Download

1 / 14
140 likes | 435 Views
Lecture 12 Storage Hierarchy. 1000. CPU. 100. 55%/year. Performance. 10. 35%/year. 7%/year. DRAM. 1. 1980. 1981. 1982. 1983. 1984. 1985. 1986. 1987. 1988. 1989. 1990. 1991. 1992. 1993. 1994. 1995. 1996. 1997. 1998. 1999. 2000. Who Cares about Memory Hierarchy?.

E N D
Lecture 12Storage Hierarchy CS510 Computer Architecture
1000 CPU 100 55%/year Performance 10 35%/year 7%/year DRAM 1 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 Who Cares about Memory Hierarchy? • Processor Only Thus Far in Course • CPU cost/performance, ISA, Pipelined Execution CPU-DRAM Gap • 1980: no cache in mproc; • 1995 2-level cache, 60% transistors on Alpha 21164 mproc CS510 Computer Architecture
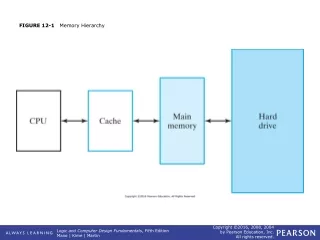
General Principles • Locality • Temporal Locality: referenced again soon • Spatial Locality: nearby items referenced soon • Locality + smaller HW is faster = memory hierarchy • Levels: smaller, faster, more expensive/byte than the level below • Inclusive: data found in top also found in the bottom • Definitions • Upperis closer to processor • Block: minimum unit that present or not in the upper level • Address = Block frame address + block offset address • Hit time: time to access the upper level, including hit determination CS510 Computer Architecture
Measures • Hit rate: fraction found in that level • So high that usually talk about Miss Rate or Fault Rate • Miss rate fallacy: as MIPS to CPU performance, miss rate to average memory access time in memory • Average memory-access time = Hit time + Miss rate x Miss penalty (ns or clocks)) • Miss penalty:: time to replace a block from the lower level, including to replace in CPU • access time: time to access the lower level =¦(lower level latency) • transfer time: time to transfer block =¦(BW upper & lower, block size) CS510 Computer Architecture
Average Memory Access Time Miss Rate Miss Penalty Transfer Time Access Time Block Size Block Size Block Size Block Size vs. Measures Increasing Block Size generally increases Miss Penalty and decreases Miss Rate = Miss Penalty x Miss Rate = Avg. Memory Access Time(AMAT) CS510 Computer Architecture
Implications for CPU • Fast hit check since every memory access needs it • Hit is the common case • Unpredictable memory access time • 10s of clock cycles: wait • 1000s of clock cycles: • Interrupt & switch & do something else • New style: multithreaded execution • How to handle miss (10s => HW, 1000s => SW)? CS510 Computer Architecture
4 Questions for Memory Hierarchy Designers • Q1: Where can a block be placed in the upper level? (Block placement) • Q2: How is a block found if it is in the upper level?(Block identification) • Q3: Which block should be replaced on a miss? (Block replacement) • Q4: What happens on a write? (Write strategy) CS510 Computer Architecture
Fully Associative: Block 12 can go anywhere Direct mapped: Block 12 can go only into Block 4 (12 Mod 8)= 4 0 1 2 3 4 5 6 7 Set Associative: Block 12 can go anywhere in Set 0 (12 Mod 4)= 0 0 1 2 3 4 5 6 7 Block Number 0 1 2 3 4 5 6 7 Set Set Set Set 0 1 2 3 Block Frame Address Block Number 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 1 1 1 1 1 1 . . . Memory Q1: Block Placement:Where can a Block be Placed in the Upper Level? Block 12 placed in 8 block cache • Fully Associative(FA), Direct Mapped, 2-way Set Associative(SA) • SA Mapping ; (Block #) Modulo(# of Sets) CS510 Computer Architecture
Block Address Block Offset Tag Index Q2: Block Identification:How to Find a Block in the Upper Level? • Tag on each block • No need to check index or block offset • Increasing associativity shrinks index, expands tag FAM: No index DM: Large index CS510 Computer Architecture
Miss Rates • Associativity: 2-way 4-way 8-way • Cache Size LRU Random LRU Random LRU Random • 16 KB 5.18% 5.69% 4.67% 5.29% 4.39% 4.96% • 64 KB 1.88% 2.01% 1.54% 1.66% 1.39% 1.53% • 256 KB 1.15% 1.17% 1.13% 1.13% 1.12% 1.12% Q3: Block Replacement:Which Block Should be Replaced on a Miss? • Easy for Direct Mapped • SAM or FAM: • Random • LRU CS510 Computer Architecture
Q4: Write Strategy:What Happens on a Write? • DLX : store 9%, load 26% in integer programs • STORE: • 9%/(100%+26%+9%) »7% of the overall memory traffic • 9%/(26%+9%) »25% of the data cache traffic • READ access is majority, thus to make the common case fast: optimizing caches for reads • High performance designs cannot neglect the speed of WRITEs CS510 Computer Architecture
Q4: What Happens on a Write? • Write Through: The information is written to both the block in the cache and to the block in the lower-level memory. • Write Back: The information is written only to the block in the cache. The modified cache block(Dirty Block) is written to main memory only when it is replaced. • is block clean or dirty? • Pros and Cons of each: • WT: read misses cannot result in writes (because of replacements) • WB: no writes of repeated writes • WT needs to be combined with write buffers so that don’t wait for lower level memory CS510 Computer Architecture
Q4: What Happens on a Write? • Write Miss • Write Allocate (fetch on write) • No-Write Allocate (write around) • WB caches generally use Write Allocate, while WT caches often use No-Write Allocate CS510 Computer Architecture
Summary • CPU-Memory gap is major performance obstacle for performance, HW and SW • Take advantage of program behavior: locality • Time of program still only reliable performance measure • 4Qs of memory hierarchy • Block Placement • Block Identification • Block Replacement • Write Strategy CS510 Computer Architecture