Download

1 / 39
390 likes | 561 Views
Course Overview. PART I: overview material 1 Introduction 2 Language processors (tombstone diagrams, bootstrapping) 3 Architecture of a compiler PART II: inside a compiler 4 Syntax analysis 5 Contextual analysis 6 Runtime organization 7 Code generation PART III: conclusion

E N D
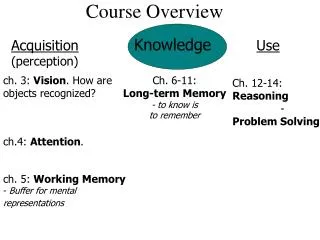
Course Overview PART I: overview material 1 Introduction 2 Language processors (tombstone diagrams, bootstrapping) 3 Architecture of a compiler PART II: inside a compiler 4 Syntax analysis 5 Contextual analysis 6 Runtime organization 7 Code generation PART III: conclusion • Interpretation 9 Review
Levels of Programming Languages High-level program class Triangle { ... float area( ) { return b*h/2; } Low-level program LOAD r1,b LOAD r2,h MUL r1,r2 DIV r1,#2 RET Executable Machine code 0001001001000101001001001110110010101101001...
Compilers and other translators Examples: Chinese => English Java => JVM byte codes Scheme => C C => Scheme x86 Assembly Language => x86 binary codes • Other non-traditional examples: • disassembler, decompiler (e.g. JVM => Java)
Program P implemented in L Translator implemented in L S --> T L P Machine implemented in hardware Language interpreter in L L M M L Tombstone Diagrams What are they? • diagrams consisting out of a set of “puzzle pieces” we can use to reason about language processors and programs • different kinds of pieces • combination rules (not all diagrams are “well formed”)
Syntax Specification Syntax is specified using “Context Free Grammars”: • A finite set of terminal symbols • A finite set of non-terminal symbols • A start symbol • A finite set of production rules Often CFG are written in “Bachus Naur Form” or BNF notation. Each production rule in BNF notation is written as: N ::= a where N is a non terminal and a a sequence of terminals and non-terminals N ::= a | b | ... is an abbreviation for several rules with N as left-hand side.
Concrete and Abstract Syntax The grammar specifies the concrete syntax of a programming language. The concrete syntax is important for the programmer who needs to know exactly how to write syntactically well-formed programs. The abstract syntax omits irrelevant syntactic details and only specifies the essential structure of programs. Example: different concrete syntaxes for an assignment v := e (set! v e) e -> v v = e
Context-Free Grammars • Grammar • String
Context-Free Grammars (continued) The given string has 2 parse trees (concrete syntax trees). So the grammar is ambiguous. E E E + E E E * E E id id E + E * id id id id
Abstract Syntax Trees Abstract Syntax Tree for: d:=d+10*n AssignmentCmd BinaryExpression BinaryExpression VName VNameExp IntegerExp VNameExp SimpleVName SimpleVName SimpleVName Int-Lit Ident Ident Op Ident Op + 10 d d n * Note: Triangle does not have precedence levels like C++
Undefined! Scope Rules Type Rules Type error! Contextual Constraints Syntax rules alone are not enough to specify the format of well-formed programs. Example 1: let const m~2 in putint(m + x) Example 2: let const m~2 ; var n:Boolean in begin n := m<4; n := n+1 end
Semantics Specification of semantics is concerned with specifying the “meaning” of well-formed programs. • Terminology: • Expressions are evaluated and yield values (and may or may not perform side effects). • Commands are executed and perform side effects. • Declarations are elaborated to produce bindings. • Side effects: • change the values of variables • perform input/output
Phases of a Compiler A compiler’s phases are steps in transforming source code into object code. The different phases correspond roughly to the different parts of the language specification: • Syntax analysis <--> Syntax • Contextual analysis <--> Contextual constraints • Code generation <--> Semantics
Compiler Passes • A pass is a complete traversal of the source program, or a complete traversal of some internal representation of the source program (such as the syntax tree). • A pass can correspond to a “phase” but it does not have to! • Sometimes a single “pass” corresponds to several phases that are interleaved in time. • What and how many passes a compiler does over the source program is an important design decision.
