Download
1 / 20
200 likes | 418 Views
Tutorial 9. Sorting (3 rd part) & Hashing/Hash Table. Quick Sort. Key ideas: Partition (unsorted) list around a reference number (pivot) Left sub list will be smaller than pivot, right sub list will be larger (or equal) than pivot

E N D
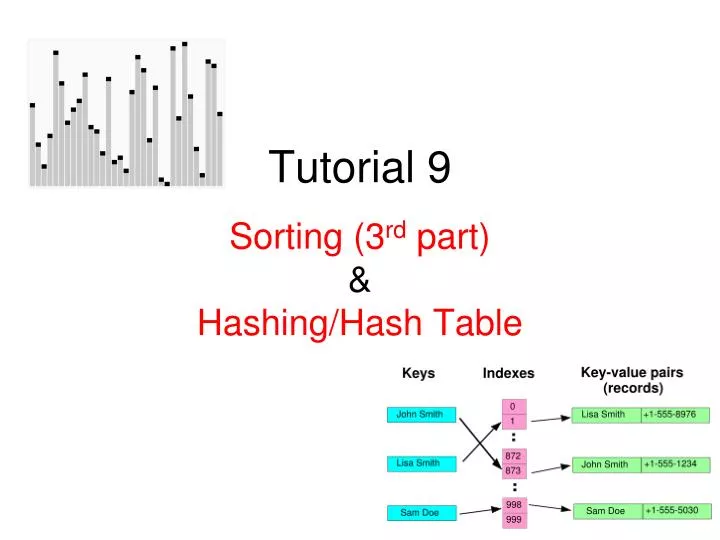
Tutorial 9 Sorting (3rd part) &Hashing/Hash Table
Quick Sort • Key ideas: • Partition (unsorted) list around a reference number (pivot) • Left sub list will be smaller than pivot, right sub list will be larger (or equal) than pivot • Item equal to pivot can be placed on left or right sub list, just be consistent! • After partitioning, pivot will definitely be in the correct place in sorted list • Partitioning algorithm is the most complex part of quick sort! • There are several partitioning algorithms out there, all are in O(n)! • Then, recursively process the left and right sub lists in the same manner • Do it until size = 1 (base case, by default 1 item is sorted) • It is on average O(n log n) too, if we use random pivot! • With random pivot, we can have better average performance • It can be faster than merge sort due to many reasons not discussed in CS1102 • Quick Sort will be discussed in Q1 and Q2
Student Presentation • Gr3 (average 2 times) • Cai Jingfang or Jessica Chin • Li Huanor Chng Jiajie • Jacob Pang or Nur Liyana Bte Roslie • Colin Tanor Tan Kar Ann • Gr4 (average 3 times) • Sherilyn Ng • Ahmed Shafeeq • Tan Miang Yeow • Melissa Wong and Sherilyn Ng Overview of the questions: • Trace Quick Sort (1 student) • Nuts and Bolts (1 student) • Hashing Schemes (1 student) • Hash Table (1 student) • Gr5 (average 4 times) • Wu Shujun • Wang Ruohan • Joyeeta Biswas • Ong Kian An • Gr6 (average 3 times) • Tan Ping Yang • Chow Jian Ann • Wong Shiang Ker • Kuganeswari
Q1: Trace Quick Sort • Pivot is always: first number in sub array. • Sort ascending
Q2: Nuts and Bolts • The problem is to match a collection of n nuts and n bolts by size. • It is assumed that for each bolt in the collection, there is a corresponding nut of the same size, but initially we do not know which nut goes with which bolt. • The differences in size between two nuts or two bolts can be too small to see by eye, you can only compare the sizes of a nut and a bolt by attempting to screw one into the other (assume this comparison is a constant time operation). • This “compare” operation tells you that either the nut is bigger than the bolt, or the bolt is bigger than the nut, or they are the same size (thus they match). • Naïve O(n2) solution is as follow: for each nut A (there are n nuts ~ O(n))for each bolt B (there are n bolts ~ O(n)) if nut A screws bolt B then take out this pair! • Propose a more efficient algorithm to solve the problem anddescribe your solution in pseudo code. • What is the time complexity of your algorithm?
