Download

1 / 83
840 likes | 999 Views
Microarray Data Capture Workshop. Friday 17 th June 2005. Program. Presentation Overview. Importance of meta-data capture MIAME, MGED ontology and MAGE Introduction to microarray storage using maxdLoad2 Advanced features of maxdLoad2 – including import and export of data.

E N D
Microarray Data Capture Workshop Friday 17th June 2005
Presentation Overview • Importance of meta-data capture • MIAME, MGED ontology and MAGE • Introduction to microarray storage using maxdLoad2 • Advanced features of maxdLoad2 – including import and export of data
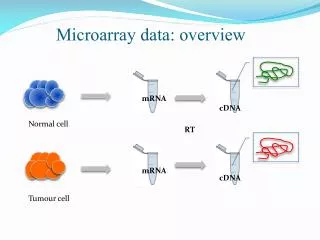
Applications of Microarrays • Has many applications: • Can target genes which react to various pharmacological agents over time. • Which genes are involved in disease and which treatments affect these genes. • Which genes are involved in the reaction of plants to environmental conditions • Determine formulas based on a genes expression for diagnosing or predicting future outcomes (e.g., cancer recurrence).
Microarrays Biological question Experiment design Microarray experiment Image analysis Pre-processing Analysis Expression quantification Normalisation ….. Prediction Testing Clustering Estimation Biological verification and interpretation
Microarrays Diagram taken from NCBI
The common scenario..... • So we’ve done our experiment • Extracted, amplified and labelled the mRNA • Hybridised our samples to the arrays • Scanned the arrays • Analysed the data • Written a paper • Submitted it to PNAS • Oh no, I’ve just re-read the information for authors and they want it “MIAME compliant” and publicly accessible for the review process
Microarray Data • Data is an asset • Very long lived • Can be used in many unforeseen ways • Data mining • Microarray Data • Costly to generate • Can be irreproducible
Why capture meta-data? • Sequence data is static. • Post-genome data is highly state-dependent. • transcriptomic meta-data = no. of cells * no. of environmental conditions. • Annotation is important! • e.g., hybridisations carried out by different experimenters can account for one of the largest sources of systematic variation in an array-based experiment. • We need to take lessons from the gene debacle. • Protein-tyrosine phosphatase, non-receptor type 6, Protein-tyrosine phosphatase 1C, PTP-1C, Hematopoietic cell protein-tyrosine phosphatase, SH-PTP1, Protein-tyrosine phosphatase SHP-1 • LARD, death receptor 3 beta, WSL-1R protein, lymphocyte associated receptor of death, death receptor 3
Meta-data quality • Accuracy • Completeness • Currency • Important to be able reference external sources rather than duplicate them • Functional annotation that is not updated • Gene names can change or obtain synonyms, without this being reflected in the data • Chip files can be out of data • Credibility
transcriptomics genomics proteomics phenomics Common meta-data interactomics mobileomics metabolomics textomics Meta-data quality cont’d… • Portability • Can the data be used outside of the context of its creation? • Incomplete meta-data limits portability
Microarray data repositories • Repository needs to keep all relevant meta-data associated with a data set • To be easily submitted, and to be searchable, data must adhere to standards, both in content and format
Microarray repositories • ArrayExpress is the repository of choice for many groups, particularly within Europe. • Its good points • High quality data to search against • Accepts MAGE-ML input from software pipelines • Some of its disadvantages • Complicated web-based data entry tool (MIAMExpress) • Convincing people to gather the extra data when other repositories may require less and are still “MIAME compliant” for publication. Activation energy. • GEO (Gene Expression Omnibus) is hosted at the NCBI.
End users/Researchers • Facilitates data sharing • Catalogued / Backed-up • Pervasive advertisement for your work Bioinformaticians/Developers • Access to data for analysis and • algorithm development • Improves search capabilities • Encourages development of more capable • software for annotation, analysis and • submission Benefits of using a data repository
The MGED Society • To facilitate microarray data storage and communication, MGED have created: • MAGE-OM • An object model linking the concepts behind a microarray experiment in “packages” • MAGE-ML • An XML based language that represents the “packages” in MAGE-OM • MGED Ontology • A controlled hierarchical vocabulary representing experimental concepts for annotation
What is MIAME? • MIAME is the internationally adopted standard for the Minimal Information About a Microarray Experiment. • The result of a MGED driven effort to codify the description of a microarray experiment. • MIAME aims to define the core that is common to most experiments. • Ultimately, it tries to specify the collection of information that would be needed to allow somebody to completely reproduce an experiment that was performed elsewhere. • Exactly what minimum means is open to interpretation and depends on operator, software and most importantly the experiment being described.
MIAME extensions • MIAME does not have all the required vocabulary to describe all types of experiments. • e.g.,environment genomics and toxicogenomics. • This resulting in the development of MIAME/Env and MIAME/Tox. • MIAME/Env is an initiative spearheaded by the EGTDC to extend MIAME standards for annotation of environmental genomic data • Includes the development of controlled vocabularies / ontologies to describe environmental genomic experiments. • MIAME/Env developed with the support of MGED society and in collaboration with MIAME/Tox and members of the EBI.
