Download

1 / 49
500 likes | 622 Views
Cluster Ranking with an Application to Mining Mailbox Networks. Ziv Bar-Yossef Technion, Google Ido Guy Technion, IBM Ronny Lempel IBM Yoelle Maarek Google Vova Soroka IBM. Clustering. A network : undirected graph with non-negative edge weights w(u,v): “Similarity” between u and v.

E N D
Cluster Ranking with an Application to Mining Mailbox Networks Ziv Bar-Yossef Technion, Google Ido Guy Technion, IBM Ronny Lempel IBM Yoelle Maarek Google Vova Soroka IBM
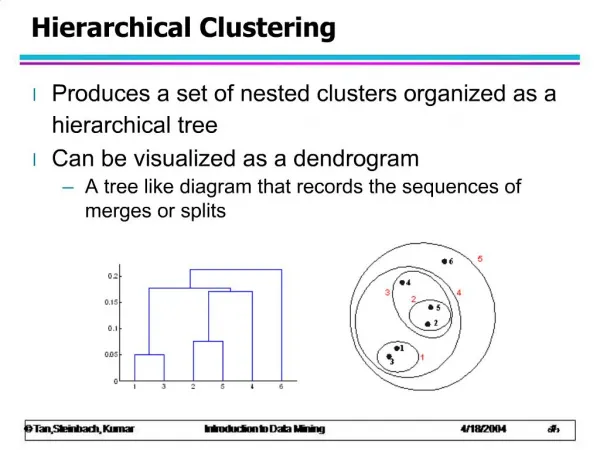
Clustering • A network: undirected graph with non-negative edge weights • w(u,v): “Similarity” between u and v. • Do not necessarily correspond to a proper metric • Induced distance may not respect the triangle’s inequality • Examples: • Social networks. w(u,v) = strength of relationship between u and v. • Biological networks. w(u,v) = genetic similarity between species u and v. • Document networks. w(u,v) = topical similarity between u and v. • Image networks. w(u,v) = color similarity/proximity between u and v. • Clustering: partitioning of the network into regions of similarity • Communities in social networks • Species families in biological networks • Groups of documents on the same topic. • Segments of an image.
The cluster abundance problem • Problem: Sometimes clustering algorithm produces masses of clusters. • Large networks • Fuzzy/soft clustering • Needle in a haystack problem – which are the important clusters?
Cluster ranking • Goals: • Define a cluster strength measure • Assigns a strength score to each subset of nodes • Design cluster ranking algorithm • Outputs the clusters in the network, ordered by their strength
A simple example • strength(C) = |C|, if C is a clique. • strength(C) = 0, if C is not a clique. • Cluster ranking: • {a,b,c}, {d,e,f} • {c,g}, {g,f} e b d c f a g
Our contributions • Cluster ranking framework • New cluster strength measure • Properly captures similarity among cluster members • Applicable to both weighted and unweighted networks • Arbitrary similarity weights • Efficiently computable • Cluster ranking algorithm • Application to mining communities in “personal mailbox networks”
Cluster strength measure:Unweighted networks G1 G2 • Which is a stronger cluster? • Cohesion = measure of strength for unweighted clusters • Cohesive cluster = does not “easily” break into pieces
Edge separators • Edge separator: A subset of the network’s edges whose removal breaks the network into two or more connected components. • All previous work: cohesion(C) = “density” of “sparsest” edge separator • Different notions of density for edge separators: • Conductance [KannanVempalaVetta00] • Normalized cut [ShiMalik00] • Relative neighborhoods [FlakeLawrenceGiles00] • Edge betweenness [GirvanNewman02] • Modularity [GirvanNewman04]
v u Clique of size m Clique of size m Clique of size m Clique of size m v Edge separators are not good enough • True: sparse edge separator noncohesive cluster • False: no sparse edge separator cohesive cluster
Vertex separators S • Vertex separator: A subset of the network’s vertices whose removal breaks the network into two or more connected components. A B • Our strength measure: cohesion(C) = “density” of “sparsest” vertex separator • Separator is “sparse”, if • S is small • A,B are “balanced”
v u Clique of size m Clique of size m Clique of size m Clique of size m v Vertex separators are better • Sparse edge separator sparse vertex separator noncohesive cluster • Sparse vertex separator noncohesive cluster
