Download
1 / 1
10 likes | 132 Views
Parallelizing Code to Investigate the Geometric Properties of Fullerenes. Jeffery L Thomas Prof. Daniel Bennett, faculty advisor. Why study fullerenes?. STRUCTURE CHART. Our Strategy.

E N D
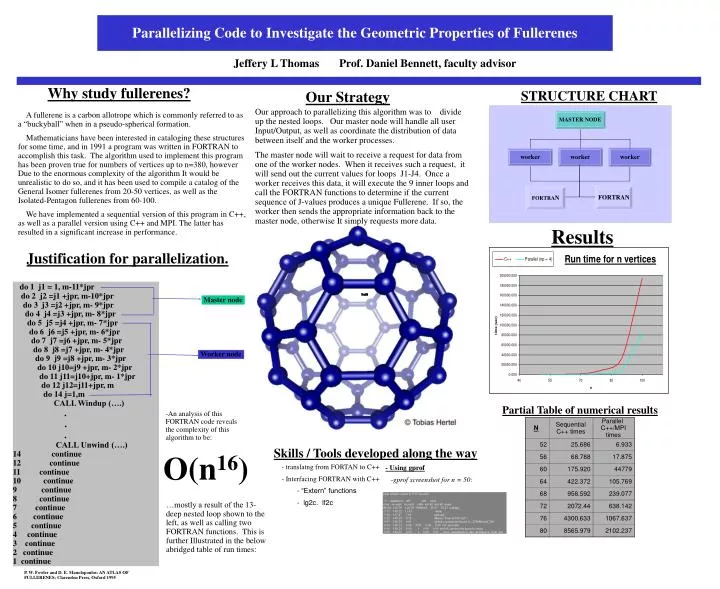
Parallelizing Code to Investigate the Geometric Properties of Fullerenes Jeffery L Thomas Prof. Daniel Bennett, faculty advisor Why study fullerenes? STRUCTURE CHART Our Strategy Our approach to parallelizing this algorithm was to divide up the nested loops. Our master node will handle all user Input/Output, as well as coordinate the distribution of data between itself and the worker processes. The master node will wait to receive a request for data from one of the worker nodes. When it receives such a request, it will send out the current values for loops J1-J4. Once a worker receives this data, it will execute the 9 inner loops and call the FORTRAN functions to determine if the current sequence of J-values produces a unique Fullerene. If so, the worker then sends the appropriate information back to the master node, otherwise It simply requests more data. A fullerene is a carbon allotrope which is commonly referred to as a “buckyball” when in a pseudo-spherical formation. Mathematicians have been interested in cataloging these structures for some time, and in 1991 a program was written in FORTRAN to accomplish this task. The algorithm used to implement this program has been proven true for numbers of vertices up to n=380, however Due to the enormous complexity of the algorithm It would be unrealistic to do so, and it has been used to compile a catalog of the General Isomer fullerenes from 20-50 vertices, as well as the Isolated-Pentagon fullerenes from 60-100. We have implemented a sequential version of this program in C++, as well as a parallel version using C++ and MPI. The latter has resulted in a significant increase in performance. Results Justification for parallelization. do 1 j1 = 1, m-11*jpr do 2 j2 =j1 +jpr, m-10*jpr do 3 j3 =j2 +jpr, m- 9*jpr do 4 j4 =j3 +jpr, m- 8*jpr do 5 j5 =j4 +jpr, m- 7*jpr do 6 j6 =j5 +jpr, m- 6*jpr do 7 j7 =j6 +jpr, m- 5*jpr do 8 j8 =j7 +jpr, m- 4*jpr do 9 j9 =j8 +jpr, m- 3*jpr do 10 j10=j9 +jpr, m- 2*jpr do 11 j11=j10+jpr, m- 1*jpr do 12 j12=j11+jpr, m do 14 j=1,m CALL Windup (….) . . . CALL Unwind (….) 14 continue 12 continue 11 continue 10 continue 9 continue 8 continue 7 continue 6 continue 5 continue 4 continue 3 continue 2 continue 1 continue Master node Worker node Partial Table of numerical results -An analysis of this FORTRAN code reveals the complexity of this algorithm to be: Skills / Tools developed along the way O(n16) • - translatng from FORTAN to C++ - Interfacing FORTRAN with C++ - “Extern” functions - lg2c. lf2c - Using gprof -gprof screenshot for n = 50: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls us/call us/call name 86.90 128.79 128.79 5096665 25.27 25.27 windup_ 7.71 140.22 11.43 main 5.16 147.87 7.65 unwind_ 0.22 148.19 0.32 Matrix::ConvertToC(int*) 0.03 148.24 0.05 global constructors keyed to _ZN6MatrixC2Ev 0.00 148.24 0.00 4071 0.00 0.00 std::setw(int) 0.00 148.24 0.00 1 0.00 0.00 global constructors keyed to main 0.00 148.24 0.00 1 0.00 0.00 __static_initialization_and_destruction_0(int, int) …mostly a result of the 13-deep nested loop shown to the left, as well as calling two FORTRAN functions. This is further Illustrated in the below abridged table of run times: P. W. Fowler and D. E. Manolopoulos: AN ATLAS OF FULLERENES; Clarendon Press, Oxford 1995





















