Download
1 / 16
160 likes | 332 Views
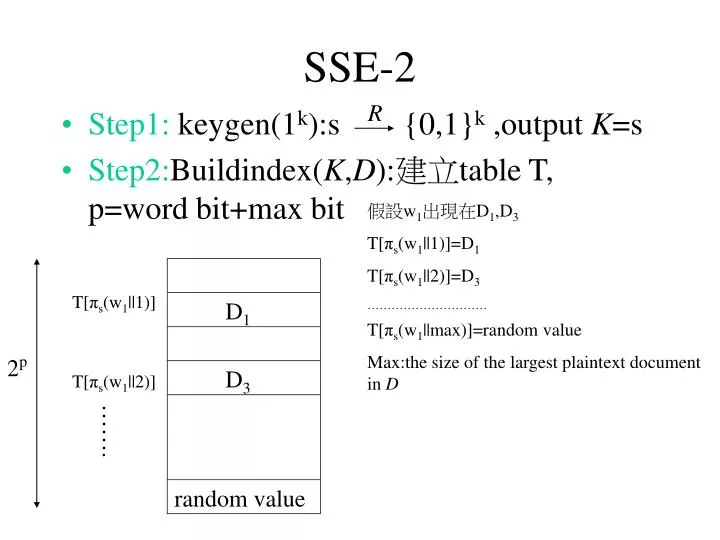
SSE-2. R. Step1: keygen(1 k ):s {0,1} k ,output K =s Step2: Buildindex( K , D ): 建立 table T, p=word bit+max bit. 假設 w 1 出現在 D 1 ,D 3 T[ π s (w 1 ||1) ]=D 1 T[ π s (w 1 ||2)]=D 3 ………………………… T[ π s (w 1 ||max)]=random value Max:the size of the largest plaintext document in D.

E N D
SSE-2 R • Step1: keygen(1k):s {0,1}k ,output K=s • Step2:Buildindex(K,D):建立table T, p=word bit+max bit 假設w1出現在D1,D3 T[πs(w1||1)]=D1 T[πs(w1||2)]=D3 ………………………… T[πs(w1||max)]=random value Max:the size of the largest plaintext document in D T[πs(w1||1)] D1 2p D3 T[πs(w1||2)] ……. random value
m=max‧n , n is the number of document in D m'= ∑wi△'|D(wi)| if m'< m , set value for the (m-m') entries Output I = T Step3:Trapdoor(w):output Tw=(Tw1…Twmax) =(πs(w||1),…, πs(w||max)) Step4:Search(I,Tw):for 1≤i≤max:retrieve id=T[Twi] and output id T大小:{0,1}p*{0,1}log2(n)*m (作者算法) (π:{0,1}k*{0,1}p {0,1}p)
SSE model • History: documents and keywords • View: encrypted documents, index, trapdoors • Trace: length of documents, search outcomes, search pattern
一些符號定義 • Let △= {w1, . . . ,wd} be a dictionary of d words, and 2△ be the set of all possible documents. • let D ⊆2 △be a collection of n documents D= (D1, . . . ,Dn) and 2 2△ be the set of all possible document collections. Let id(D) be the identifier of document D • D(w) (the set of identifiers of documents containing w) as the outcome of a search for w and to the sequence (D(w1), . . . ,D(wn)) as the access pattern of a client
SSE-2證明 • 定義1(History):Let △ be a dictionary. A history Hq, Hq22△ ×△q, is an interaction between a client and a server over q queries. The partial history Hqt 22△ ×△t of a given history Hq = (D, w1, . . . ,wq), is the sequence Hqt = (D, w1, . . . ,wt), where t ≤ q.
定義2(View):Let D be a collection of n documents and Hq = (D, w1, . . . ,wq) be a history over q queries. An adversary’s view of Hq under secret key K is defined as VK(Hq) =(id(D1), . . . ,id(Dn),ε(D1), . . . ,ε(Dn),ID,T1, . . . ,Tq). The partial view VKt(Hq) of a history Hq under secret key K is the sequence VKt(Hq)=(id(D1), . . . ,id(Dn),ε(D1), . . . ,ε(Dn), ID,T1, . . . ,Tt), where t ≤ q.
定義3(Trace):Let D be a collection of n documents and Hq = (D, w1, . . . ,wq) be a history over q queries. The trace of Hq is the sequence Tr(Hq) = (id(D1), . . . ,id(Dn), |D1|, . . . ,|Dn|,D(w1), . . . ,D(wq), ∏q). Note:∏q can be a symmetric binary matrix where ∏q[i,j]=1 if wi=wj and ∏q[i,j]=0 otherwise,for 1 ≤ i,j ≤ q
定義3.9(Adaptive Semantic Security for SSE). A SSE scheme is adaptively semantically secure if for all q N and for all (non-uniform) probabilistic polynomial-time adversaries A, there exists a (non-uniform) probabilistic polynomial-time algorithm (the simulator) S such that for all traces Trq of length q, all polynomially samplable distributions q over {Hq 22△ ×△q : Tr(Hq) = Trq} (i.e., the set of histories with trace Trq), all functions f : {0, 1}m→ {0, 1}l(m) (where m =|Hq| and l(m) = poly(m)), all 0 ≤ t ≤ q and all polynomials p and sufficiently large k:
where Hq q , K←Keygen(1k), and the probabilities are taken over Hq and the internal coins of Keygen, A, S and the underlying BuildIndex algorithm. • 定理.SSE-2 is an adaptively secure SSE scheme. • Proof:The idea behind the proof is to describe a simulator that can simulate the partial view of an adversary given only the trace of a partial history.
