Download

1 / 24
240 likes | 514 Views
Comparing Two Groups ’ Means or Proportions:. Independent Samples t-tests. Review. Confidence Interval for a Mean Slap a sampling distribution * over a sample mean to determine a range in which the population mean has a particular probability of being—such as 95% CI.

E N D
Comparing Two Groups’ Means or Proportions: Independent Samples t-tests
Review Confidence Interval for a Mean Slap a sampling distribution* over a sample mean to determine a range in which the population mean has a particular probability of being—such as 95% CI. If our sample is one of the middle 95%, we know that the mean of the population is within the CI. Significance Test for a Mean Slap a sampling distribution* over a guess of the population mean to determine if the sample has a very low probability of having come from a population where the guess is true—such as α-level = .05. If our sample mean is in the outer 5%, we know to reject the guess, our sample has a low chance of having come from a population with the mean we guessed. Y-bar? Y-bar? µ? 2.5% 2.5% 2.5% 2.5% -1.96z +1.96z Y-bar 95% CI: Y-bar +/- 1.96 *(s.e.) -1.96z +1.96z µo=guess z or t = (Y-bar - µo)/ s.e. 20 21 22 23 24 X H 27 28 29 30 *sampling distribution: the way a statistic from samples of a certain size are distributed after all possible random samples with replacement are collected
Review Let’s collect some data on educational aspirations and produce a 95% confidence interval to tell us what the population parameter likely is, and then let’s do a significance test, guessing that average aspiration will be 16 years. We have a sample size of 625 kids who reported their educational aspirations (where 12 = high school, 16 equals 4 years of college and so forth). The sample mean is 15 years with a standard deviation of 2 years. 95% confidence interval = Sample Mean +/- z * s.e. • Calculate the standard error (s.e.) of the sampling distribution: s.e. = s / n = 2/√625 = 2/25 = 0.08 • Build the width of the Interval, using s.e. and the z that corresponds with the percent confidence. 95% corresponds with a z of +/- 1.96. Interval = +/- z * s.e. = +/- 1.96 * 0.08 = +/- 0.157 • Center the interval width on the mean (add to and subtract from the mean): 95% CI = Sample Mean +/- z * s.e. = 15 +/- 0.157 The 95% CI: 14.84 to 15.16 We are 95% confident that the population mean falls between these values. (What does this say about my guess???)
Review Let’s collect some data on educational aspirations and produce a 95% confidence interval to tell us what the population parameter likely is, and then let’s do a significance test, guessing that average aspiration will be 16 years. We have a sample size of 625 kids who reported their educational aspirations (where 12 = high school, 16 equals 4 years of college and so forth). The sample mean is 15 years with a standard deviation of 2 years. Significance Test z or t = (Y-bar - µo) / s.e. • Decide -level ( = .05) and nature of test (two-tailed) • Set critical z or t: (+/- 1.96) • Make guess or null hypothesis, Ho: = 16 Ha: 16 • Collect and analyze data • Calculate Z or t: z or t = Y-bar- o (s.e. = s/√n = 2/√625 = 2/25 = .08) s.e. z or t = (15 – 16)/.08 = -1/.08 = -12.5 • Make a decision about the null hypothesis (reject the null: -12.5 < -1.96) • Find the P-value (look up 12.5 in z or t table). P < .0001 It is extremely unlikely that our sample came from a population where the mean is 16.
Other Probability Distributions • A Note: Not all theoretical probability distributions are Normal. One example of many is the binomial distribution. • The binomial distribution gives the discrete probability distribution of obtaining exactly n successes out of N trials where the result of each trial is true with known probability of success and false with the inverse probability. • The binomial distribution has a formula and changes shape with each probability of success and number of trials. • However, in this class the normal probability distribution is the most useful! a binomial distribution, used with proportions Successes: 0 1 2 3 4 5 6 7 8 9 10 11 12
Why t instead of z? • We use t instead of z to be more accurate: • t curves are symmetric and bell-shaped like the normal distribution. However, the spread is more than that of the standard normal distribution—the tails are fatter. “t is number of standard errors on a t distribution” Tea Tests? df = 1, 2, 5, and so on, approaching normal as df exceeds 120.
t • The reason for using t is due to the fact that we use sample standard deviation (s) rather than population standard deviation (σ) to calculate standard error. Since s, standard deviations, will vary from sample to sample, the variability in the sampling distribution ought to be greater than in the normal curve. t has a larger spread, more accurately reflecting the likelihood of extreme samples, especially when sample size is small. • The larger the degrees of freedom (n – 1 when estimating the mean), the closer the t curve is to the normal curve. This reflects the fact that the standard deviation s approaches σ for large sample size n. • Even though z-scores based on the normal curve will work for larger samples (n > 120) SPSS uses t for all tests because it works for small samples and large samples alike. (df = the number of scores that are free to vary when calculating a statistic . . . n - ?) Tea Tests?
