Download

1 / 16
160 likes | 275 Views
from quattor to puppet. A T2 point of view. Background. GRIF distributed T2 site 6 sub-sites Used quattor for GRIF-LAL is the home of 2 well known quattor gurus GRIF-IRFU (CEA) subsite Runs a 4200 cores cluster with a 2,3PiB DPM storage About 50% GRIF cpu resources.

E N D
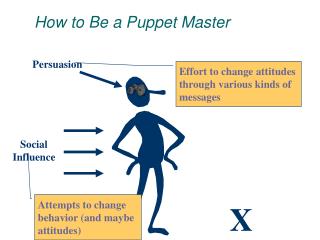
from quattor to puppet AT2 point of view
Background • GRIF distributed T2 site • 6 sub-sites • Used quattor for • GRIF-LAL is the home of 2 well known quattor gurus • GRIF-IRFU (CEA) subsite • Runs a 4200 cores cluster with a 2,3PiB DPM storage • About 50% GRIF cpu resources. • Is the only non-IN2P3 subsite • Had in the past 3 sysadmins. • Has local policies and requirements others don’t (seem to) have • Started looking and migrating to puppet after HEPIX 2012 (05/2012)
Some reasons to change • IRFU was the quattorblack sheep in GRIF • Always had to hack and maintain those hacks to abide by local policies and requirements • We were uncomfortable • with compile times • under windows/eclipse : 1-10+minutes on a laptop i7 • Under linux (for deploying), on a 4-cores Xeon : 1-10+ additional minutes ! • Debugging and understandingwas SO time consuming • Wedid not have control on security updates
Some reasons to change (2) • Quattor at GRIF suffers from several SPOFs • Power cut at LAL : no management tool. • Network failure at LAL : no management • SVN failure : nothing • Power/network maintenance : no work…. • Want to add some package ? Connect as root on quattorsrv@LAL. • Quattoris time consuming • poorquattor/QWG documentation • grep –er with 23000 files ? Slow as hell, even on SSD. Even in memory. • SPMA (no yum) wasreallygetting on our nerves • Checkdeps ? Not working. • cluster widefailureswerecommon • Specialaward for the cluster-breakingncm-accounts NCM ACCOUNTS
2012 : The decisiveyear • May 2012 : I tried to setup an EMI1 WMS+LB on a single host • starting to get pressure to migrategLite 3.2 services • wanted to avoïd the SPOF LB@LAL, hence chose a « WMS+LB » • Spent about one month (or two ?) on this • There were issues everywhere. First one was the design. • And diving (drowning) into perl objectwas a nightmare • September 2012 : end of gLite • Sites required to migrate to EMI • GRIF, IRFU failed to meet the deadline • Most, FR T2 alsofailed • Mainlybecausequattortemplateswere not ready
2012 : The decisiveyear (2) • Manpower • IRFU grid team lost one main sysadmin in 2011 • Wefought hard to keep the position and a new sysadminwetrained • IRFU lost 3 computing people recently • 2 more people to retire in 2014 • No replacement • Conclusion • Loosing time wasnot possible anymore • Quattorwas not meeting our expectations • Wehad to trysomethingelse
Whatdidwewant, as a T2 ? • Somethingwithpotential to increase (a lot) ourefficiency. • That wouldallow a « test before break » approach. • wecould control, reproduce, manage, update. Ourselves. • thatwouldallowupgrades whenthey are out, not 1 yearlater. • Wewanted to spendour time on working, not on waiting/fixing/hacking/maintaining management software
So we chose to trypuppet • BecauseCern chose it. • Becausewewantedourtemporarysysadmin to master somethingaward-winning • shouldwefail to hireherpermanently • Because the communityishuge. • Becausedocumentionis good. • Becausedeveloppers are reactive. • Becauseit’seasy to understand • (most of the time) • Becausewe know how to fix a module. • But not yetrubyones ;) https://www.flickr.com/photos/19779889@N00/7369247848
