Download

1 / 17
170 likes | 192 Views
Explore the importance of R-trees in handling spatial and multidimensional data in database systems such as CAD, GIS, and Cartography. Learn about the structure, search queries, concurrency, and algorithms involved in R-trees. Discover the innovative R-link tree solution for concurrent operations.

E N D
Concurrent R-trees Mehdi Kargar Department of Computer Science and Engineering
Motivation • Handling spatial and multidimensional data are very important in modern database systems • Applications : • CAD (Computer Aided Design) • GIS (Geographical Information Systems) • Cartography and … • Classical indexing structures such as B-Tree are not suitable for handling multidimensional data • They use only one dimensional indexing structures
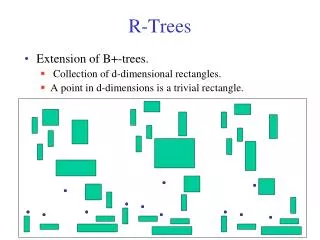
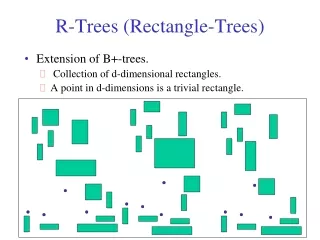
Motivation • R-tree is one of the best structures for indexing multidimensional data. • Despite of other multi-dimensional structures, R-tree directly stores multidimensional spatial objects. • Spatial objects are represented by their minimal bounding box
R-trees • An R-tree is a depth balanced tree with a dynamic index structure • Leaf nodes point to actual keys • The number of entries in a node is between m and N (1 < m ≤ N) • Root might have between 1 and N entries. • All leaf nodes areat the same level • The key for each internal node is the minimum bounding rectangle of its child nodes
R-trees Search Query
R-trees • keys at all levels might have overlap with each other • During the search for a key, it might be necessary to descend multiple sub-trees • Insertion is more complex than search • After inserting a new key, the new bounding rectangle should be propagated up to the tree. • If a node overflows, it should be split. The split should also be propagated up to the tree. • Deletion is a combination of methods used in search and insertion algorithms.
A counter example • The naïve approach to concurrent operations on R-trees are not correct, R-link tree solves the problem. (search for R5 and insertion of R2)
R-link tree • An R-link tree is like a normal R-tree with two basic modifications. • All of the nodes in any level of the tree are connected together in a link list via right links (first applied on B-trees) • Addition of an LSN (Logical Sequence Number) in each node and each parent entry which is unique within the tree. It is used to produce a linear ordering of the spatial keys.
R-link tree • Unfinished splits can be captured by comparing the LSN of parent entry and its child node • c1 , c4 , c5 → normal situation • c2 , c3 → unfinished split situation
The Search Algorithm • Since keys might overlap, multiple sub-trees might navigated for a single search. • An Stack is used to remember which node is waiting to be visited. • The LSN of each entry is also pushed into the stack. • If the LSN of the node is higher than the one on the stack, then the node has been split in the meantime. • All of the nodes to the right of it, up to and including the node with the LSN equal to the expected LSN is pushed onto the stack.
The Insertion Algorithm • The insertion algorithm consists of three phases • Finding the optimal leaf node for inserting the new key. • If the leaf node overflows and splits, the split should be propagated to upper levels. • if the bounding rectangle of the leaf node changes, the new bounding rectangle should be propagated to upper level
The Insertion Algorithm • The path from the root to the leaf node should be stored in an stack. • Backing up on this path to install the changes (split and bounding rectangle) to the tree. • Using lock coupling strategy: • For manipulating the parent node, the child nodes remain write locked until a write locked is obtained from the parent.
The Deletion Algorithm • Using the combination of methods in search and insertion algorithms. • Three phases: • Finding the leaf node containing the key. • Removing the entry from the node. • If the bounding rectangle of the leaf node changes, it should propagated up to the tree. • For improving the performance of the tree operations, empty nodes can be removed from the tree.
Refrences • 1 - M. Kornacker and D. Banks. High-concurrency locking in r-trees. In Proceedings of the 21th International Conference on Very Large Data Bases, pages 134-145. ACM, 1995. • 2 - P. L. Lehman and S. B. Yao. Efficient locking for concurrent operations on B-trees. ACM Transactions on Database Systems, 6(4):650-670, December 1981.