etc. • Effect of measurement units in attributes • Smaller unit larger variable range larger effect to the result • Standardization + background knowledge
Standardization • Calculate the mean absolute deviation , • The mean is not squared, so the effect of outliers is reduced. • Calculate the standardized measurement (z-score) • Mean absolute deviation is more robust • The effect of outliers is reduced but remains detectable
Minkowski Distance • Minkowski distance: a generalization • If q = 2, d is Euclidean distance • If q = 1, d is Manhattan distance xi Xi (1,7) 12 8.48 q=2 q=1 6 6 xj Xj(7,1)
Properties of Minkowski Distance • Nonnegative: d(i,j) 0 • The distance of an object to itself is 0 • d(i,i)= 0 • Symmetric: d(i,j)= d(j,i) • Triangular inequality • d(i,j) d(i,k)+ d(k,j) i j k
Major Clustering Approaches • Partitioning algorithms: Construct various partitions and then evaluate them by some criterion • Hierarchy algorithms: Create a hierarchical decomposition of set of data (or objects) using some criterion • Density-based: based on connectivity and density functions • Grid-based: based on a multiple-level granularity structure
Clustering Algorithms • If we “clustering” the clustering algorithms Clustering algorithms Partition-based Hierarchical clustering Density-based Model-based … Centroid-based Medoid-based K-means PAM CLARA CLARANS