The road to puppet • Was NOT easy • It took us 2 years to migrateeverything. • Wespentmanyhourslate at night on this • Puppet and foreman are not perfect. • Wewere in a hurry • Alwayshad to upgrade somethingwithquattor • wanted to meet deadlines • wanted to avoïdquattor upgrades (spmayum, json…) • Westartedwitheasythings : virtual machines. • wespentmonthwriting « base modules » that configure the base machines as wewant : OS packets, fixed IPv4, repositories, NTP, firewalls, DNS, network… • Then came the foreman/puppetmaster • Managed by puppetitself • Complex, evenwithpuppet modules • Thenwestartedimplementingeasythings : • perfsonar (PS, MDM) • National accounting machine (MySQL server) • NFS servers…
The road to puppet (2) • Nextstepwasgrid machines • Wewrotegrid and yaimmodules • First one calling the second one… • And hardcoded a few staticthings • VO details, accountUIDs… • Weimplementedfromlowest to highestdifficulty/risks • Wms • Computing (CREAM CE + torque + maui) • Storage (DPM) • Wefacedrequirements and issues along the way • Even CERN modules sometimes are not so good. • ARGUS, NGI argus • EMI3 accounting/migration • Glexec • DPM modules patching over and over • Xrootdfederation setup
Our errors • Welearnedpuppet as wewereusingit • Wewrote modules withtoomany inter-dependencies • This preventspushingthem on github or puppetforgewithoutrefactoring • We do thingsome or many of our modules need a hugerefactoring to beconsidered usable by others. Wewill do thiswhenwe have time • Weavoïdedusinghiera at first • But hieraisdeeply hard-linked to CERN modules, soweenabledit in the end • Hierais simple, and allowed us anyway to distinguishmanagingpuppet code (the modules) from the configuration data (site name, IPs, filesystemUUIDs…) • Wepatchedstuffthatthenevolved:’( • We put passwords and md5 in git • Maybe git is an errortoo…
achievements • It took 2 years to fullymigrate to puppet. • But wediditwithverylimitedmanpower. • We not onlymigrated to puppet : • Wereinstalledeverything in SL6, EMI3 • Deployedpreprod and devenvironments • Withonly • 3 daysdowntime for storage • ~1 week for computing • We are managing one debian server • with the exact samemanifests. No or little extra work. • Wewere (one of) the first FR sites fully EMI3 compliant • One monthahead of deadline • Whilehalf of french sites againfailed to meet the EMI3 deadline • Evensome GRIF subsitesfailed. • Wehelped and are ready to help other French sites to getpuppet-kickstarted • wenow are «devops » ready (?) https://www.flickr.com/photos/7870793@N03/8266423479/
Whatnext ? • If/whenyaim dies, wewill replace it • We are testingslurm • Wewillthen replace torque2/maui (whichmight die anyway at next CVE) • And enablemultithreaded jobs on our GRID site • Wewant to test/deploy CEPH to replace *NFS in our cluster
Story END • Wecannow go on withnext challenges. • Migration isbehind us. https://www.flickr.com/photos/stf-o/9617058578/sizes/h/in/photostream/
Extra 1 : architecture • We are currently running puppet 3.5.1 withforeman 1.4 • With one single puppetmaster for 359 hosts • Loaded @ ~40% at peak times • We have 3 puppetenvironmentsmapping to 3 git branches • Dev • Preprod • Prod • Each git push instantly updates the 3 branches on the puppet master. • Wedevelop in the devbranch, thenmergeintopreprod. • If preproddoes not fail. Wethenmergeintoprod. • Wesometimescreate local branches, to track changes of huge modules updates • Werecentlydeployed the puppetdb, in order to automate monitoring setup. • Our check_mkisnowautomated : new machines are automaticallymonitored
Extra 2 : performance issues • master load : client splay option helped • graph analysis (usinggephi) alsohelpedlimitdependencies and erradicateuseless N-to-M dependencies – thisis a « simple » WN graph…