Comparing Two Groups I love sophisticated statistics! We’re going to move forward to more sophisticated statistics, building on what we have learned about confidence intervals and significance tests. Social scientists look for relationships between concepts in the social world. For example: Does one’s sex affect income? Focus on the relationship between the concepts: Sex and Income Does one’s race affect educational attainment? Focus on the relationship between the concepts: Race and Educational Attainment
Comparing Two Groups • Causality: Three necessary conditions: • Association • Time order • Nonspuriousness In this section of the course, you will learn ways to infer from a sample whether two concepts are related in a population. Independent variable (X): That which causes another variable to change when it changes. Dependent variable (Y): That which changes in response to change in another variable. X Y (X= Sex or Race) (Y= Income or Education) The statistical technique you use will depend of the level of measurement of your independent and dependent variables—the statistical test must match the variables! Levels of Measurement: Nominal, Ordinal, Interval-Ratio
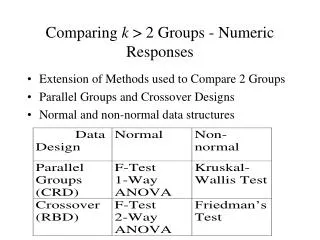
Comparing Two Groups The test you choose depends on level of measurement: Independent Dependent Statistical Test Dichotomous Interval-ratio Independent Samples t-test Dichotomous Nominal Nominal Cross Tabs Ordinal Ordinal Dichotomous Dichotomous Nominal Interval-ratio ANOVA Ordinal Dichotomous Dichotomous Interval-ratio Interval-ratio Correlation and OLS Regression Dichotomous
Comparing Two Groups Independent Dependent Statistical Test Dichotomous Interval-ratio Independent Samples t-test Dichotomous An independent samples t-test is concerned with whether a mean or proportion is equal between two groups. For example, does sex affect income? ♀ Income ♂ Income µ µ Women’s mean = Men’s Mean ???
Comparing Two Groups Independent Samples t-tests: Earlier, our focus was on the mean. We used the mean of the sample (statistic) to infer a range for what our population mean (parameter) might be (confidence interval) or whether it was like some guess or not (significance test). Now, our focus is on the difference in the mean for two groups. We will use the difference in the sample means (statistic) to infer a range for what our population difference in means (parameter) might be (confidence interval) or whether it is like some guess (significance test).
Comparing Two Groups The difference will be calculated as such: D-bar = Y-bar2 – Y-bar1 For example: Average Difference in Income by Sex = Male Average Income – Female Average Income (What would it mean if men’s income minus women’s income equaled zero?)
Comparing Two Groups Like the mean, if one were to take random sample after random sample from two groups—with normal population distributions—and calculate and record the difference between groups each time, one would see the formation of a Sampling Distribution for D-bar that was normal and centered on the two populations’ difference. average difference between two groups’ samples = Sampling Distribution of D-bar Z -3 -2 -1 0 1 2 3 95% Range
Comparing Two Groups So the rules and techniques we learned for means apply to the differences in groups’ means. One creates sampling distributions to create confidence intervals and do significance tests in the same ways. However, the standard error of D-bar has to be calculated slightly differently. For Means: (s1)2(s2)2 s.e. (s.d. of the sampling distribution) = n1 + n2 (assumes equal sample size) For Proportions: s.e. = 1 (1 - 1) 2 (1 - 2) n1 + n2 Variance Sum Law: variance of difference between two independent variables is the sum of their variances df = n1 + n2 - 2
Comparing Two Groups When variances are assumed to be equal, and sample sizes differ, we use the pooled estimate of variance for the standard error. Estimated Standard error pooled: Start with a pooled variance. Then: For Means: (sp)2(sp)2 s.e.= n1 + n2 (assumes equal variance) df = n1 + n2 - 2
Comparing Two Groups Calculating a Confidence Interval for the Difference between Two Groups’ Means By slapping the sampling distribution for the difference over our sample’s difference between groups, D-bar, we can find the values between which the population difference is likely to be. 95% C.I. = D-bar+/- 1.96 * (s.e.) Remember: When = (Y-bar2 – Y-bar1)+/- 1.96 * (s.e.) sample sizes are Or = (2 – 1)+/- 1.96 * (s.e.) small, t ≠ z, and +/- 1.96 may not be 99% C.I. = D-bar+/- 2.58 * (s.e.) appropriate. = (Y-bar2 – Y-bar1)+/- 2.58 * (s.e.) Or = (2 – 1)+/- 2.58 * (s.e.)
