Download
1 / 1
20 likes | 203 Views
Prospective Prediction of M. tuberculosis Inhibition Using Bayesian Models With Open Source Data - 3 years on Sean Ekins 1,2

E N D
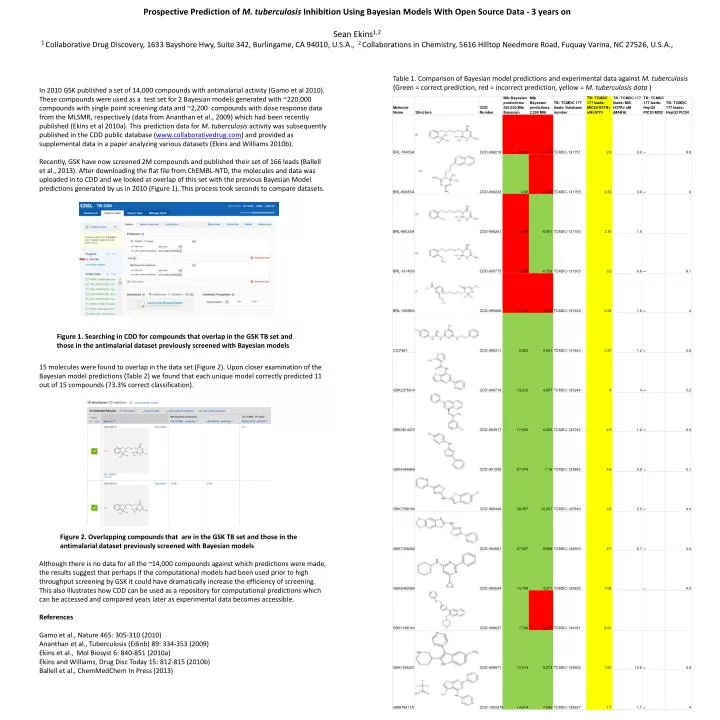
Prospective Prediction of M. tuberculosis Inhibition Using Bayesian Models With Open Source Data - 3 years on Sean Ekins1,2 1 Collaborative Drug Discovery, 1633 Bayshore Hwy, Suite 342, Burlingame, CA 94010, U.S.A., 2 Collaborations in Chemistry, 5616 Hilltop Needmore Road, Fuquay Varina, NC 27526, U.S.A., Table 1. Comparison of Bayesian model predictions and experimental data against M. tuberculosis (Green = correct prediction, red = incorrect prediction, yellow = M. tuberculosis data ) In 2010 GSK published a set of 14,000 compounds with antimalarial activity (Gamo et al 2010). These compounds were used as a test set for 2 Bayesian models generated with ~220,000 compounds with single point screening data and ~2,200 compounds with dose response data from the MLSMR, respectively (data from Ananthan et al., 2009) which had been recently published (Ekins et al 2010a). This prediction data for M. tuberculosis activity was subsequently published in the CDD public database (www.collaborativedrug.com) and provided as supplemental data in a paper analyzing various datasets (Ekins and Williams 2010b). Recently, GSK have now screened 2M compounds and published their set of 166 leads (Ballell et al., 2013). After downloading the flat file from ChEMBL-NTD, the molecules and data was uploaded in to CDD and we looked at overlap of this set with the previous Bayesian Model predictions generated by us in 2010 (Figure 1). This process took seconds to compare datasets. 15 molecules were found to overlap in the data set (Figure 2). Upon closer examination of the Bayesian model predictions (Table 2) we found that each unique model correctly predicted 11 out of 15 compounds (73.3% correct classification). Although there is no data for all the ~14,000 compounds against which predictions were made, the results suggest that perhaps if the computational models had been used prior to high throughput screening by GSK it could have dramatically increase the efficiency of screening. This also illustrates how CDD can be used as a repository for computational predictions which can be accessed and compared years later as experimental data becomes accessible. References Gamo et al., Nature 465: 305-310 (2010) Ananthan et al., Tuberculosis (Edinb) 89: 334-353 (2009) Ekins et al., MolBiosyst 6: 840-851 (2010a) Ekins and Williams, Drug Disc Today 15: 812-815 (2010b) Ballell et al., ChemMedChem In Press (2013) Figure 1. Searching in CDD for compounds that overlap in the GSK TB set and those in the antimalarial dataset previously screened with Bayesian models Figure 2. Overlapping compounds that are in the GSK TB set and those in the antimalarial dataset previously screened with Bayesian models
