Download

1 / 43
460 likes | 507 Views
Explore the history and significance of graphics hardware, from early Lisp machines to modern GPUs, focusing on the evolution, market demand, and advancements in performance and parallelism. Learn about the NVIDIA 8800 Ultra and the future of graphics hardware.

E N D
Graphics Hardware Kurt Akeley CS248 Lecture 14 8 November 2007 http://graphics.stanford.edu/courses/cs248-07/
SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP TF TF TF TF TF TF TF TF L1 L1 L1 L1 L1 L1 L1 L1 L2 L2 L2 L2 L2 L2 FB FB FB FB FB FB Implementation = abstraction (from lecture 2) Application Application Vertex assembly Data Assembler Setup / Rstr / ZCull Vtx Thread Issue Prim Thread Issue Frag Thread Issue Vertex operations Primitive assembly Thread Processor Primitive operations Rasterization Fragment operations Framebuffer NVIDIA GeForce 8800 OpenGL Pipeline Source : NVIDIA
SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP TF TF TF TF TF TF TF TF L1 L1 L1 L1 L1 L1 L1 L1 L2 L2 L2 L2 L2 L2 FB FB FB FB FB FB Correspondence (by color) Fixed-function assembly processors Application-programmable parallel processor Application Application Vertex assembly this was missing Data Assembler Setup / Rstr / ZCull Vtx Thread Issue Prim Thread Issue Frag Thread Issue Vertex operations Primitive assembly Thread Processor Primitive operations Fixed-function framebuffer operations Rasterization(fragment assembly) Fragment operations Framebuffer NVIDIA GeForce 8800 OpenGL Pipeline
Why does graphics hardware exist? Special-purpose hardware tends to disappear over time • Lisp machines and CAD workstations of the 80s • CISC CPUs iAPX432(circa 1982)www.dvorak.org/blog/ Symbolics Lisp Machines(circa 1984)www.abstractscience.freeserve.co.uk/symbolics/photos/
Why does graphics hardware exist? Graphics acceleration has been around for 40 years. Why do GPUs remain? Confluence of four things: • Performance differentiation • GPUs are much faster than CPUs at 3-D rendering tasks • Work-load sufficiency • The accelerated 3-D rendering tasks make up a significant portion of the overall processing (thus Amdahl’s law doesn’t limit the resulting performance increase). • Strong market demand • Customer demand for 3-D graphics performance is strong • Driven by the games market • Ubiquity • With the help of standardized APIs/architectures (OpenGL and Direct3D) GPUs have achieved ubiquity in the PC market • Inertia now works in favor of continued graphics hardware
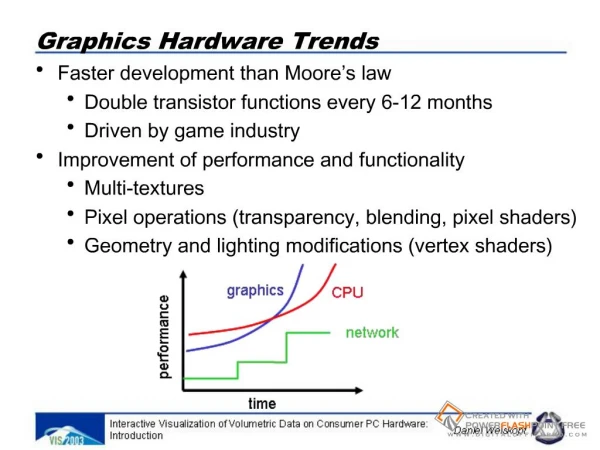
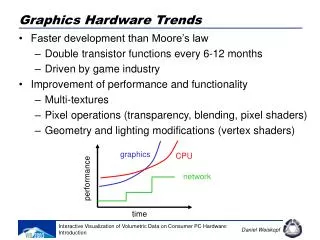
NVIDIA performance trends Yearly Growth is well above 1.5 (Moore’s Law)
SGI performance trends (depth buffered) Yearly Growth well above 1.5 (Moore’s Law)
CPU performance CAGR has been slowing Source: Hennessy and Patterson
The situation could change … CPUs are becoming much more parallel • CPU performance increase (1.2x to 1.5x per year) is low compared with the GPU increase (1.7x to 2x per year). • This could change now with CPU parallelism (many-core) The vertex pipeline architecture is getting old • Approaches such as ray tracing offer many advantages, but the vertex pipeline is poorly optimized for them • The work-load argument is somewhat circular, because the brute-force algorithms employed by GPUs inflate their own performance demands GPUs have and will continue to evolve • But a revolution is always possible
Outline The rest of this lecture is organized around the four ideas that most informed the design of modern GPUs (as enumerated by David Blythe in this lecture’s reading assignment): • Parallelism • Coherence • Latency • Programmability I’ll continue to use the NVIDIA 8800 as a specific example
Graphics is “embarrassingly parallel” Application struct { float x,y,z,w; float r,g,b,a;} vertex; Many separate tasks (the types I keep talking about) Vertex assembly Vertex operations struct { vertex v0,v1,v2 } triangle; Primitive assembly No “horizontal” dependencies, few “vertical”(in-order execution) Primitive operations struct { short int x,y; float depth; float r,g,b,a;} fragment; Rasterization Fragment operations Framebuffer struct { int depth; byte r,g,b,a;} pixel; Display
Data Parallelism Data and task parallelism Application Data parallelism • Simultaneously doing the same thing to similar data • E.g., transforming vertexes • Some variance in “same thing” is possible Task parallelism • Simultaneously doing different things • E.g., the tasks (stages) of the vertex pipeline Task Parallelism Vertex assembly Vertex operations Primitive assembly Primitive operations Rasterization Fragment operations Framebuffer Display
Command Processor Round-robin Aggregation Trend from pipeline to data parallelism Coord, normal Transform Coordinate Transform Lighting Clip testing Clipping state 6-plane Frustum Clipping Divide by w (clipping) Viewport Prim. Assy. Backface cull Divide by w Viewport SGI 4D/GTX(1988) Clark “Geometry Engine”(1983) SGI RealityEngine(1992)