MAGE • MAGE stands for MicroArray & Gene Expression. • It is broken into two equally important parts MAGE-OM and MAGE-ML. • MAGE-OM is an object model of microarray experiment. • It represents a generalised experiment which:- • can be manipulated to represent a specific experiment by adding information to objects (attributes). • linking objects to each other by “treatments” reiteratively to model any complexity of experiment.
MGED Ontology • Provides standard terms for the annotation of microarray experiments. • An ontology is the formal representation of a domain, and allows complex paradigms to be reasoned over by automated systems. • The terms enable: • structured queries of the elements of the experiments. • Unambiguous descriptions of how the experiment was performed. • Current version 1.1.9 updated every few months • 226 classes 109 properties 644 individuals • Expands to add new terms to map to new experiment types/new uses of terms (and to correct existing errors as they’re found).
Main features • Loading, browsing, editing and searching. • Extensible: customisable attributes for each part of the schema. • MIAME data capture. • MAGE-ML data export.
maxdLoad2 : An extensible, MIAME-compliant database for microarray experiments • A database schema and a software application. • The second-generation of maxdLoad. • Integrated data loading, browsing, editing and searching. • Written in Java™, runs on most computers… • Supports any SQL92 database: Oracle, MySQL, Postgres, Sybase, Firebird
Evolution of maxdLoad2 • The ‘maxd’ software has been in development since 2000. • The analysis and visualisation suite ‘maxdView’: • Is based on a modular design - new features can be added as ‘plugins’. • Lots of normalisation, filtering and plotting features are provided. • The database component, maxdLoad was based on the EBI’s original “ArrayExpress” reference model. • In maxdLoad2, the database design has been modified to more closely correspond to MIAME and MAGE concepts. The major advance isthe customisable/extensible attribute mechanism – this feature is being used for rapid prototyping by the MIAME/Env project
maxdLoad2 Database Server(e.g. Oracle, MySQL) Data System architecture • maxdLoad2 is NOT accessed via a web-browser • It is a stand-alone application, written in Java (this makes it very portable). • maxdLoad2 and the database server can run on the same machine, no network connection or web server is needed. • However, maxdLoad2 and the database server can be on separate machines connected via a network.
Material Material Treatments Treatments Labelling Labelling Hybridisation time Scanning Data Microarray experiment workflow • A typical microarray experiment is a sequence of steps starting with one or more ‘BioMaterials’ and ending up with a big pile of numbers. • These steps can be thought of as transformations: material A + treatment = material Band combinations: image + scanning = data • Each of the steps needs to be recorded in the database. • Many of the steps will be standardised, for example, the protocol used for labelling. They will only have to be defined once.
Healthy Diseased Different protocol? Different person? Different hardware? Expression of Gene Y Expression of Gene X Why record everything? • The more meta-data that is captured, the better the chance of explaining things when it all goes wrong! • Most studies that have looked at between study variation find that the biggest component of difference is lab (person, protocol, equipment) then array then biology
Why all the structuring Free Texteasy to generate, hard to understand • What’s wrong with just describing what happened as a nice big document? • It is very hard for software to understand the process and therefore difficult for the software to behave intelligently, or to assist the user in any way • It makes reusing common bits of the description tricky – a general rule of thumb is “reuse is good, cut-and-paste is bad” Structured Objects hard to generate, easy to understand
What is in the database? • Experiment • A collection of related hybridisations and the resulting data • Experiment, Measurements, Images and Hybridisations • Array Design • The contents and the layout of a microarray • ArrayType, Features, Reporters and Genes • Bio-Materials • The actual biological entities that are used • LabelledExtract, Extract, TreatedSample, Sample, Sources • Protocols • Standardised methods of operation in the laboratory • ImageAnalysisProtocol, ScanningProtocol, etc..
Bio-Materials model the experiment • Source • original organism, tissue sample • Sample • acquisition of material from a source • Treated Sample • is a sample which has something done to it • Extract • a portion of a TreatedSample selected for analysis • LabelledExtract • a TreatedSample that has been prepared for hybridisation • These elements are generally constructed in the order shown above. The methods used in preparation and production are recorded using their associated ‘Protocol’ elements.
Modelling an experiment LabelledExtract • The various elements can be plugged together in different ways to represent the way the experiment is constructed. • Components are wired together in ‘reverse’ order; connections are based on where things came from, rather than on the sequence in which they were generated. • Pooling and splitting operations are represented by having one instance linked to more than one other instance, or vice versa. Extract TreatedSample Sample Source
A Protocols Extract “Control +20 minutes” Extract “Control +40 minutes” Extract “Shocked +20 minutes” Extract “Shocked +40 minutes” A TreatedSample TreatmentProtocol “wait 20 minutes” A TreatedSample A TreatedSample TreatmentProtocol “wait 40 minutes” A TreatedSample TreatmentProtocol “heat_shock” A TreatedSample “Shocked” TreatedSample “Control” A TreatmentProtocol “do nothing” Represents the “application of a protocol” A Sample • The Protocol links explain why the Bio-Material components have been connected in the way they are.