Following the simulation-based approach of Definition 3.9, we describe a probabilistic polynomial-time simulator S such that for all q N, all probabilistic polynomial-time adversaries A, all polynomially-bounded functions f, all distributions q, given Tr(Hqt), S can simulate A(VKt(Hq)) for all 0 ≤ t ≤ q with probability negligibly close to 1,where Hq q , K←Keygen(1k). More precisely, we show that, for all 0 ≤ t ≤ q , S(Tr(Hqt)) can generate a view (Vqt)* such that (Vqt)* is indistinguishable from VKt(Hq).
In the SSE-2 construction, for each word, the labels in the word’s family(ex:Fw={w || j:1 ≤ j≤|D(w)|})are inserted into the index and each label appears in only one document. Searching for a word consists of searching for max labels in its family. Before proceeding further, we recall that the parameters of the pseudo-random permutation used to instantiate the scheme are known to S. Also, recall the notions of a view and of a trace in the context of the SSE-2 construction:
For a given q, the simulator must commit to an index before any queries are made, i.e. at time t = 0 the simulator generates an index I* that will be included in all partial views (Vqt)* used to simulate A, for all 0 ≤ t ≤ q. Note that although at time t = 0 the simulator has no knowledge about future queries, the index I*must be indistinguishable from a real index ID in VKt(Hq), for all 0 ≤ t ≤ q.
Also, for all 0 ≤ t ≤ q , the simulator includes in the partial view (Vqt)*the document identifiers (which it knows from the trace of the partial history Tr(Hq0)) and ciphertexts obtained by generating random values (of size known from Tr(Hq0)). It follows trivially that the identifiers and ciphertexts in (Vqt)* are indistinguishable from those in VKt(Hq), for all 0 ≤ t ≤ q . It then remains to show how S constructs the other elements in the view, namely the index and the trapdoors.
For t = 0, the simulator’s trace on the partial history Tr(Hq0) contains among other things, the identifiers of each document in the collection. S constructs (and includes in (Vq0)*) the index I* as a ({0, 1}p × {0, 1}log2(n) × m) look-up table T*, where m = max · n and T* contains max copies of each document’s identifier inserted at random locations. S keeps a copy of I* in order to be able to simulate future partial views for 1 ≤ t ≤ q. Given the algorithm used to construct a realindex I included in the partial view VK0(Hq), it is clear that I* is indistinguishable from I, otherwise one could distinguish between the output of and a random string of size p. Thus, (Vq0)* is indistinguishable from Vk0 (Hq).For 1 ≤ t ≤ q, the simulator includes in the partial view (Vqt)* the index I* which was computed for t = 0 and which was established above to be indistinguishable from a real index I in a partial view VKt (Hq).Recall that I* consists of a look-up table T* and that Tr(Hqt) contains the search pattern matrix ∏ for the t queries in Tr(Hqt).
We describe how S constructs the trapdoors (T1* , . . . , Tt*) included in (Vqt)*. S reuses the trapdoors (T1* , . . . , Tt−1*) that were included in (Vqt−1)* (We assume that S remembers (Vqt−1)* and can reuse the trapdoors in it; alternatively, S can reconstruct these trapdoors from Tr(Hqt−1), one by one in the same manner we will show how to construct Tt* from D(wt) and ∏). To construct Tt*, S first checks if Hqt−1 contains wt (by checking if ∏tj = 1 for any 1 ≤ j ≤ t − 1). If negative, then for each label wt||i, with 1 ≤ i ≤ max, S randomly picks an address addri from T* such that T*[addri] = D(wt||i), and constructs trapdoor Tt* = (addr1, . . . , addrmax).Also, S remembers the association between Tt* and wt. Otherwise, if Hqt−1 contains wt, then S retrieves the trapdoor associated with wt and assigns it to Tt*.
This ensures that if Hqt contains repeated words, the corresponding trapdoors included in (Vqt)* are identical. • It’s easy to see that the trapdoors (T1* , . . . , Tt*) in (Vqt)* are indistinguishable from the trapdoors (T1, . . . , Tt) in VKt(Hq), otherwise one could distinguish between the output of and a random string of size p. Thus, (Vqt)* is indistinguishable from VKt(Hq), for all 0 ≤ t ≤ q.