Download

1 / 1
10 likes | 135 Views
Rand Index close to 1. RapidMiner work flow. Summarization Based on a traditional statistic summarizer ( OTS ) Biases sentence selection using the information contained in a Domain Specific Dictionary The dictionary contains genes and proteins names and aliases

E N D
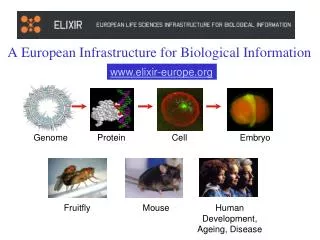
Rand Index close to 1 RapidMiner work flow. • Summarization • Based on a traditional statistic summarizer (OTS) • Biases sentence selection using the information contained in a Domain Specific Dictionary • The dictionary contains genes and proteins names and aliases • Grading function for sentence j in document i: Term frequency in document i, of a non stopword term k Number of distinct occurrences of dictionary term gn Weights the number of distinct dictionary term gn BioSumm Framework Architecture. Favours sentences that contain dictionary terms disregarding their number is in the range, is in the range BioSumm A novel summarizer oriented to biological information Elena Baralis, Alessandro Fiori, Lorenzo Montrucchio Politecnico di Torino • Preprocessing and Clustering • General purpose blocks • Preprocessing. • Parses the Pubmed Central xml inputs Removes xml tags and biologically irrelevant information • Represents the documents according to the Bag of words model using the Rapid Miner Text Plugin • Clustering. exploits the Bag of words representation and produces the clusters using the CLUTO software package Introduction The availability of increasingly wider text repositories requires effective techniques to manage the huge mass of unstructured information there contained (e.g., navigate, analyse and represent it in the most suitable way). Particularly, in the biological and biomedical domain a huge amount of information is daily generated and contributed by a vast research community spread all over the world. Repositories like PubMed Central, the U.S. National Institutes of Health (NIH) free digital archive of biomedical and life sciences journal literature, nowadays contain billions of documents. • Preliminary Experimental Results • Comparison with traditional summarizers • BioSumm sentences have the same expressive power of the traditional ones, but a strong focus on biology • Clustering Quality Evaluation • Rand index is used as metric • A Rand Index close to 1 means that the clustering block succeeded in the division by topic • Performance Evaluation • Measured in terms of completion times • Roughly linear trend with the number of documents PubMed Central Logo. • Aim • The BioSumm (Biological Summarizer) framework that analyses large collections of unclassified biomedical texts and exploits clustering and summarization techniques to obtain a concise synthesis, explicitly addressed to emphasize the text parts that are more relevant for the disclosure of genes (and/or proteins) interactions • The framework is designed to be flexible, modular and oriented to biological information • Researchers can exploit BioSumm for knowledge inference and biological validation of the interactions discovered in independent ways (e.g., by means of data mining techniques) BioSumm Logo. • Conclusions • BioSumm can summarize large collections of unstructured data by extracting the sentences • that are more relevant for knowledge inference and biological validation of gene/protein relationships • BioSumm has a strong focus on biology related sentences • Future Works • Extend the BioSumm approach to other summarization techniques (e.g., based on Latent Semantic Analysis) • Validate on other domains (e.g., financial) • Contact: • Alessandro Fiori(PhD Student) • Phone: 0039 011 090 7194 • Fax: 0039 011 090 7099 • Email: alessandro.fiori@ polito.it • Web: http://dbdmg.polito.it/ • Framework • Modular architecture composed by three blocks • Preprocessing.Extracts relevant parts of the original document and performs text stemming • Clustering. Divides rather diverse texts into homogeneous clusters, in which the documents cover the same topic • Summarization. It produces a summary for each cluster