Q2: Answer • Idea: • Since we have to compare bolts and nuts, why not “save” the information of which bolt is bigger than the current nut and put it in a pile, and for bolts which are smaller and put it in another pile. • The steps: • Take a bolt B, try to match this bolt B with all the nuts, and put the nuts into 2 piles which are either smaller or bigger than bolt B. There will be exactly 1 nut A that is equal to this bolt B, so we can pair these up. • Now, we know that approximately half the nuts are on the left and half the nuts are on the right. But what about the bolts? We also have to split the bolts into piles corresponding to the 2 piles of nuts! • But how do we do that? Simple, since we have found the nut A that is equal to the bolt B, we can determine which pile the bolts should go to by comparing each bolt with the nut A (reverse the process, just now you pick bolt B and sort the nuts, now you pick nut A and sort the bolts)! • We can now work on the two smaller piles.This is exactly the same problem as what we have initially, but just smaller (recursion applies)! • This whole idea is just a quick sort algorithm! • The random bolt B that you choose in step 1 and the corresponding nut A in step 3 are the pivots! • On average, this will be O(2*n log n) = O(n log n) and in worst case O(n2). • The worst case is very unlikely to happen as the pivot is chosen randomly.
BST - Recap • Last week, we have learnt: • Binary Search Tree • BST is used to implement ADT Table (extension of ADT List) • Basic Table operations: • Insert • Search • Delete • In balanced BST, these operations are done in O(log2 n) • Can we do better?
Today - Hash Table • Hash Table is also an ADT Table • It supports basic Table operations: • Insert • Search • Delete • Advertised time per operation is expected to be O(1), wow… • However, there are special requirements to achieve this (the fine print…) • We must have hashing functions that minimizecollisions… • We must set the table size properly to ensure load factor is not too high • Too many collisions will make “O(1) > O(log2 n)” • Anyway, O(1) and O(log2 n) do not differ “that much”…
Direct Addressing • Easiest Table: Direct Addressing • e.g. key: Bus Number, data: that Bus itinerary • Problem: not practical • The range of keys is too big • The keys may be non integers • To address these issues, we use hashing
Hash Function • Hashing maps keys from: • Large range of integers into smaller range of integers • Non integer into small range of integers • Problem: collisions • Two keys can have the same hash value • Collisions are inevitable*, see: • “Birthday Paradox” (Probability Theory) • Can be tested: write down your birthday in the attendance sheet… • See if this birthday paradox is true… • “Pigeonhole Principle”
Hash Function Good hash function: Characteristics: Minimize collisions Fast Deterministic Distribute keys evenly in the range Usually in form of: H1(key) = key % m, H2(key) = 1+key%(m-1) m = table size Choice of m Not 10n, because the hash values is the last n digits of keys Not 2n, as key % of m is the last n bits of the key Usually a prime close to power of 2 Perfect Hash Function Keys are mapped to unique indices Hard to attain Uniform Hash Function Keys are distributed uniformly Desirable
Q3: Hashing Schemes (Answer) • 1. Most English words are short (10 letters or less)http://en.wikipedia.org/wiki/Longest_word_in_English,so most of the keys will be less than 10 * 26 = 260,which would result in many collisions, filling the first 260 out of 2047 cells.2. Words with the same letters will be hashed to the same value,e.g. h(“post”) = h(“stop”) = h(“spot”).3. Table size is too small to hold thousands English words… • 1. Many email addresses have the same domain names,and they will all be hashed to the same value e.g. “nus.edu.sg”.2. The size of the hash table is a power of 2. • This function does not work because we cannot reproduce the random value to retrieve the element once it is inserted into the hash table. • 1. The value returned may exceed 65534: it should return value % 65535.2. Since the elements can be as high as 1000000,it may take 1000000 iterations to generate the hash value. This is too slow!
