Download
1 / 9
100 likes | 511 Views
Bioinformatics: Theory and Practice – Striking a Balance (a plea for teaching, as well as doing, Bioinformatics). The spectrum of experimental Biology Practice – Theory. Theory (population/statistical genetics) Theory: 80+ years of Mathematical Biology Methods: Ag,RFLPs,SNPs …. Practice

E N D
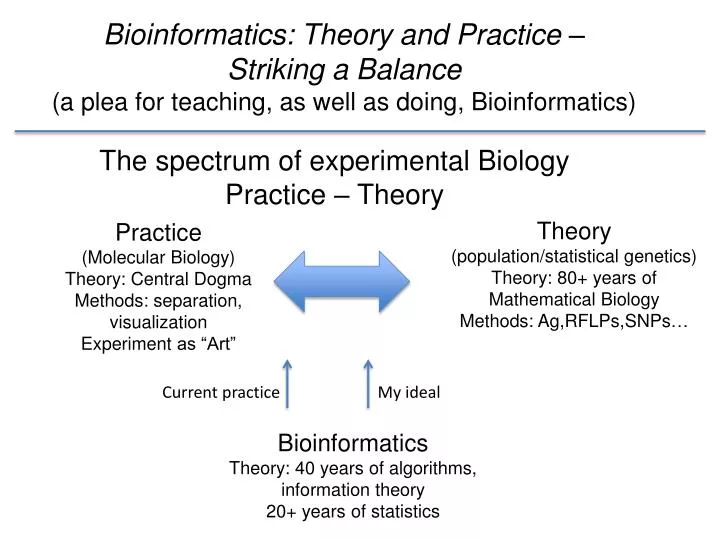
Bioinformatics: Theory and Practice – Striking a Balance(a plea for teaching, as well as doing, Bioinformatics) The spectrum of experimental BiologyPractice – Theory Theory (population/statistical genetics) Theory: 80+ years of Mathematical Biology Methods: Ag,RFLPs,SNPs… Practice (Molecular Biology) Theory: Central Dogma Methods: separation, visualization Experiment as “Art” Current practice My ideal Bioinformatics Theory: 40 years of algorithms, information theory 20+ years of statistics
Teaching and Bioinformatics What is the goal? • Learning Biology / learning Computer Science • Becoming "computer literate"scripting/programming • Exploring uncertainty • experimental shortcomings • computational biases • Utility – getting something done Bioinformatics is challenging because biology is complicated and idiosyncratic
Biology: A “clean” experiment –Internal positive and negative controls Southern blot of human class-mu Glutathione transferase genes from individuals with low (-) or high (+) GT-tSBO activity. RFLP independent of GT-tSBO Bands found with high GT-tSBO (GSTM1) • When GSTM1 is present, it is detected • When it is not detected, it is absent
Bioinformatics –ambiguity or computational error? • D3BUQ5 is “clearly” homologous to GSTA6_RAT, aligning from beginning to end • Does it have a GST_C domain? • Does it have glutathione transferase activity? • Could it be a steroid isomerase? Prostaglandin synthetase?
Why is Bioinformatics “hard”? Bioinformatics is at the intersection of Biology, Computer science, and Statistics • What is interesting to Computer Scientists, – algorithms, optimality – is less relevant to Biologists (text book bias) • “irrelevant” parameters for Computer Scientists – DNA vs protein – are important in practice • Statistics are central, and the statistical perspective is not well integrated into either Biology or CS curricula • The biological assumptions behind a “null hypothesis” are rarely explicit and often idealistic • Biologists do experiments (CS folks like theory). If it works, use it. Bioinformatics uses "hard/true/reproducible" techniques to solve "soft/ambiguous/varying" biological questions. A teaching "opportunity"
Alberts is wrong about sequence similarity(three times in three claims) “With such a large number of proteins in the database, the search programs find many nonsignificant matches, resulting in a background noise level that makes it very difficult to pick out all but the closest relatives. Generally speaking, one requires a 30% identityin sequence to consider that two proteins match. However, we know the function of many short signature sequences ("fingerprints"), and these are widely used to find more distant relationships.” – Alberts, Molecular Biology of the Cell (5thed, 2007) p. 139 • Sequences producing statistically significant alignments ALWAYS share a common structure • Many significant alignments share < 30% identity (<25% identity is routine, and <20% identity can be significant) • In the absence of significant similarity, “fingerprints” should never be trusted.
How can we teach better? • Discuss the strengths and weaknesses of data resources • Examine how published protocols go out of date (or are optimized for different problems). Examine potential weaknesses – what do the protocols assume? • Review high-profile papers with mistaken conclusions to understand what went wrong.
Biology 4XXX – Bioinformatics and Functional Genomics3hr lecture, 1hr lab • Introduction to Unix / perl (python) scripting / web resources • programming by imitation • similarity searching / domain identification • homology, scoring matrices • errors in domain annotation (why) • multiple sequence alignment • sequences vs domains • evolutionary tree-building • finding the best tree • evaluating alternative trees • where is the uncertainty (why) • Introduction to 'R' statistical language • programming by imitation • Expression analysis • read mapping, read counting • Motif extraction, mapping • motif independence? • Pathway analysis – gene enrichment • Gene models and alternative splicing • which gene/splicing models supported?
Computational and Comparative GenomicsOct 29 – Nov 4, 2014(application deadline July 15, 2014)




















