Download

1 / 19
190 likes | 297 Views
Macromolecular complexes – A new Online Portal (under construction!). Birgit Meldal (IntAct). Overview. Aims & Definitions Data Sources Issues and Challenges: Nomenclature Sets ‘Transient’ complexes GO Confidence scores Inference Visualisation Search Parameters and Filters

E N D
Macromolecular complexes – A new Online Portal (under construction!) Birgit Meldal (IntAct)
Overview • Aims & Definitions • Data Sources • Issues and Challenges: • Nomenclature • Sets • ‘Transient’ complexes • GO • Confidence scores • Inference • Visualisation • Search Parameters and Filters • Status quo
Project Aim • To design a Online Portal to search and visualise protein complexes • Including cross-referencing to source databases and beyond • Export to interested parties in a format of their choice • Incorporate the data into network analysis tools • To curate a ‘starter set’ of protein complexes for 4 major model organisms, chosen to span the taxonomic range – • Homo sapiens, Arabidopsis thaliana, Saccharomyces cerevisiae, Escherichia coli • Which will be expanded to a second set of organisms – • Musmusculus, Caenorhabditiselegans, Drosophila melanogaster, Saccharomycespombe • IntActprovides the data structure
Long-term Strategy • Create stable complex identifiers • Joined curation effort benefit to all collaborating databases: • Resource sharing • Elimination of redundancies benefit to user: • One central resource that links to all source databases
Definition: stable protein complexes A stable set (2 or more) of interacting protein molecules which • can be co-purified and • have been shown to exist as a functional unit in vivo. Non-protein molecules (e.g. small molecules, nucleic acids) may also be present in the complex. What is not a stable complex? • Enzyme/substrate or any similar transient interaction • Two proteins associated in a pulldown / coimmunoprecipitation with no functional link
Source Databases • Reactome – human (EBI), Gramene – arabidopsis, Microme – bacteria (EBI) • PDBe (EBI) – mainly human • ChEMBL (EBI) • MatrixDB (Sylvie Richard-Blum) • Mining UniProt – yeast (Bernd Roechert, SIB – manually) • Unmaintained web resources – CYGD (yeast), CORUM (human), E. coli website, 3D Complexes (Sarah Teichmann, EBI) • Manual curation from IMEx DBs & the literature (Sandra & Birgit)
Issues - • Currently, complexes are shoe-horned into an interaction which is part of a dummy publication and dummy experiment • New, complex-specific functionality, parameters and tools are needed
Issues - Nomenclature • Most complexes have no ‘common’ name, or the ‘common’ name is defined differently depending on authors or host organism. • One name can describe multiple complexes (e.g. AP1 describes ~25 different homo/heterodimers) • Reactome makes a string of all components by gene name but this can become too long for our short-label. • We will need both ‘recommended’ and ’systematic’ name. • List of synonyms already available as free-text. • Collaboration with GO, Reactome, HGNC
Issues – open/fuzzy sets • Complexes where the identity of one or more participants is unknown, i.e. participant(s) are only identified to a set of (related) proteins • Stoichiometry: often not known or ‘average’ (e.g. ion channel pore proteins) • Only sub-set of a given complex curated because functional assays often focus on interactions between catalytic subunits
Issues – indirect activation & transient complexes • Complexes that are activated without direct ligand interaction • e.g. through change of pH • transient interactions • Kim van Roey, Heidelberg: coorperative interactions • Different complex? Same participants!
Issues - Gene Ontology • Currently, complexes mostly children of GO:0043234 protein complex (> 400) – lacking hierarchal structure • Collaboration with GO to provide structured annotation • New terms should capture all potential complexes from all species for which a parental term is appropriate • E.g. DNA Polymerase complex • Needs to allow for (open) sets of proteins / protein families
Issues - Confidence • We need to define confidence scores: • Do we know all participants of the complex? • Do we have (open) sets of participants? • How do we indicate the depth of data available, i.e. compare Reactome import vs. manual curation? • e.g. using Evidence Code Ontology (ECO) • only qualitative description • Need a quantitative identifier
Issues – Inference data • Do we use inference/modelling data (e.g. Compara)? • Where is the cut-off for ‘model organisms’? • e.g. function remains but participants change
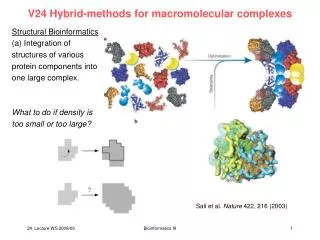
Issues – Visualisation • Flexible display of 2D and 3D options to capture complexity • The majority of complexes has 5 participants, average size 2.3 • For large complexes it needs to be dynamic: • use zoom-in/-out functionality on demand, • display only main participants or subcomplexes by default and expand on demand, • This might be achieved by assigning confidence scores to different levels of the complex by which it collapses/expands… • Most biological network packages, e.g. Cytoscape, not up to it • BioLayout 3D, ONDEX • For crystal structures link to PDB (e.g. BioJS widget)
Gene name in bubble with hyperlink to UniProtKB Bubble diagram Protein B Weak evidence of Ix Small Molecule Protein A Ix Ix Search for all Ix or Cx containing one or more of these participants Ix Hyperlink to IMEx Ix AC * Protein C ? Protein C * Protein D * Ix Ix Strong evidence of Ix * Need to query hyperlinks from whole database on the fly rather than having a static link to just one Ix Ix Unknown which participant is direct interactor Hyperlink to binding site (IMEx/InterPro) Ix = Interaction, Cx = Complex
Issues – Search Parameters Simple Search: • UniprotKB ID / protein name • Gene ID / name • Small molecule ID / name • InterProDomain • GO term • PMID • Complex ID / name • Drug Advanced Search Filters: • Stoichiometry • Binding sites • Biological role • Source DB • Host organism • Interactor type (protein, small mol., NA) • ECO • Process/Pathway • Stable vs. transient • Confidence score • Orthology • Disease • No. of participants • Already searchable • New search parameters • Most important new search parameter!
Status quo? • > 550 complexes already curated (Sandra, Bernd, Birgit), many imported (e.g. MatrixDB from Sylvie) • Exporter for Reactome working (David Croft) • PDB export under construction (Jose Dana) • ChEMBLxref list available (Yvonne Light) • Not all necessary features incorporated into Editor breaks release! • e.g. complexes can’t be participants • JAMI under construction (Marine!) • It’s a complex project which needs collaboration!!!
Acknowledgements Proteomics Services • Henning Hermjakob IntAct • Sandra Orchard • Marine Dumousseau • Noemi del Toro Ayllón • Rafael Jimenez • Pablo Porras • Margaret Duesbury SIB • Bernd Roechert MatrixDB • Sylvie-Ricard-Blum Reactome • Steve Jupe • David Croft ChEMBL • Anna Gaulton • Yvonne Light PDBe • Sameer Velankar • Jose Dana GO • Jane Lomax • Rachel Huntley • HeikoDietze