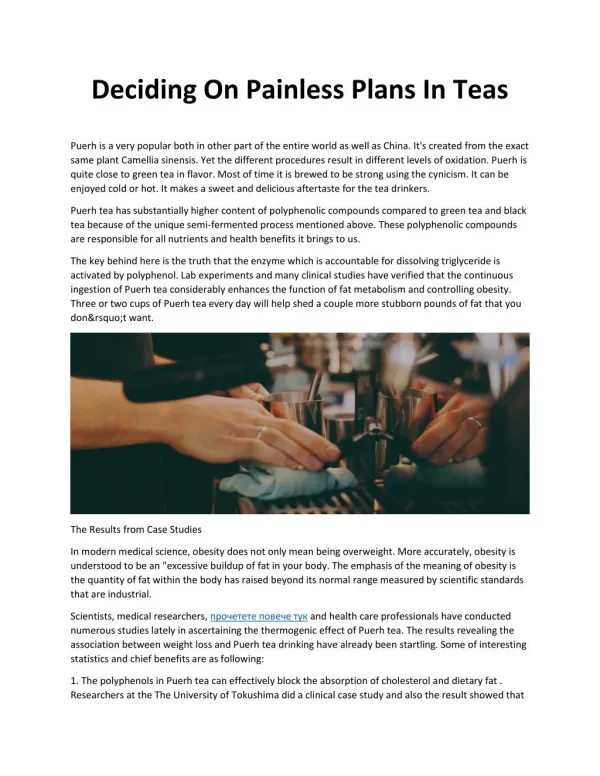
Download

1 / 15
150 likes | 249 Views
Fast Webpage classification using URL features. Authors: Min-Yen Kan Hoang and Oanh Nguyen Thi Conference: ICIKM 2005 Reporter: Yi-Ren Yeh. Outline. Introduction URL Feature Extraction Recursive segmentation Using URL feature classes Experimental results Conclusion. Introduction.

E N D
Fast Webpage classification using URL features Authors: Min-Yen Kan Hoang and Oanh Nguyen Thi Conference: ICIKM 2005 Reporter: Yi-Ren Yeh
Outline • Introduction • URL Feature Extraction • Recursive segmentation • Using URL feature classes • Experimental results • Conclusion
Introduction • A web page's uniform resource locator (URL) is the least expensive to obtain • One of the more informative sources with respect to classification • The authors approach webpage classification only by using the URLs • Feature extraction from URL • Apply machine learning algorithms
URL Baseline Segmentation • Segment URL at non-alphanumeric characters and at URI-escaped entities (e.g., '%20') to create smaller tokens • Baseline segmentation is straightforward to implement and typically results in 4-7 tokens example
Recursive Segmentation • Concatenated words (e.g., activatealert) are especially prevalent in website domain names • Segmenting these tokens into its component words is likely to increase performance • This paper performs the segmentation by information content (entropy) reduction additionally • A token T can be split into n partitions if where ti denotes the ith partition of T
Recursive Segmentation • A partitioning that has lower entropy than others would be a more probable parse of the token • Such entropies can be estimated by collecting the frequencies of tokens in a large corpus • Applying a tree partition strategy (O(n log n)) to replace all the 2^(T-1) partitions example
URI Components and Length features • First spilt the URL via URI protocol scheme :// host / path / document . extension ? query # fragment • A token that occurs in different parts of URLs may contribute differently to classification • The authors feature set by qualifying them with their components • The absence of certain components can influence classification as well • The absence of certain components also can influence classification as well example
Orthographic Features • Using the surface form of a token also presents challenges for generalization • e.g. 2002 vs. 2003 • Add features for tokens with capitalized letters and/or numbers that differentiate these tokens by their length • These features are added both in a general, URL-wide feature as well as ones that are URI component-specific
Sequential Features • N-grams token might also help in classification • The authors use 2, 3, and 4-grams • Sequential order among tokens also matters • “web spider” and “spider web” • consider model left-to-right precedence between tokens example
Evaluate on Multi-class Classification • Employ a subset of the WebKB, containing 4,167 pages • Four classes (student, faculty, course and project ) • Use SVM and Maximum entropy classification method • Marco F measure is used
Evaluate On Hierarchical Categorization • Evaluate on the Open Directory Project • The snapshot dated 3 August 2004, which encompasses over 4.4 M URLs categorized into 17 first-level and 508 second-level categories • The authors use 100,000 randomly chosen ODP URLs to assemble a testing (and training) corpus for the two-level, hierarchical experiments • Only 360second-level categories are used.
Conclusion • The authors have extended previous work and added features to model URL component length, content, orthography, token sequence and precedence • Also evaluate the use of these features over a large set of tasks including relevance, categorization and Pagerank prediction. • These features do not perform as well with typical web site entry points (i.e., just the domain name), as they attempt to leverage the internal path structure of the URL.
scheme :// host / path / document . extension ? query # fragment