Download

1 / 28
280 likes | 410 Views
WLCG Overview Board 3 rd September 2010, CERN. Project Status Report. Ian Bird. Topics. Experience with data Service quality Resource installations Milestones Budget issues RRB issues Tier 3s Service evolution. 5 months with LHC data. ATLAS: 1.7 PB raw. CMS:

E N D
WLCG Overview Board 3rd September 2010, CERN Project Status Report Ian Bird
Topics • Experience with data • Service quality • Resource installations • Milestones • Budget issues • RRB issues • Tier 3s • Service evolution Ian.Bird@cern.ch
5 months with LHC data ATLAS: 1.7 PB raw • CMS: • 220 TB of RAW data at 7 TeV • 70 TB Cosmics during this period • 110 TB Tests and exercises with trigger. LHCb: 70 TB raw data since June ALICE: 550 TB Ian.Bird@cern.ch
WLCG Usage • Use remains consistently high • 1 M jobs/day; 100k CPU-days/day 1 M jobs/day 100k CPU-days/day LHCb CMS • Large numbers of analysis users • CMS ~500, ATLAS~1000, LHCb/ALICE ~200 ALICE: ~200 users, 5-10% of Grid resources
Job workloads CMS: 100k jobs per day; Red: analysis LHCb ATLAS: analysis jobs ALICE: 60 sites, ~20K jobs running in parallel
Data transfers (mostly!) at rates anticipated Data transfers 24x24 500MB/s Traffic on OPN up to 70 Gb/s! - ATLAS reprocessing campaigns 48x48 800MB/s ATLAS Throughput • CMS saw effect of going from 24x24 to 48x48 bunches
Data distribution ATLAS: Total throughput T0-T1; T1-T1; T1-T2 CMS: T0 – T1 LHCb: T0 – T1 Ian.Bird@cern.ch
Data distribution for analysis • For all experiments: early data has been available for analysis within hours of data taking Ian.Bird@cern.ch
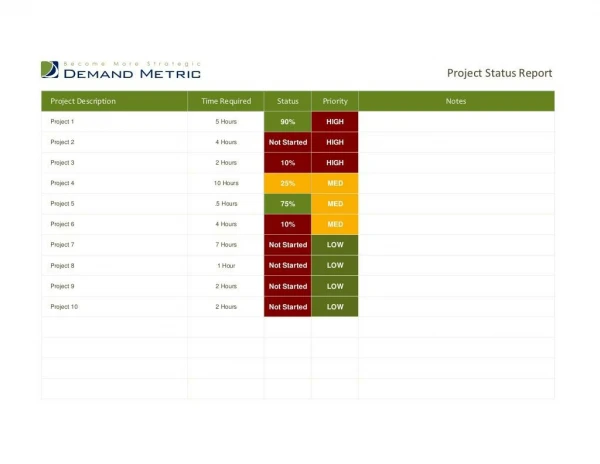
Resource status Ian.Bird@cern.ch
Issues with resources • CNAF • Remainder of disk and CPU to be available 1st Sep. • NL-T1 • Had serious issues with disks. Data corruption meant 2/3 was unusable for some time. • ASGC: • Remaining 1 PB disk not available before end Oct. Ian.Bird@cern.ch
CPU – July • Significant use of Tier 2s for analysis • frequently-expressed concern that too much analysis would be done at CERN is not reflected • Tier 0 capacity underused in general • But this is expected to change as luminosity increases Ian.Bird@cern.ch
Q2 2010 Service incidents – Q2 Ian.Bird@cern.ch
Q3 2010 Incidents – Q3 NL-T1 DB issue: Illustrates criticality of LFC for ATLAS. We must set up a live stand-by for all ATLAS T1s. Done already at CNAF. Could be hosted centrally. Ian.Bird@cern.ch
ALICE data loss (May) • A configuration error in Castor resulted in data being directed across all available tape pools instead of to the dedicated raw data pools • For ALICE, ATLAS, CMS this included a pool where the tapes were re-cycled after a certain time • The result of this was that a number of files were lost on tapes that were recycled • For ATLAS and CMS the tapes had not been overwritten and could be fully recovered (fall back would have been to re-copy files back from Tier 1s) • For ALICE 10k files were on tapes that were recycled, inc 1700 files of 900 GeV data • Actions taken: • Underlying problem addressed; all recycle pools removed • Software change procedures being reviewed now • Action to improve user-facing monitoring in Castor • Tapes sent to IBM and SUN for recovery – have been able to recover ~97% of critical (900 GeV sample) files, ~50% of all ALICE files • Work with ALICE to ensure that always 2 copies of data available • In HI running there is a risk for several weeks until all data is copied to Tier 1s; several options to mitigate this risk under discussion • As this was essentially a procedural problem: we will organise a review of Castor operations procedures (sw dev, deployment, operation etc) together with experiments and outside experts – timescale of September.