1 1 10 10 1 10 Cluster strength measure:Weighted networks • Which is a stronger cluster? • Cohesion is no longer the sole factor determining cluster strength G1 G2
Thresholding • Traditional approach for dealing with weighted networks • Transforms the weighted network into an unweighted network by a threshold • Threshold T<1 • Threshold 1 ≤ T < 5 • No threshold is suitable GT G 1 G1 GT G2 5
Cohesion(GT) Cohesion(GT) G1 G2 1 0.7 T T Integrated cohesion • Which is a stronger cluster? • Small T G1 is stronger • Large T G2is stronger • Integrated cohesion: area under the curve • Strong cluster: sustains high cohesion while increasing threshold
C-Rank - Cluster Ranking Algorithm Candidate identification Ranking by strength score Elimination of non-maximal clusters
Candidate identification: Unweighted networks • Given an unweighted network G • Find a sparse vertex separator S of G • Network splits into disconnected components A1,…,Ak • Clusters = SUA1,…,SUAk • Recurse on SUA1,…,SUAk A2 A1 A3 S A5 A4
e Candidate identification - Example A1 • Sparse separator: S = {c,d} • Connected components: A1 = {a,b}, A2 = {e} • Add back {c,d} to A1and A2 A2 a c b d
e Candidate identification - Example S U A1 • Sparse separator: S = {c,d} • Connected components: A1 = {a,b}, A2 = {e} • Add back {c,d} to A1and A2 • Since both components are cliques, no recursive calls are made a c b d S U A2 c d
Mailbox networks • Nodes: contacts appearing in headers of messages in a person’s mailbox • Excluding mailbox owner • Edges: connect contacts who co-occur at the samemassage header • Edge weights: frequency of co-occurrence • This is an egocentric social network • Reflects the subjective perspective of the mailbox owner
Mining mailbox networks Our Goal Given: A mailbox network G Output: A ranking of communities in G • Motivation • Advanced email client features • Automatic group completion and correction • Automatic group classification (colleagues, friends, spouse, etc.) • Identification of “spam groups” and management of blocked lists • Intelligence & law enforcement • Mine mailboxes of suspected terrorists and criminals
Experiments • Enron Email Dataset (http://www.cs.cmu.edu/~enron/) • Made publicly available during the investigation of Enron fraud • ~150 mailboxes of Enron employees • More than 500,000 messages • Compared with another clustering algorithm • EB-Rank - Adaptation the popular edge betweenness algorithm [GirvanNewman02] to our framework
Conclusions • The cluster ranking problem as a novel framework for clustering • Integrated cohesion as a strengthmeasure for overlapping clusters in weighted networks • C-Rank: A new cluster ranking algorithm • Application: mining mailbox networks
Cohesion(GT) Cohesion(GT) G1 G2 1 0.7 T T Integrated cohesion • Which is a stronger cluster? • Note: to compute integral, need only GT for T’s that equal the distinct edge weights
Integrated cohesion - Example G Cohesion(GT) 1 7 10 7 3 15 15 3 3 T 3 5 5 15 Cohesion = 1
Integrated cohesion - Example Cohesion(GT) 1 7 10 0.667 7 3 2.333 15 15 T 3 7 5 5 15 Cohesion = 0.667
Integrated cohesion - Example Cohesion(GT) 1 10 0.667 3 2.333 0.333 1 15 15 T 3 7 10 15 int_cohesion(G) = 3 + 2.333 + 1 = 6.333 Cohesion = 0.333
Cluster subsumption and maximality • C is maximal iff partitioning any super-set of C into clusters leaves C in tact. • S = sparsest separator of C • (C1, C2) : induced cover of C • S = sparsest separator of D • (D1,D2) : Induced cover of D • C1 D1, C2 D2 • D subsumes C C is not maximal D D2 D1 C1 S C2 C
e Candidate identification: Weighted networks G • Apply a threshold T=0 on G 5 a c 2 2 2 5 5 2 b d 2