Syntax Analysis Dataflow chart Source Program Stream of Characters Scanner Error Reports Stream of “Tokens” Parser Error Reports Abstract Syntax Tree
Regular Expressions • RE are a notation for expressing a set of strings of terminal symbols. • Different kinds of RE: • e The empty string • t Generates only the string t • X Y Generates any string xy such that x is generated by x • and y is generated by Y • X | Y Generates any string which generated either • by X or by Y • X* The concatenation of zero or more strings generated • by X • (X) For grouping,
Regular Expression Corresponding Set of Strings {""} a {"a"} a b c {"abc"} a | b | c {"a", "b", "c"} (a | b | c)* {"", "a", "b", "c", "aa", "ab", ..., "bccabb" ...} Language Defined by a Regular Expression • Recall: language = set of strings • Language defined by a regular expression = set of strings that match the expression
FSM and the implementation of Scanners • Regular expressions, NFSM’s, and DFSM’s are all equivalent formalisms in terms of what languages can be defined with them. • Regular expressions are a convenient notation for describing the “tokens” of programming languages. • Regular expressions can be converted into NFSM’s (the algorithm for conversion into DFSM is straightforward). • DFSM’s can be easily implemented as computer programs.
DFSM Example: Integer Literals Here is a DFSM that accepts integer literals with an optional + or – sign: digit B digit digit + S A –
Parsing Parsing == Recognition + determining syntax structure (for example by generating AST) • Different types of parsing strategies • bottom up • top down • Recursive descent parsing • What is it • How to implement one given an EBNF specification
Sentence Subject Subject Verb Verb Object Object . Noun Noun Noun Noun The cat sees a rat . Top-down parsing Sentence The The cat cat sees sees a rat rat . .
Sentence Subject Object Noun Verb Noun Bottom up parsing The The cat cat sees sees a a rat rat . .
Development of Recursive Descent Parser (1) Express grammar in EBNF (2) Grammar Transformations: Left factorization and Left recursion elimination (3) Create a parser class with • private variable currentToken • methods to call the scanner: accept and acceptIt (4) Implement a public method for main function to call: • public parsemethod that • fetches the first token from the scanner • calls parseS (where S is start symbol of the grammar) • verifies that scanner next produces the end–of–file token (5) Implement private parsing methods: • add private parseN method for each non terminal N
LL 1 Grammars • The presented algorithm to convert EBNF into a parser does not work for all possible grammars. • It only works for so called “LL 1” grammars. • Basically, an LL 1 grammar is a grammar which can be parsed with a top-down parser with a lookahead (in the input stream of tokens) of one token. • What grammars are LL 1? How can we recognize that a grammar is (or is not) LL 1? => We can deduce the necessary conditions from the parser generation algorithm.
VarDecl SimpleT Contextual Analysis --> Decorated AST Annotations: Program result of identification LetCommand :typeresult of type checking SequentialCommand SequentialDeclaration AssignCommand :int AssignCommand BinaryExpr SimpleV :int VarDecl Char.Expr VNameExp Int.Expr :char :int :int SimpleT SimpleV SimpleV :char :int Ident Ident Ident Ident Ident Char.Lit Ident Ident Op Int.Lit n c n n Integer Char c ‘&’ + 1
Nested Block Structure A language exhibits nested block structure if blocks may be nested one within another (typically with no upper bound on the level of nesting that is allowed). Nested • There can be any number of scope levels (depending on the level of nesting of blocks): • Typical scope rules: • no identifier may be declared more than once within the same block (at the same level). • for any applied occurrence there must be a corresponding declaration, either within the same block or in a block in which it is nested.
Type Checking For most statically typed programming languages, a bottom up algorithm over the AST: • Types of expression AST leaves are known immediately: • literals => obvious • variables => from the ID table • named constants => from the ID table • Types of internal nodes are inferred from the type of the children and the type rule for that kind of expression
Runtime organization • Data Representation: how to represent values of the source language on the target machine. • Primitives, arrays, structures, unions, pointers • Expression Evaluation: How to organize computing the values of expressions (taking care of intermediate results) • Register machine vs. stack machine • Storage Allocation: How to organize storage for variables (considering various lifetimes of global, local, and heap variables) • Activation records, static/dynamic links, dynamic allocation • Routines: How to implement procedures, functions (and how to pass their parameters and return values) • Value vs. reference parameters, closures, recursion • Object Orientation: Runtime organization for OO languages • Method tables
Java Virtual Machine External representation (platform independent) JVM Internal representation (implementation dependent) .class files load classes primitive types arrays objects strings methods The JVM is an abstract machine in the truest sense of the word. The JVM specification does not give implementation details (can be dependent on target OS/platform, performance requirements, etc.) The JVM specification defines a machine independent “class file format” that all JVM implementations must support.
