Download
1 / 27
270 likes | 310 Views
Learn about information recognition in stimulus-response scenarios and the importance of information transmission channels. Explore concepts like entropy, probability, and measuring information in events. Gain insights into communication channels and confusion matrices.

E N D
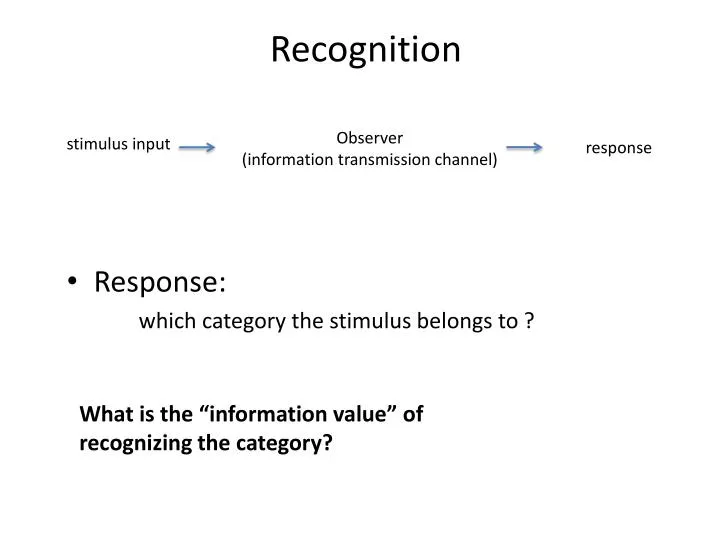
Recognition Observer (information transmission channel) stimulus input response • Response: which category the stimulus belongs to ? What is the “information value” of recognizing the category?
area reduced to 63/64 area reduced to 1/64 Information area reduced to 1/2 NOT HERE
Prior information (possible space of signals) Posterior (possible space after the signal is received) • The amount of information gained by receiving the signal is proportional to ratio of these two areas • The less likely the outcome, the more information is gained! The information in a symbol should be inversely proportional to the probability of the symbol p.
Basics of Information Theory Claude Elwood Shannon (1916-2001) • Observe output message • Try to make up the input message (gain new information) Also a juggling machine, rocket-powered Frisbees, motorized Pogo sticks, a device that could solve the Rubik's Cube puzzle,…..
Measuring the information information in an event Is always positive (since p<1) Multiplication turns to addition
When log2 , then entropy is in bits 1 bit of information reduces the area of possible messages to half
experiments with two possible outcomes with probabilities p1 and p2 total probability must be 1, so p2=1- p1 H=-p1 log2 p1 – (1– p1) log2 (1-p1) i.e. H=0 for p1=0 (the second outcome certain) or p1=1 (the first outcome certain) for p1 = 0.5, p2=0.5 H=-0.5 log2 0.5 - 0.5 log2 0.5 = log2 0.5 = 1 Entropy H (information) is maximum when the outcome is the least predictable !
Equal prior probability of each category. need 3 binary numbers (3 bits) to describe 23 = 8 categories 1st or 2nd half ? need more bits when dealing with symbols that are not all equally likely 5 bits
Information transfer through a communication channel p(X) p(Y|X) p(Y) transmitter (source) channel receiver With no noise in the channel, p(xi|yi)=1 and p(xi,yj) = 0 noise p(x) p(y|x) p(y) p(y1|x1) 1 p(x1) p(y1) p(x1) p(y1)=p(x1) 5/8 0 0.8 0.55 p(y2|x1) 1/4 p(y1|x2) 0 Two element (binary) channel p(x2) p(y2) p(x2) p(y2)=p(x2) 3/8 0.2 0.45 p(y1|x1) 1 With noise, p(xi|yi)<1 and p(xi,yj) > 0 3/4 p(y1)=(5/8x0.8)+(1/4x0.2)=0.55 p(y2)=(3/8x0.8)+(3/4x0.2)=0.45
response2 response 1 number of stimuli stimulus 1 stimulus 2 total number of stimuli (or responses) number of responses p(y1|x1) p(x1) p(y1) p(y||x1) p(y1|x2) Binary Channel p(y2) p(x2) p(y1|x1) p( xj ) = Nstim j / N p( yk ) = Nresk / N p( xj|yk) = Njk / Nres k joint probability that both xj and ykhappen is p( xj,y k) = Njk / N
Stimulus-Response Confusion Matrix received response probability of xjth symbol p( xj ) = Nstim j / N probability of ykth symbol p( yk ) = Nresk / N called stimulus conditional probability that xj was sent when yk was received p( xj|yk ) = Njk / Nres k joint probability that both xj and yk happen p( xj,y k) = Njk / N number of j-th stimuli Σk Njk=N stim j number of k-th responses Σj Njk=N resk number of called stimuli = number of responses = ΣkN resk = ΣjNstimj = N
This happens when the input and the output are independent (joint probabilities are given by products of the individual probabilities). There is no relation of the output to the input, i.e. no information transfer) information transferred by a system I (X|Y)= H(X)-H(X|Y) = Hmax(X,Y)-H(X,Y)
run experiment 20 times get it always RIGHT input probabilities p(x1)=0.5 p(x2)=0.5 output probabilities p(y1)=0.5 p(x2)=0.5 conditional probabilities p(yk|xj) transferred information I(X|Y)=H(X)-H(X|Y) = H(X) = 1
run experiment 20 times get it always RIGHT joint probabilities p(xj,yk) input probabilities p(x1)=0.5 p(x2)=0.5 output probabilities p(y1)=0.5 p(x2)=0.5 probabilities of independent events transferred information I(X|Y)=Hmax(X,Y)-H(X,Y) =2-1=1 bit
run experiment 20 times get it always WRONG input probabilities p(x1)=0.5 p(x2)=0.5 output probabilities p(y1)=0.5 p(x2)=0.5 joint probabilities p(xj,yk) probabilities of independent events transferred information I(X|Y)=Hmax(X,Y)-H(X,Y) =2-1=1 bit
run experiment 20 times get it 10 times right and 10 times wrong joint probabilities p(xj,yk) input probabilities p(x1)=0.5 p(x2)=0.5 output probabilities p(y1)=0.5 p(x2)=0.5 probabilities of independent events transferred information I(X|Y)=Hmax(X,Y)-H(X,Y) =2-2=0 bit
Matrix of Joint Probabilities (stimulus-response matrix divided by total number of stimuli) number of called stimuli=number of responses=N p(xi,yj) = Nij/N stimuli-responses joint probabilities
total number of stimuli (responses) N = 125 joint probability p(x\xj,yk) = xiyj/N matrix of joint probabilities p(xj,yk)
when xiand yj are independent events (i.e. output does not depend on input), thejoint probability would be given by a product of probabilities of these independent events P(xi,yj) = p(xi) p(yj), and the entropy of the system would be maximum Hmax (the system would be entirely useless for transmission of the information, since its output would not depend on its input)
The information that is transmitted by the system is given by a difference between the maximum joint entropy of the matrix of independent events Hmax (X,Y)and the joint entropy of the real system (derived from the confusion matrix H(X,Y). I(X|Y) =Hmax (X,Y) – X(X,Y) = 4.63 – 3.41 = 1.2 bits
Magic number 7±2 (George Miller 1956) • Human perception seems to distinguish only among 7 (plus or minus 2) different entities along one perceptual dimension • To recognize more items • long training (musicians) • use more than one perceptual dimension (e.g. pitch and loudness) • chunk the items into larger chunks (phonemes to words, words to phrases,..)