Load balancing Application Easy for data parallelism Challenging for task parallelism • Static balance is difficult to achieve • But is insufficient • Mode changes affect execution time (e.g., complex lighting) • Worse, data can affect execution time (e.g., clipping) Unified architectures ease pipeline balance • Pipeline is virtual, processors assigned as required • 8800 is unified Vertex assembly Vertex operations Primitive assembly Primitive operations Rasterization Fragment operations Framebuffer Display
SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP TF TF TF TF TF TF TF TF L1 L1 L1 L1 L1 L1 L1 L1 L2 L2 L2 L2 L2 L2 FB FB FB FB FB FB Unified pipeline architecture Application-programmable parallel processor Application Application Vertex assembly this was missing Data Assembler Setup / Rstr / ZCull Vtx Thread Issue Prim Thread Issue Frag Thread Issue Vertex operations Primitive assembly Thread Processor Primitive operations Rasterization(fragment assembly) Fragment operations Framebuffer NVIDIA GeForce 8800 OpenGL Pipeline
Queueing Application FIFO buffering (first-in, first-out) is provided between task stages • Accommodates variation in execution time • Provides elasticity to allow unified load balancing to work FIFOs can also be unified • Share a single large memory with multiple head-tail pairs • Allocate as required Vertex assembly FIFO Vertex operations FIFO Primitive assembly FIFO
In-order execution Work elements must be sequence stamped Can use FIFOs as reorder buffers as well
Two aspects of coherence Data locality • The data required for computation are “near by” Computational coherence • Similar sequences of operations are being performed
Data locality Application Prior to texture mapping: • Vertex pipeline was a stream processor • Each work element (vertex, primitive, fragment) carried all the state it needed • Modal state was local to the pipeline stage • Assembly stages operated on adjacent work elements • Data locality was inherent in this model Post texture mapping: • All application-programmable stages have memory access (and use them) • So the vertex pipeline is no longer a stream processor • Data locality must be fought for … Vertex assembly Vertex operations Primitive assembly Primitive operations Rasterization Fragment operations Framebuffer Display
Post-texture mapping data locality (simplified) Modern memory (DRAM) operates in large blocks • Memory is a 2-D array • Access is to an entire row To make efficient use of memory bandwidth all the data in a block must be used Two things can be done: • Aggregate read and write requests • Memory controller and cache • Complex part of GPU design • Organize memory contents coherently (blocking)
Texture Blocking Address base s1 t1 s2 t2 s3 t3 6D Organization Cache Line Size Cache Size 4x4 blocks 4x4 texels (s1,t1) (s2,t2) (s3,t3) Source: Pat Hanrahan
struct { float x,y,z,w; float r,g,b,a;} vertex; struct { float x,y,z,w; float r,g,b,a;} vertex; Computational coherence Data parallelism is computationally coherent • Simultaneously doing the same thing to similar data • Can share a single instruction sequencer with multiple data paths: Instructionfetch andexecute SIMD – Single Instruction Multiple Data
SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP TF TF TF TF TF TF TF TF L1 L1 L1 L1 L1 L1 L1 L1 L2 L2 L2 L2 L2 L2 FB FB FB FB FB FB SIMD processing One of eight 16-wide SIMD processors Application this was missing Data Assembler Setup / Rstr / ZCull Vtx Thread Issue Prim Thread Issue Frag Thread Issue Why not use one 128-wide processor? Thread Processor NVIDIA GeForce 8800
SIMD conditional control flow The “shader” abstraction operates on each data element independently But SIMD implementation shares a single execution unit across multiple data elements If data elements in the same SIMD unit branch differently the execution unit must follow both paths (sequentially) The solution is predication: • Both paths are executed • Data paths are enabled only during their selected path • Can be nested • Performance is obviously lost! SIMD width is a compromise: • Too wide too much performance loss due to predication • Too narrow inefficient hardware implementation
Again two issues Overall rendering latency • Typically measured in frames • Of concern to application programmers • Short on modern GPUs (more from Dave Oldcorn on this) • But GPUs with longer rendering latencies have been designed • Fun to talk about in a graphics architecture course Memory access latency • Typically measured in clock cycles (and reaching thousands of those) • Of direct concern to GPU architects and implementors • But useful for application programmers to understand too!