Collision Resolutions • Separate Chaining • Use Linked List • Harder to implement • It takes bigger memory space for storing Linked List pointers • Open Addressing, usually better than Chaining • Linear Probing • Quadratic Probing • Double Hashing
Open Addressing Technique • Linear Probing: • H(key) = (H1(key) + i * 1)%m • Quadratic Probing: • H(key) = (H1(key) + i * i)%m • Double Hashing: • H(key) = (H1(key) + i * H2(key))%m • i = probing sequence • i = 0, no probing/2nd hash function is not used • i = 1, 1st probe • i = 2, 2nd probe, etc
Q4: Hash Table (1) • Table size = 9, hash function: h(x) = (x+1)%9, linear probing • h(34) = 35%9 = 8 • h(67) = 68%9 = 5 • h(12) = 13%9 = 4 • h(90) = 91%9 = 1 • h(37) = 38%9 = 2 • h(82) = 83%9 = 2 (collide with 37) 2+1*1 = 3 • h(22) = 23%9 = 5 (collide with 67) 5+1*1 = 6
Q4: Hash Table (2) • Table size = 10, hash function = h(x) = (x-1)%10, quadratic probing • h(34) = 33%10 = 3 • h(67) = 66%10 = 6 • h(12) = 11%10 = 1 • h(90) = 89%10 = 9 • h(37) = 36%10 = 6 (collide with 67) 6+1*1 = 7 • h(82) = 81%10 = 1 (collide with 12) 1+1*1 = 2 • h(22) = 21%10 = 1 (collide with 12) 1+1*1 = 2 (collide with 82) 1+2*2 = 5
Q4: Hash Table (3) • Table size = 11, hash function: h(x) = x%11,double hashing with the 2nd hash function: h2(x)=7-x%7 • h(34) = 34%11 = 1 • h(67) = 67%11 = 1 (collide with 34), h2(67) = 7-67%7 = 3 1+1*3 = 4 • h(12) = 12%11 = 1 (collide with 34), h2(12) = 7-12%7 = 2 1+1*2 = 3 • h(90) = 90%11 = 2 • h(37) = 37%11 = 4 (collide with 67), h2(37) = 7-37%7 = 5 4+1*5 = 9 • h(82) = 82%11 = 5 • h(22) = 22%11 = 0
Example of a Good Hash Table • “English” Dictionary* • We know that number of words ~ 1.000.000 (from Google Search) • Log2 (1.000.000) ~ 20 • Using Balanced BST, we need at most 20 steps for insert/search/delete • However, this dictionary is seldom updated! (Insert new entry/Delete old entry) • So, if we use a good hash table with • Table size 1.500.000 (thus load factor ~70%), and • Good hash functions to map short strings to integer (+ double hashing), • We may be able to search a word in much less than 20 steps… • Good hash table with load factor 70% typically requires ~2 steps, O(2) ~ O(1) • (Much?) better than O(20)
Additional Reference • http://en.wikipedia.org/wiki/Hash_table • http://en.wikipedia.org/wiki/Birthday_paradox • How many people are required to be inside one room such that there is 50% chance that a pair in that room share the same birthday… • Answer: 23 people only, much less than 365/2 = 180 people • How many people are required to be inside one room such that there is 50% chance that a pair in that room share the same birth WEEK (+- 7 days from the actual birthday)? • Answer: 7 people :O, much less than 52/2 = 26 people • http://en.wikipedia.org/wiki/Pigeonhole_principle • if n pigeons are put into m pigeonholes, and if n > m, then at least one pigeonhole must contain more than one pigeon. • Another way of stating this would be thatm holes can hold at most m objects with one object to a hole;adding another object will force you to reuse one of the holes.
Food for Thought One compartment only?Don’t buy! • Ladies Bag >.< • Actually this idea is also applicable to many other things in life,but I use specific example for clarity… • Somehow, ladies bag has only? one big compartment • This confuses the ladies when she tries to find an item inside this bag,e.g. her hand phone or EZ Link, especially under time pressure (at the bus)! • I have seen several cases where several ladies frantically searching forher EZ Link (which is inside her wallet in her bag) in front of SBS/SMRT bus. • This annoys the other passengers… • They have hard time because they are NOT using proper Hashing schemes! • Suggestion for ladies • Buy a bag with many (I suggest ~7) compartments! • Devise a simple (easy to memorize), consistent (not random) hashing scheme! • e.g. put wallet in inside left (to avoid pickpocket), put hand phone on inside right, put your tissues on front left, EZ link card on front right (if you just want to tap your bag, TAP THIS SIDE!), etc. • Now, you have just simplify your life and reduce annoyance to others near you. • O(1) time to search anything in your bag