Milestones • Pilot jobs, glexec, SCAS, etc (1st July) • No pressure at the moment as data taking takes priority • CREAM deployment: • >100 sites have a CREAM CE; • still missing job submission from condor-g (needed by ATLAS) • Stability and reliability of CREAM still not good enough to replace LCG-CE, many open tickets • Gathering of installed capacity Ian.Bird@cern.ch
Milestones – 2 • Storage accounting reports: • For Tier 1 sites, proto-report for beginning Sep • For Tier 2 sites, for end Oct • Before these are regularly published significant effort has to be devoted to checking the published data (see slide on installed capacity) – lots missing! • From DM and virtualisation activities: • Create a small architectural team • Address several strategic questions: (Nov) • Xrootd as a strategy for data access by all experiments? • Need for ability to reserve whole WN (to better use cores) – is this a clear requirement for all experiments? • CERNVM and/or CVMFS as a strategy for all experiments? • Proposal for better managing Information System and data (end Sep) Ian.Bird@cern.ch
Installed capacity • Action has been pending for a long time: • Information requested by RRB/RSG • Significant effort was put into defining and agreeing how to publish and collect the data – via the information system. • Document has been available for some time • Tool (gstat2) now has the ability to present this information • Significant effort still required to validate this data before it is publishable • Propose to task Tier 1s with validation for Tier 2s, but Tier 1 data is not good yet! • Sites need to publish good data urgently Ian.Bird@cern.ch
Published capacities ... Ian.Bird@cern.ch
Budget Issues at CERN • IT asked to reduce 15M over MTP (2011-15) • Proposal of 12M reduction accepted – this is what was approved by FC last week • Part (8.25MCHF over 5 years) comes from the LCG budgets: • Move to 4-year equipment replacement cycles • Save 2 MCHF in 2011, very little afterwards • Stop CERN contribution to USLHCnet • Save 350 kCHF/year. • NB. No CERN contribution to costs of other Tier 1s • Reduce slope of Tier 0 computing resource increase • Save ~ 1 MCHF/year on average • This is the main mechanism we have to reduce costs. Current assumption was ~30%/year growth. Ian.Bird@cern.ch
Budget implications • Note that the proposals have not been discussed with the experiments, nor with the Committees overseeing LCG (LHCC, RRB/C-RSG, OB, etc...) • Reducing the Tier-0 Computing resources for LHC experiments does not seem wise now the detectors are ramping up • Not even taking into account the lack of experience with Heavy Ions • Slowing down the replacement cycles and reducing the slope of computing resources increase • Delays the need for additional computing infrastructure needed for the Tier-0 (e.g. containers) • Will strictly limit the overall experiment computing growth rate in the Tier-0 • Assumes no additional requests from non-LHC experiments • Detailed planning requires further studies • Extending lifetime of hardware from 3 to 4 years • Does not gain anything if the maintenance is extended • Has negative impact on power budget • Requires additional spares, therefore additional budget • May impact service quality • Implies additional effort to cover for repairs • USLHCNet • May have secondary effects ... Ian.Bird@cern.ch
Tier 0 planning – status • Plan for a new Tier 0 building at CERN is cancelled (noted at SPC last week) • Delayed need for containers (or other alternate solution) by ~1 year or more: • Budget reduction will have implications for total power needs • Efforts invested in recent years have benefitted total power needs • Ongoing plans for upgrading B513 from 2.9 to 3.5MW including up to 600 kW diesel-backed power, together with use of local hosting (100 kW today, potentially more) • Remote Tier 0-bis F. Hemmer talk Ian.Bird@cern.ch
Schedule Ian.Bird@cern.ch
October RRB • Two points to be addressed: • Scrutiny report of use of resources with experience of data • Plan to have a report with same details from each experiment • Discuss with chair of C-RSG at MB on Sep 7 • What should be said about requirements for 2013 • According to MoU process should have said something already • Very difficult to be precise without details of running conditions, and better analysis of how experience with data correlates with planning (TDR etc). Ian.Bird@cern.ch
Tier 3 resources • Formally Tier 3s are outside the scope of the WLCG MoU; but ... • May be co-located at a Tier 1 or 2 • Many Tier 3 sites coming: • Some are “Tier 2” but just not party to the MoU (yet...) – these are not a problem – treated in same way as a formal Tier 2 • Some just analysis but need to access data, so need to be grid aware (customer to grid services), need to be known to the infrastructure(s) • Strong statements of support for them from Experiment managements – they need these Tier 3s to be able to do analysis • Who supports them operationally? • Operational support: • In countries with a ROC (NGI ops, or equiv) – not a problem – ROC should support • What about non-ROC countries? Can we rely on the infrastructures? What is the process? • Come back to this in point on EGI-WLCG interactions Ian.Bird@cern.ch
Tier 3 issues – proposal • Want Tier 3s to be known and supported as clients... • They should not interfere with Tier 1,2 daily operations • Either because of overloading the Tier 1,2 • Or because of support load • No central support if the Tier 3 is really only a national analysis facility (i.e. Not for use of the wider experiment collaboration) • Issue: shared facility (e.g. Part of a cluster is Tier 2, part is for national use) • The part for national-only use should not be part of the pledge • How should this be accounted? (Should not be in principle, but in a shared cluster care needs to be taken) Ian.Bird@cern.ch
Evolution and sustainability • Need to adapt to changing technologies • Major re-think of storage and data access • Use of many-core CPUs (and other processor types?) • Virtualisation as a solution for job management • Brings us in line with industrial technology • Integration with public and commercial clouds • Network infrastructure • This is the most reliable service we have • Invest in networks and make full use of the distributed system • Grid Middleware • Complexity of today’s middleware compared to the actual use cases • Evolve by using more “standard” technologies: e.g. Message Brokers, Monitoring systems are first steps • But: retain the WLCG infrastructure • Global collaboration, service management, operational procedures, support processes, etc. • Security infrastructure – this is a significant achievement • both the global A&A service and trust network (X509) and • the operational security & policy frameworks Ian Bird, CERN
Service evolution strategy • Have started discussion on several aspects – • Data management: Kors Bos talk • Discussion in March, workshop in June, follow ups in GDBs (next week for the first) • Multi-core and virtualisation: PredragBuncic talk • 2nd workshop was held in June (1st was last year) • Long term: • Clarify the distinction between the WLCG distributed computing infrastructure and the software that we use to implement it • Understand how to make the grid middleware supportable and sustainable • Use of other components (e.g. Industrial messaging, tools like Nagios, etc); what does cloud technology bring us (and how to integrate/maintain our advantages – global trust, VOs, etc.) ? Ian.Bird@cern.ch