Download

1 / 23
230 likes | 345 Views
Scheduler tutorial. Gabriele Carcassi STAR Collaboration. Why use the scheduler?. Allows the distributed disk model MuDST are now resident on the local disk of each node I/O performance more space available for data files Allows us to change implementation

E N D
Scheduler tutorial Gabriele Carcassi STAR Collaboration
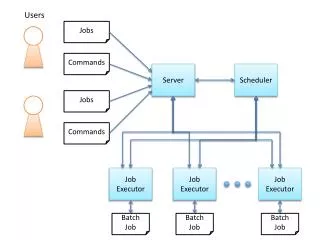
Why use the scheduler? • Allows the distributed disk model • MuDST are now resident on the local disk of each node • I/O performance • more space available for data files • Allows us to change implementation • migrate to GRID tools while keeping the user interface unchanged
Why use the scheduler? • Easy to use • No more scripts to write • Don’t have to keep track where the data files are located • You just write a small XML file to dispatch hundreds of jobs
An example • We want to execute a root macro on all the MuDST with minbias trigger and collision deuteron-Gold at 200 GeV • The output of our macro will be a root file containing a histogram
// create the chain StChain * chain = new StChain("StChain"); chain->SetDebug(0); // now add your analysis maker SchedulerExample* analysis = new SchedulerExample(outFile); // Init the chain chain->Init(); // This calls the Init() method in ALL makers chain->PrintInfo(); The macro void SchedulerExample(const char* fileList, const char* outFile) { load(); Among the input parameters of the macro there is the filelist (that is the name of a file containing a list of input files on which the macros will operate) and the output file in which the histogram will be saved Then we prepare the chain We give the output filename to our analysis maker
The macro // now create StMuDstMaker // agruments are: // 0 : read mode // 0 : name mode (has no effect on read mode) // "" : input directory, ignored when filename or fileList is specified // fileList : list of files to read // "" : filter // 1e9 : maximum number of files to read // MuDstMaker : name of the maker StMuDebug::setLevel(0); StMuDstMaker* muDstMaker = new StMuDstMaker(0,0,"",fileList,"",10,"MuDstMaker"); We create the MuDstMaker, giving the fileList as a parameter
The macro Finally we loop over the events and we clean the chain int iret = 0; int iev =0; // now loop over events, makers are call in order of creation while ( !iret ) { cout << "SchedulerExample.C -- Working on eventNumber " << iev++ << endl; chain->Clear(); iret = chain->Make(iev); // This should call the Make() method in ALL makers } // Event Loop chain->Finish(); // This should call the Finish() method in ALL makers }
The Job description • We write an XML file with the description of our request <?xml version="1.0" encoding="utf-8" ?> <job maxFilesPerProcess="500"> <command>root4star -q -b rootMacros/numberOfEventsList.C\(\"$FILELIST\", \"$SCRATCH/dAu200_MC_$JOBID.root\"\)</command> <stdout URL="file:/star/u/carcassi/scheduler/out/$JOBID.out" /> <input URL="catalog:star.bnl.gov? collision=dAu200,trgsetupname=minbias,filetype=MC_reco_MuDst" preferStorage="local" nFiles="all"/> <output fromScratch="*.root" toURL="file:/star/u/carcassi/scheduler/out/" /> </job>
<?xml version="1.0" encoding="utf-8" ?> An XML file has to begin like this <job maxFilesPerProcess="500"> Starts describing a job. (MaxFilesPerProcess tells the scheduler that each job submittited to LSF can have 500 file at maximum – more clear later) <command>root4star -q -b rootMacros/numberOfEventsList.C\(\"$FILELIST\", \"$SCRATCH/dAu200_MC_$JOBID.root\"\)</command> The command line to be executed. Notice that we pass $FILELIST as the fileList and $SCRATCH/dAu200_MC_$JOBID.root as output file The Job description • Let’s look at it carefully
<stdout URL="file:/star/u/carcassi/scheduler/out/$JOBID.out" /> We specify where do we want our standard output to be redirected. Notice that the file is a URL, and that the name includes again $JOBID. We will explain why later. <input URL="catalog:star.bnl.gov? collision=dAu200,trgsetupname=minbias,filetype=MC_reco_MuDst" preferStorage="local" nFiles="all"/> Here we specify the input of our analysis. There can be more than one input, and they can be files, wildcards or file catalog query. This is a query asking for all the MuDST with minbias trigger and collision deuteron- Gold at 200 GeV The Job description
<output fromScratch="*.root" toURL="file:/star/u/carcassi/scheduler/out/" /> Here we specify the output produced by our job. We copy all the files that end in .root to a specified directory using a URL. </job> This closes the description of the job. The Job description
Submitting your job • Having your job description, you now just need to type:
What has the scheduler done? • In the directory where you run star-submit you will see lots of .csh and .list files • If you execute bjobs, you will see many jobs submitted for you • From the single job description the scheduler has: • created many processes • assigned an input file list • dispatched them to LSF • How is this done?
