Download

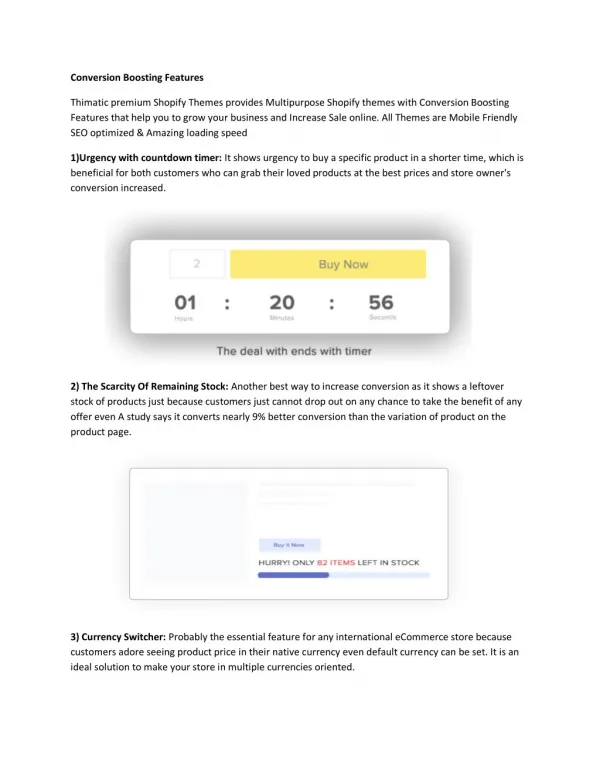
1 / 59
590 likes | 720 Views
Shared features and Joint Boosting. Sharing visual features for multiclass and multiview object detection A. Torralba, K. P. Murphy and W. T. Freeman PAMI. vol. 29, no. 5, pp. 854-869, May, 2007. Yuandong Tian. Outline. Motivation to choose this paper Motivation of this paper

E N D
Shared features and Joint Boosting Sharing visual features for multiclass and multiview object detectionA. Torralba, K. P. Murphy and W. T. Freeman PAMI. vol. 29, no. 5, pp. 854-869, May, 2007. Yuandong Tian
Outline • Motivation to choose this paper • Motivation of this paper • Basic ideas in boosting • Joint Boost • Feature used in this paper • My results in face recognition
Motivation to choose this paper Axiom: Computer vision is hard. Assumption: (smart-stationary) Equally smart people are equally distributed over time. Conjure: If computer vision cannot be solved in 30 years, it won’t be solved forever!
Wrong! Because we are standing on the Shoulder of Giants.
Where are the Giants? • More computing resources? • Lots of data? • Advancement of new algorithm? • Machine Learning? What I believe
Cruel Reality Why ML seems not to help much in CV (at least for now)? My answer: CV and ML are weakly coupled
A typical question in CV Q: Why do we use feature A instead of feature B? A1: Feature A gives better performance. A2: Feature A has some fancy properties. A3: The following step requires the feature to have a certain property that only A has. A strongly-coupled answer
Typical CV pipeline Preprocessing Steps (“Computer Vision”) Feature/Similarity ML black box Have some domain-specific structures Design for generic structures
Contribution of this paper • Tune the ML algorithm in a CV context • A good attempt to break the black box and integrate them together
Outline • Motivation to choose this paper • Motivation of this paper • Basic ideas in boosting • Joint Boost • Feature used in this paper • My results in face recognition
This paper • Object Recognition Problem • Many object category. • Few images per category • Solution—Feature sharing • Find common features that distinguish a subset of classes against the rest.
Feature sharing Concept of Feature Sharing
Typical behavior of feature sharing Template-like features 100% accuracy for a single object But too specific. Wavelet-like features, weaker discriminative power but shared in many classes.
Why feature sharing? • ML: Regularization—avoid over-fitting • Essentially more positive samples • Reuse the data • CV: Utilize the intrinsic structure of object category • Use domain-specific prior to bias the machine learning algorithm
Outline • Motivation to choose this paper • Motivation of this paper • Basic ideas in boosting • Joint Boost • Feature used in this paper • My results in face recognition
Basic idea in Boosting • Concept: Binary classification • samples, labels(+1 or -1) • Goal: Find a function (classifier) H which • maps positive samples to the positive value • Optimization: Minimize the exponential loss w.r.t the classifier H
Basic idea in boosting(2) • Boosting: Assume H is additive • Each is a “weak” learner (classifier). • Almost random but uniformly better than random • Example: • Single feature classifier: make decision only on a single dimension
How weak learner looks like Key point: The addition of weak classifiers gives a strong classifier!
Basic idea in boosting(3) • How to minimize? • Greedy Approach • Fix H, add one h in each iteration • Weighting samples • After each iteration, wrongly classified samples (difficult samples) get higher weights
Technical parts • Greedy -> Second-order Taylor Expansion in each iteration weights The weak learner to be optimized in this iteration labels Solved by Least Square
Outline • Motivation to choose this paper • Motivation of this paper • Basic ideas in boosting • Joint Boost • Feature used in this paper • My results in face recognition
Joint Boost—Multiclass • We can minimize a similar function using one-vs-all strategy • This doesn’t work very well, since it is separable in c. • Put constraints. -> shared features!
Joint Boost (2) • In each iteration, choose • One common feature • A subset of classes that use this feature • So that the objective decreases most
Sharing Diagram #Iteration #class I II III IV V Features 1 3 4 5 2 1 4 6 2 7 3
Key insight • Each class may have its own favorite feature • a common feature may not be any of them, however it simultaneously decreases errors of many classes.
Computational issue • Choose the best subset is prohibitive • Use greedy approach • Choose one class and one feature so that the objective decreases the most • Iteratively add more classes until the objective increases again • Note the common feature may change • From O(2^C) to O(C^2)
#features = O(log #class) (greedy)
0.95 ROC 29 objects, average over 20 training sets
Outline • Motivation to choose this paper • Motivation of this paper • Basic ideas in boosting • Joint Boost • Feature used in this paper • My results in face recognition
Feature they used in the paper • Dictionary • 2000 random sampled patches • Of size from 4x4 to 14x14 • no clustering • Each patch is associated with a spatial mask
The candidate features position template Dictionary of 2000 candidate patches and position masks, randomly sampled from the training images
Features • Building feature vectors • Normalized correlation with each patch to get response • Raise the response to some power • Large value gets even larger and dominate the response (max operation) • Use spatial mask to align the response to the object center (voting) • Extract response vector at object center
Results • Multiclass object recognition • Dataset: LabelMe • 21 objects, 50 samples per object • 500 rounds • Multiview car recognition • Train on LabelMe, test on PASCAL • 12 views, 50 samples per view • 300 rounds
12 views 50 samples per class 300 features
Outline • Motivation to choose this paper • Motivation of this paper • Basic ideas in boosting • Joint Boost • Feature used in this paper • My results in face recognition
Simple Experiment • Main point of this paper • They claimed shared feature helps in the situation of • many categories, only a few samples in each category. • Test it! • Dataset: face recognition • “Face in the wild” dataset. • Many famous figures
Experiment configuration • Use Gist-like feature but • Only Gabor response • Use finer grid to gather histogram • Face is aligned in the dataset. • Feature statistics • 8 orientation, 2 scale, 8x8 grid • 1024 dimension