Download
1 / 18
180 likes | 305 Views
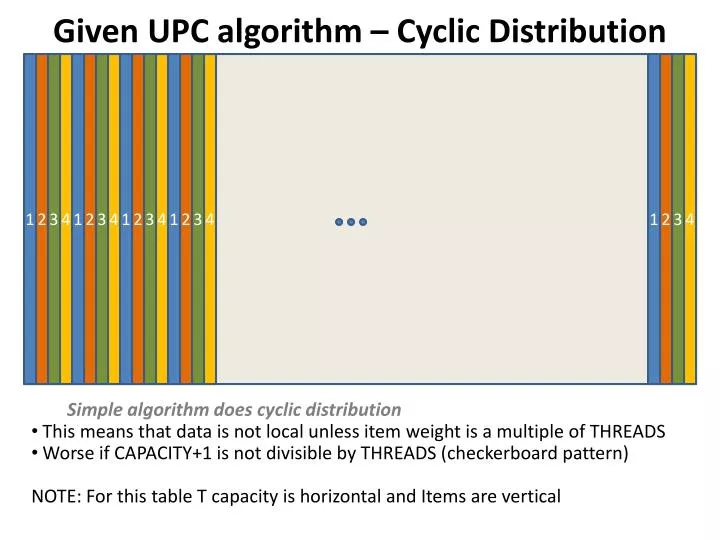
1. 1. 1. 1. 1. 2. 2. 2. 2. 2. 3. 3. 3. 3. 3. 4. 4. 4. 4. 4. Given UPC algorithm – Cyclic Distribution. Simple algorithm does cyclic distribution This means that data is not local unless item weight is a multiple of THREADS

E N D
1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 Given UPC algorithm – Cyclic Distribution Simple algorithm does cyclic distribution This means that data is not local unless item weight is a multiple of THREADS Worse if CAPACITY+1 is not divisible by THREADS (checkerboard pattern) NOTE: For this table T capacity is horizontal and Items are vertical
1 2 3 4 Possible algorithm – BlockCyclic Distribution A simple fix: block-cyclic this algorithm gives the benefit that each previous item of same capacity has same affinity more local only computations can be performed if the items are sorted by weight beforehand so that processors generally only go locally initially for data
1 2 3 4 Possible algorithm – BlockCyclic Distribution Looking at communication for a processor Algorithm communicates a lot of data with every item depending on the weight of the item Data is communicated with two processors in an unknown communication pattern
1 2 3 4 Possible algorithm – BlockCyclic Distribution More detailed look at communication Since communication is going to be the most important part lets focus our attention at a subset of processor’s 3 data and look at what it needs It can be seen that almost all the data required is horizontal for the processor with very little required vertically
1 2 New algorithm – Blocked Distribution 3 More detailed look at communication Change layout to fully blocked which makes most data needed local Only communication required now for the subset is the parts coming from processor 2 4
1 2 New algorithm – Blocked Distribution 3 BIG PROBLEM: Algorithm Serial Processor 3 requires data from processor 2 before continuing computation if it were to do entire data IDEA: run subsets of data while sticking with the blocked distribution 4
1 2 New algorithm – Blocked Distribution 3 BIG PROBLEM: Algorithm Serial Processor 3 requires data from processor 2 before continuing computation if it were to do entire data IDEA: run subsets of data while sticking with the blocked distribution 4
1 2 New algorithm – Blocked Distribution 3 BIG PROBLEM: Algorithm Serial Processor 3 requires data from processor 2 before continuing computation if it were to do entire data IDEA: run subsets of data while sticking with the blocked distribution 4
1 2 New algorithm – Blocked Distribution 3 BIG PROBLEM: Algorithm Serial Processor 3 requires data from processor 2 before continuing computation if it were to do entire data IDEA: run subsets of data while sticking with the blocked distribution 4
1 2 New algorithm – Blocked Distribution 3 BIG PROBLEM: Algorithm Serial Processor 3 requires data from processor 2 before continuing computation if it were to do entire data IDEA: run subsets of data while sticking with the blocked distribution 4
1 1 2 Pipeline algorithm – Blocked Distribution 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4
1 1 2 2 Pipeline algorithm – Blocked Distribution 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4
1 1 2 2 Pipeline algorithm – Blocked Distribution 3 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4
1 1 2 2 Pipeline algorithm – Blocked Distribution 3 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4 4
1 2 2 Pipeline algorithm – Blocked Distribution 3 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4 4
1 2 Pipeline algorithm – Blocked Distribution 3 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4 4
1 2 Pipeline algorithm – Blocked Distribution 3 New pipelined algorithm Processors run in parallel diagonally with processor 1 starting the work and processor 4 finishing Full Parallelism achieved only when pipeline full 4 4
0’s 1 1 1 2 2 2 2 3 3 3 3 Pipeline algorithm – Other considerations 0’s 4 4 4 4 1 1 Different layouts for different problem sizes If the problem isn’t very square could consider changing the layout so that pipeline gets filled earlier The optimal choices are a case of tuning Other optimizations If items are sorted in decreasing order this will help fill in the pipeline earlier (top left corner filled with zero's) Sorting is O(n log n) Most of the table is really local so can avoid keeping entire T table shared (just keep last row between processors shared and use upc_get/upc_put) 2 3 1 4 2 3 4