sched1043250413862_0.list Query/Wildcard resolution /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... ... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... ... sched1043250413862_1.list /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... ... sched1043250413862_2.list /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... /star/data09/reco/productionCentral/FullFie... ... Dividing the input files Job description test.xml <?xml version="1.0" encoding="utf-8" ?> <job maxFilesPerProcess="500"> <command>root4star -q -b rootMacros/numberOfEventsList.C\(\"$FILELIST\"\)</command> <stdout URL="file:/star/u/carcassi/scheduler/out/$JOBID.out" /> <input URL="catalog:star.bnl.gov?production=P02gd,filetype=daq_reco_mudst" preferStorage="local" nFiles="all"/> <output fromScratch="*.root" toURL="file:/star/u/carcassi/scheduler/out/" /> </job>
Dividing the input files • Every process will receive a different input file list • $FILELIST will be different for each process • The list is divided according to how the files are distributed on the nodes of the farm, and on the maxFilesPerProcess limit set • $FILELIST is the filename for a text file that contains a list of files (one for each line)
sched1043250413862_0.csh Output files #!/bin/csh # ------------------- # Script generated at Wed Jan 22 ... # bsub -q star_cas_dd -o /star/u/carca... # ------------------- ... sched1043250413862_1.csh Output files #!/bin/csh # ------------------- # Script generated at Wed Jan 22 ... # bsub -q star_cas_dd -o /star/u/carca... # ------------------- ... sched1043250413862_2.csh Output files #!/bin/csh # ------------------- # Script generated at Wed Jan 22 ... # bsub -q star_cas_dd -o /star/u/carca... # ------------------- ... Processes and their outputs Job description test.xml <?xml version="1.0" encoding="utf-8" ?> <job maxFilesPerProcess="500"> <command>root4star -q -b rootMacros/numberOfEventsList.C\(\"$FILELIST\"\)</command> <stdout URL="file:/star/u/carcassi/scheduler/out/$JOBID.out" /> <input URL="catalog:star.bnl.gov?production=P02gd,filetype=daq_reco_mudst" preferStorage="local" nFiles="all"/> <output fromScratch="*.root" toURL="file:/star/u/carcassi/scheduler/out/" /> </job>
Processes and their outputs • All the jobs are automatically dispatched to LSF • The output of each process must be different • If two processes would write on the same file, one would overwrite the other • One quick way is to use the $JOBID (which is different for every process) to generate unique names
Environment variables • The scheduler uses some environment variables to communicate to your job • $FILELIST is the name of a file containing the input file list for the process • $INPUTFILECOUNT tells you how many files where assigned to the process • $INPUTFILExx allows you to iterate over the file names in a script • $JOBID gives you a unique identifier composed of two parts: the request id and the process number (es. 1043250413862_0).
Environment variables • More variables • $SCRATCH is a temporary directory for a single process located on the node the process will be executing. You should write your output here, and let the scheduler retrieve it for you • You can pass the variables to your macro • In the example we passed the $FILELIST and we built the output filename with $SCRATCH and $JOBID
Input from a catalog query • The best way to specify the input is through a file catalog query • you don’t have to worry where the files are • it will work both at BNL and at PDSF • The file catalog has a lot of attributes to select your files • collision, trgname, library, production, runtype, magvalue, configuration, ... • You can get familiar with the file catalog by using the get_file_list command. The –cond paramater is the one passed to the scheduler. • <input URL="catalog:star.bnl.gov?production=P02gd, filetype=daq_reco_mudst" preferStorage="local" nFiles="all"/>
What changes are requiredto my analysis code? • The macro must take the filelist as an argument • The macro must write on different output files for different execution • use $JOBID, the filelist or the input files to generate unique names
Where can you use it? • The scheduler is installed both at BNL and at PDSF • At present, the file catalog at PDSF is not ready • For any help and information you can consult the scheduler website and the scheduler mailing on hypernews
References • Scheduler hypernews • Scheduler manual • http://www.star.bnl.gov/STAR/comp/Grid/scheduler/ • File Catalog manual • http://www.star.bnl.gov/comp/sofi/FileCatalog.html