Inspecting JVM code % javac Factorial.java % javap -c -verbose Factorial Compiled from Factorial.java class Factorial extends java.lang.Object { Factorial(); /* Stack=1, Locals=1, Args_size=1 */ int fac(int); /* Stack=2, Locals=4, Args_size=2 */ } Method Factorial() 0 aload_0 1 invokespecial #1 <Method java.lang.Object()> 4 return
Compiling and Disassembling ... // address: 0 1 2 3 Method int fac(int) // stack: this n result i 0 iconst_1 // stack: this n result i 1 1 istore_2 // stack: this n result i 2 iconst_2 // stack: this n result i 2 3 istore_3 // stack: this n result i 4 goto 14 7 iload_2 // stack: this n result i result 8 iload_3 // stack: this n result i result i 9 imul // stack: this n result i result*i 10 istore_2 // stack: this n result i 11 iinc 3 1 // stack: this n result i 14 iload_3 // stack: this n result i i 15 iload_1 // stack: this n result i i n 16 if_icmplt 7 // stack: this n result i 19 iload_2 // stack: this n result i result 20 ireturn
~ ~ Code Generation Source Program Target program let var n: integer; var c: charin begin c := ‘&’; n := n+1end PUSH 2LOADL 38STORE 1[SB]LOAD 0[SB]LOADL 1CALL addSTORE 0[SB]POP 2HALT Source and target program must be “semantically equivalent” Semantic specification of the source language is structured in terms of phrases in the SL: expressions, commands, etc. => Code generation follows the same “inductive” structure.
Specifying Code Generation with Code Templates The code generation functions for Mini Triangle Syntax class Function Effect of the generated code Run program P then halt. Start and finish with empty stack. Execute command C. May update variables but does not shrink or grow the stack! Evaluate expression E. Net result is pushing the value of E onto the stack. Push the value of constant or variable onto the stack. Pop value from stack and store in variable V. Elaborate declaration D. Make space on the stack for constants and variables in D. run P executeC evaluateE fetchV assignV elaborate D Program Command Expres- sion V-name V-name Decla-ration
Code Generation with Code Templates While command • execute [whileE doC] = • JUMP h • g: execute [C] • h: evaluate[E] • JUMPIF(1) g C E
Two Kinds of Interpreters • Iterative interpretation: Well suited for quite simple languages, and fast (at most 10 times slower than compiled languages) • Recursive interpretation: Well suited for more complex languages, but slower (up to 100 times slower than compiled languages)
Hypo: a Hypothetical Abstract Machine • 4096-word code store and 4096-word data store • PC: program counter (register), initially 0 • ACC: general purpose accumulator (register), initially 0 • 4-bit opcode and 12-bit operand • Instruction set: OpcodeInstructionMeaning 0 STORE d word at address d := ACC 1 LOAD d ACC := word at address d 2 LOADL d ACC := d 3 ADD d ACC := ACC + word at address d 4 SUB d ACC := ACC – word at address d 5 JUMP d PC := d 6 JUMPZ d if ACC = 0 then PC := d 7 HALT stop execution
Mini-Basic Interpreter • Mini-Basic abstract machine: • Data store: array of size 26 floating-point values • Code store: array of commands • Possible representations for each command: • Character string (yields slowest execution) • Sequence of tokens (good compromise) • AST (yields longest response time)
Recursive Interpretation • Recursively defined languages cannot be interpreted iteratively (fetch-analyze-execute), because each command can contain any number of other commands • Both analysis and execution must be recursive (similar to the parsing phase when compiling a high-level language) • Hence, the entire analysis must precede the entire execution: • Step 1: Fetch and analyze (recursively) • Step 2: Execute (recursively) • Execution is a traversal of the decorated AST, hence we can use a new visitor • Values (variables and constants) are handled internally
Code optimization (improvement) The code generated by our compiler is not efficient: • It computes some values at runtime that could be known at compile time • It computes some values more times than necessary We can do better! • Constant folding • Common sub-expression elimination • Code motion • Dead code elimination
Optimization implementation • Is the optimization correct or safe? • Is the optimization really an improvement? • What sort of analyses do we need to perform to get the required information? • Local • Global