Multi-threading Another kind of processor virtualization • Unified GPUs share a single execution engine among multiple pipeline (task) stages • Equivalent to CPU multi-tasking • Multi-threading shares a single execution engine among multiple data-parallel work elements • Similar to CPU hyper-threading The 8800 Ultra multi-threading mechanism is used to support both multi-tasking and data-parallel multi-threading A thread is a data structure: More live registers mean more memory usage struct { int pc; // program counter float reg[n]; // live register state enum ctxt; // context information …} thread;
SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP SP TF TF TF TF TF TF TF TF L1 L1 L1 L1 L1 L1 L1 L1 L2 L2 L2 L2 L2 L2 FB FB FB FB FB FB Multi-threading Application this was missing Data Assembler Setup / Rstr / ZCull Vtx Thread Issue Prim Thread Issue Frag Thread Issue Programmability Thread Processor NVIDIA GeForce 8800
BlockedThreads ReadytoRunThreads struct { float x,y,z,w; float r,g,b,a;} vertex; struct { float x,y,z,w; float r,g,b,a;} vertex; Multi-threading hides latency Memory data available (dependency resolved) Memory reference (or resulting data dependency) Processor stalls if no threads are ready to run. Possible result of large thread context (too many live registers) Instructionfetch andexecute
Cache and thread store CPU • Uses cache to hide memory latency • Caches are huge (many MBs) GPU • Uses cache to aggregate memory requests and maximize effective bandwidth • Caches are relatively small • Uses multithreading to hide memory latency • Thread store is large Total memory usage on CPU and GPU chips is becoming similar …
Programmability trade-offs Fixed-function: • Efficient in die area and power dissipation • Rigid in functionality • Simple Programmable: • Wasteful of die area and power • Flexible and adaptable • Able to manage complexity
Programmability is not new Application The Silicon Graphics VGX (1990) supported programmable vertex, primitive, and fragment operations. • These operations are complex and require flexibility and adaptability • The assembly operations are relatively simple and have few options • Texture fetch and filter are also simple and benefit from fixed-function implementation What is new is allowing application developers to write vertex, primitive, and fragment shaders Vertex assembly Vertex operations Primitive assembly Primitive operations Rasterization Fragment operations Framebuffer OpenGL Pipeline
Why insist on in-order processing? Even Direct3D 10 does Testability (repeatability) Invariance for multi-pass rendering (repeatability) Utility of painter’s algorithm State assignment!
Why can’t fragment shaders access the framebuffer? Application Equivalent to: why do other people’s block diagrams distinguish between fragment operations and framebuffer operations? Simple answer: cache consistency Vertex assembly Vertex operations Primitive assembly Primitive operations Rasterization Fragment operations Framebuffer OpenGL Pipeline
Why hasn’t tiled rendering caught on? It seems very attractive: • Small framebuffer (that can be on-die in some cases) • Deep framebuffer state (e.g., for transparency sorting) • High performance Problems: • May increase rendering latency • Has difficulty with multi-pass algorithms • Doesn’t match the OpenGL/Direct 3D abstraction
Summary Parallelism • Graphics is inherently highly data and task parallel • Challenges include in-order execution and load balancing Coherence • Streaming is inherently data and instruction coherent • But texture fetch breaks streaming model / data coherence • Reference aggregation and memory layout restore data coherence Latency • Modern GPU implementations have minimal rendering latency • Multithreading (not caching) hides (the large) memory latency Programmability • “Operation” stages are (and have long been) programmable • Assembly stages, texture filtering, and ROPs typically are not • Application programmability is new
Assignments Next lecture: Performance Tuning and Debugging (guest lecturer Dave Oldcorn, AMD) Reading assignment for Tuesday’s class: • Sections 2.8 (vertex arrays) and 2.9 (buffer objects) of the OpenGL 2.1 specification Short office hours today