Comparing Two Groups Confidence Interval Example: We want to know what the likely difference is between male and female GPAs in a population of college students with 95% confidence. Sample: 50 men, average gpa = 2.9, s.d. = 0.5 (To confuse you, equal sample sizes, ergo 50 women, average gpa = 3.1, s.d. = 0.4 standard error formula not pooled) 95% C.I. = Y-bar2 – Y-bar1 +/- 1.96 * s.e. • Find the standard error of the sampling distribution: s.e. = (.5)2/ 50 + (.4)2/50 = .005 + .003 = .008 = 0.089 • Build the width of the Interval. 95% corresponds with a z or t of +/- 1.96. +/- z * s.e = +/- 1.96 * 0.089 = +/- 0.174 • Insert the mean difference to build the interval: 95% C.I. = (Y-bar2 – Y-bar1)+/- 1.96 * s.e. = 3.1 - 2.9 +/- 0.174 = 0.2 +/- 0.174 The interval: 0.026 to 0.374 We are 95% confident that the difference between men’s and women’s GPAs in the population is between .026 and 0.374. If we had guessed zero difference, would the difference be a significant difference?
Comparing Two Groups We can also use the standard error (standard deviation of the sampling distribution for differences between means) to conduct a t-test. Independent Samples t-test: Y1 - Y2 t = For Means: (sp)2(sp)2 n1 + n2 n1 + n2 - 2
Comparing Two Groups Conducting a Test of Significance for the Difference between Two Groups’ Means By slapping the sampling distribution for the difference over a guess of the difference between groups, Ho, we can find out whether our sample could have been drawn from a population where the difference is equal to our guess. • Two-tailed significance test for -level = .05 • Critical z or t = +/- 1.96 • To find if there is a difference in the population, Ho: 2 - 1 = 0 Ha: 2 - 1 0 • Collect Data • Calculate z or t: z or t = (Y-bar2 – Y-bar1)– (2 - µ1) s.e. • Make decision about the null hypothesis (reject or fail to reject) • Report P-value
Comparing Two Groups Significance Test Example: We want to know whether there is a difference in male and female GPAs in a population of college students. • Two-tailed significance test for -level = .05 • Critical z or t = +/- 1.96 • To find if there is a difference in the population, Ho: 2 - 1 = 0 Ha: 2 - 1 0 • Collect Data Sample: 50 men, average gpa = 2.9, s.d. = 0.5 (To confuse you, equal sample sizes, ergo 50 women, average gpa = 3.1, s.d. = 0.4 standard error formula not pooled) s.e. = (.5)2/ 50 + (.4)2/50 = .005 + .003 = .008 = 0.089 • Calculate z or t: z or t = 3.1 – 2.9 – 0 = 0.2 = 2.25 0.089 0.089 • Make decision about the null hypothesis: Reject the null. There is enough difference between groups in our sample to say that there is a difference in the population. 2.25 >1.96 • Find P-value: p or (sig.) = .0122 x2 (table gives one-tail only) = .0244 We have a 2.4 % chance that the difference in our sample could have come from a population where there is no difference between men and women. That chance is low enough to reject the null, for sure!
Comparing Two Groups The steps outlined above for Confidence intervals And Significance tests for differences in means are the same you would use for differences in proportions. Just note the difference in calculation of the standard error for the difference.
Comparing Two Groups The steps outlined above for Confidence intervals And Significance tests for independent groups are the same you would use for differences between dependent groups. Just note the difference in calculation of the standard error for the difference. s.e. = SD / n
Comparing Two Groups • Now let’s do an example with SPSS, using the General Social Survey.