Download

1 / 19
190 likes | 340 Views
Scheduling a 100,000 Core Supercomputer for Maximum Utilization and Capability. September 2010 Phil Andrews Patricia Kovatch Victor Hazlewood Troy Baer. Outline. Intro to NICS and Kraken Weekly utilization averages >90% for 6+ weeks How 90% utilization was accomplished on Kraken

E N D
Scheduling a 100,000 Core Supercomputer for Maximum Utilization and Capability September 2010 Phil AndrewsPatricia KovatchVictor Hazlewood Troy Baer
Outline • Intro to NICS and Kraken • Weekly utilization averages >90% for 6+ weeks • How 90% utilization was accomplished on Kraken • System scheduling goals • Policy change based on some past work • Influencing end user behavior • Scheduling and utilization details: closer look at three specific weeks • Conclusion and Future Work
JICS and NICS is a collaboration between UT and ORNL UT awarded the NSF Track 2B ($65M) Phased deployment of Cray XT systems with 1 PF in 2009 Total JICS funding ~$100M National Institute for Computational Sciences
Kraken on Oct 2009#4 Fastest machine in the world (Top500 6/10)First academic petaflopDelivers over 60% of all NSF cycles • 8,256 dual socket, 16GB memory nodes • 2.6GHz 6-core AMD Istanbul processor per socket • 1.03 Petaflops peak performance (99,072 cores) • Cray Seastar 2 Torus interconnect • 3.3 Petabytes DDN disk (raw) • 129 Terabytes memory • 88 cabinets • 2,200 sq ft
Kraken Cray XT5 Weekly Utilization October 2009 – June 2010 Percent Date
Kraken Weekly Utilization • Previous slide shows: • Weekly utilization over 90% for 7 of the last 9 weeks. Excellent! • Weekly utilization over 80% for 18 of the last 21 weeks. Very good! • Weekly utilization over 70% each week since implementing the new scheduling policy in mid January (red vertical line) • How was this accomplished?…
How was 90% utilization accomplished? • Taking a closer look at Kraken: • Scheduling goals • Policy • Influencing user behavior • Analysis of 3 specific weeks • Nov 9 - one month into production with new configuration • Jan 4 – during a typical slow month • Mar 1 – after implementation of policy change
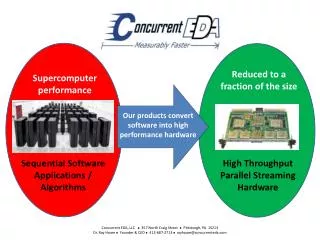
System Scheduling Goals 1. Capability computingAllow “hero” jobs that run at or near the 99,072 maximum core size in order to bring new scientific results 2. Capacity computingProvide as many delivered floating point operations as possible to Kraken users (keep utilization high) Typically these are antagonistic aspirations for a single system. Scheduling algorithms for capacity computing can lead to inefficiencies Goal: Improve utilization of a large system while allowing large capability job runs. Attempt to do both capability and capacity computing! Prior work @ SDSC led to a new approach
Policy Normal approach to capability computing is to accept large jobs, include a weighting factor that increases with queue wait time, leading to eventual draining of the system to run the large capability job. Major drawback is this can lead to reduction in the overall usage of the system Next slide illustrates this
Typical Large System Utilizationred arrows indicate system drain for capability job
Policy Change Based on past work @ SDSC, our new approach would be to drain the system on a periodic basis and run the capability jobs in succession Allow “dedicated” job runs: full machine with job owner access to Kraken only. This was needed for file system performance Allow “capacity” job runs: near full machine without dedicated system access Coincide the run of dedicated and capacity jobs during Preventative Maintenance (PM) time once a week
Policy Change Reservation would be placed to have the scheduler drain the system prior to the PM After PM dedicated jobs would be run in succession followed by capacity jobs run in succession No PM, no dedicated jobs No PM, capacity jobs limited to a specific time period This had a drastic affect on system utilization as we will show!
Influencing User Behavior To encourage capability computing jobs, NICS instituted a 50% discount for running dedicated and capacity jobs Discounts were given post job completion
Utilization Analysis The following selected weekly utilization charts show the dramatic affects of running such a large system and implementing the policy change for successive capability job runs
Utilization After Policy Change92% average, only one system drain
Conclusions Running a large computational resource and allowing capability computing can coincide with high utilization if the right balance between goals, policy and user influences are struck.
Future Work Automation of this type of scheduling policy Methods to evaluate storage requirements of capability jobs prior to execution in attempt to prevent job failures due to file system use Automation of dedicated run setup