Arrays, Features, Reporters and Genes • ArrayType models the platform • Feature models the spaces where Reporters go (number, placing, size) • Reporter models the contents of the Features, type of content (control, experimental) nature of sequence • Gene models the relation of sequences to genetic information Array ArrayType Feature Row 34, Col 17 Feature Row 3, Col 91 Feature Row 19, Col 28 Reporter Reporter Reporter Gene
Property Property Measurement Property Property Hybridisations – Storing the data • A ‘Measurement’ represents the collection of results from analysing the scanned image of microarray after hybridisation. ‘Measurements’ can have any number of ‘Property’s can be associated with them. • Each ‘Property’ corresponds to one column in the file that came from the scanner (or to data generated by subsequent data analysis such as normalisation).
Connecting to the database • Connecting to a database requires the following information: • The ‘Database’, which identifies the machine and server that is hosting the database, and the name of the database (one server may be hosting more than database) • The ‘Driver File’ and ‘Driver Name’, which tells maxdLoad2 which database driver to use (these drivers are database specific) • The ‘User Name’ and ‘Password’ identify which account on the database server should be used. • Information about one or more connections can be saved and accessed from the list on the left-hand side. • The built in help system provides more details on how to set up a new database connection.
The User-interface continued….. • These buttons control which mode the software is in (create, browse, find, edit or load) • These buttons are used to open the form used to input or explore the data for each of the database components • The arrows show how the components are interconnected • These buttons access the other main features: import, export, options and the built-in help system.
The Navigator Tree • A representation of the schema as a hierarchy can also be displayed (in a separate window). • This view shows all of the links from one instance to all others. • Instances can be selected by clicking on their name. • When multiple links exist between instances (e.g., 1 ‘Extract’ linked to 5 ‘Sample’s), individual links are highlighted as the mouse passes over them.
An alternative representation of the schema Displayed either in a separate window or down the side of the main window Instances are selected by clicking on their name The navigator view is useful during instance creation as an aid in keeping track of which instances have been provided and which have not. The red line shows the path taken to the current form. Instances which have not yet been specified are tagged with yellow dots. As instances are selected or created, they are tagged with green dots, and their names are shown. The Navigator Tree
The User-interface continued….. Clicking on one of the buttons opens up a panel/form in which full details can be browsed or edited
The User-interface continued….. • Name(s): identify instances • Links: combine instances together and are defined by: • Selecting the item from lists. • Recursively filing in another form. • Attributes: store all other data about the instance • Entered by typing data directly into the fields. • Useful information can be found by clicking on attribute name. • ‘Quick-copy’ function in data entry modes.
Create Mode • Required fields (yellow) are coloured differently to optional fields (blue). • All required fields must be completed before a new instance can be created. • Links to other instances that have recently been visited are chosen from pulled down lists. • If a link to an instance which has not been defined is required, the ‘Create New’ button opens a new form, which is then used to define the new instance……
Allows the exploration of the database and the examination of links between instances. The ‘Find Linked’ can find the connections between the current instance and instance(s) in any other table. Instances can be viewed by selecting from list. List can be filtered for ease of searching. List can be sorted in chronological or alphabetical order. Browse mode
Find mode • Search for instance(s). • Instances can be found by specifying any combination of: • One or more linked instances • one of more attribute values • All or part of a name • This is done by filling in one or more fields in a form. • The collection of matching instances is then displayed using a ‘Browse Mode’.
Edit mode • This mode is a combination of ‘Create mode’ and ‘Browse mode’. • It is essentially the same as that of ‘Create mode’. • Names, links and attributes can all be edited. Warning!! • There is no audit trail, therefore once a value is changed, the previous value is lost forever.
Advanced features • In addition to the annotation shown there maxdLoad2 has some tricks up its sleeve to improve data loading • These are useful when numbers of arrays exceed a moderate figure • we’ve processed experiments with ~50 arrays manually • We’ve processed experiments with >350 arrays with loading scripts • They are also useful if dealing with less “computer confident” experimentalists • They are based around spreadsheets, which can be pre-filled with most relevant data, leaving gaps for day-to-day details
Loading data • In addition to entering data by hand using ‘Create Mode’, it is also possible to create instances by extracting data directly from a text file or Excel spreadsheet. • Data is extracted by tagging lines and columns of the data source that are ‘interesting’. • The ‘Load Mode’ forms are essentially the same as ‘Create Mode’ forms. However, instead of supplying final values for things, the column(s) containing the values are identified. • As this process can be automated, it is useful for integrating maxdLoad2 with other lab software, especially LIM systems.