e Candidate identification: Weighted networks G0 • Unweighted candidate identification a c b d
e Candidate identification: Weighted networks • Recurse on ‘abcd’ and ‘cde’ separately a c b d c d
Candidate identification: Weighted networks • Apply threshold T=2 on ‘abcd’ 5 a c 2 2 5 5 b d 2
Candidate identification: Weighted networks • Apply threshold T=2 on ‘abcd’ • Recurse on ‘abc’ • No recursive call on singleton ‘d’ a c b d
Candidate identification: Weighted networks • Apply threshold T=5on ‘abc’ 5 a c 5 5 b
Candidate identification: Weighted networks • Apply threshold T=5on ‘abc’ • No recursive call on singletons ‘a’ ,‘b’ ,‘c’ a c b
e Candidate identification: Weighted networks • Final candidate list: • ‘abcde’ • ‘abcd’ • ‘abc’ • ‘cde’ 5 a c 2 3 2 5 5 2 b d 2
Computing sparse vertex separators • Complexity of Sparsest Vertex Separator • NP-hard • Can be approximated in polynomial time via Semi-Definite Programming [FeigeHajiaghayiLee05] • SDP might be inefficient in practice • We find sparse vertex separators via Vertex Betweenness [Freeman77] • Efficiently computable via dynamic programming • Works well empirically • In worst-case, approximation can be weak
Computing sparse vertex separators • Complexity of Sparsest Vertex Separator • NP-hard • Can be approximated in polynomial time via Semi-Definite Programming [FeigeHajiaghayiLee05] • SDP might be inefficient in practice • We find sparse vertex separators via Vertex Betweenness [Freeman77] • Efficiently computable via dynamic programming • Works well empirically • In worst-case, approximation can be weak
Clique of size m Clique of size m v Normalized Vertex Betweenness (NVB) [Freeman77] • Vertex Betweenness (VB) of a node v: Number of shortest paths passing through v • Ex: ~m2for v, 0 for the other vertices • NormalizedVertex Betweenness (NVB): divide by to get values in [0,1] • NVB(G): Maximum NVB value over all nodes • Theorem: cohesion(G) ≥ 1/(1 + |G| · NVB(G)) • In practice: cohesion(G) ≈ 1/(1 + |G| · NVB(G))
Candidate identification: Weighted networks • Ideal algorithm: • Iterate over all possible thresholds T • Output all clusters in GT • Somewhat inefficient • Actual algorithm: • Apply threshold T = min weight in G • Output clusters of GT • For each clique C in GT Recurse on C
C-Rank: Analysis • Theorem: C-Rank is guaranteed to output all the maximal clusters. • Lemma: C-Rank runs in time polynomial in its output length.
1 1 1 a c 1 1 1 1 b d 1 1 1 Mailbox networks • An egocentric social network • Reflects the subjective perspective of the mailbox owner • Nodes: contacts appearing in message headers • Excluding mailbox owner • Edges: connect contacts who co-occur at the samemessage header • Edge weights: frequency of co-occurrence • a b, c, d, and owner • c d, e, and owner
Mailbox networks • An egocentric social network • Reflects the subjective perspective of the mailbox owner • Nodes: contacts appearing in message headers • Excluding mailbox owner • Edges: connect contacts who co-occur at the samemassage header • Edge weights: frequency of co-occurrence • a b, c, d, and owner • c d, e, and owner • b owner 1 2 1 a c 1 1 1 2 1 e 1 1 b d 1 1 2
Mailbox networks • An egocentric social network • Reflects the subjective perspective of the mailbox owner • Nodes: contacts appearing in message headers • Excluding mailbox owner • Edges: connect contacts who co-occur at the samemassage header • Edge weights: frequency of co-occurrence • a b, c, d, and owner • c d, e, and owner • b owner 1 2 1 a c 1 1 1 2 1 e 1 1 b d 1 2 2