Download

1 / 5
50 likes | 64 Views
Automating Document Review. Nathaniel Love CS 244n Final Project Presentation 6/14/2006. Document Review. Litigation cases, government investigations

E N D
Automating Document Review Nathaniel Love CS 244n Final Project Presentation 6/14/2006
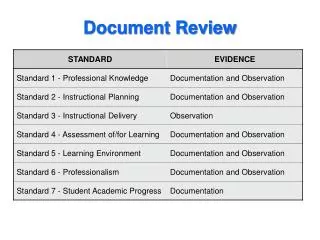
Document Review • Litigation cases, government investigations • Discoveryprocess: Company involved in case is compelled to produce documents (internal memos, financial statements, email) in response to a discovery request. • Company doesn’t want to release everything, only those documents that are • Responsive to the discovery request, and • Not privileged, meaning subject to protection under attorney-client privilege. • Company’s attorney must review all documents before they are produced. • In a large litigation case, this may be ~500,000 documents. Nathaniel Love
Classification Problem • 500,000 emails to review • Inspection by attorneys at ~100/hr, $275/hr • $1.375 million to pay for document review for 1 case • Improving this process • Each email must be classified as • Responsive / non-responsive • Privileged / non-privileged • As attorneys review, train 2 MaxEnt classifiers • Organize documents classified by partially trained classifiers. • Present sorted documents to attorneys, with suggested classifications. • Run trained classifier on all previously reviewed documents to check errors. Nathaniel Love
Feature Selection / Data • Emails: sender, recipient, date, words/word pairs in subject, presence/type of attachments… • Hand-built features: added based on concepts relevant to discovery request • Enron Corpus: solid match for data seen in actual document review process. • Test and training data drawn from hand-tagged Enron emails (work done by Berkeley group). • Mapped Berkeley categories into responsive/privileged categories based on FERC investigation into Enron (concerning manipulation of energy markets in western U.S.) • Issues • Small data set overall (1700 documents tagged out of over 600,000 in corpus) • Poor data for privilege classifier: tagged documents contain many fewer privileged emails than exist in the corpus overall Nathaniel Love
Results • Accuracy: • 75% (responsive) • 93% (privileged) • Accuracy improvedwith more training. • Positive feedback from attorneys on use of system, especially on the organization and presentation of documents by classifier as it trains. • Weights on features (responsive classifier) • david.parquet@enron.com (high positive weight) • nicholas.oday@enron.com (high negative weight) • David Parquet was Enron’s Vice President for project development in the western U.S. • Nicholas O’Day was Vice President at Enron Japan. Nathaniel Love