Download
1 / 39
390 likes | 485 Views
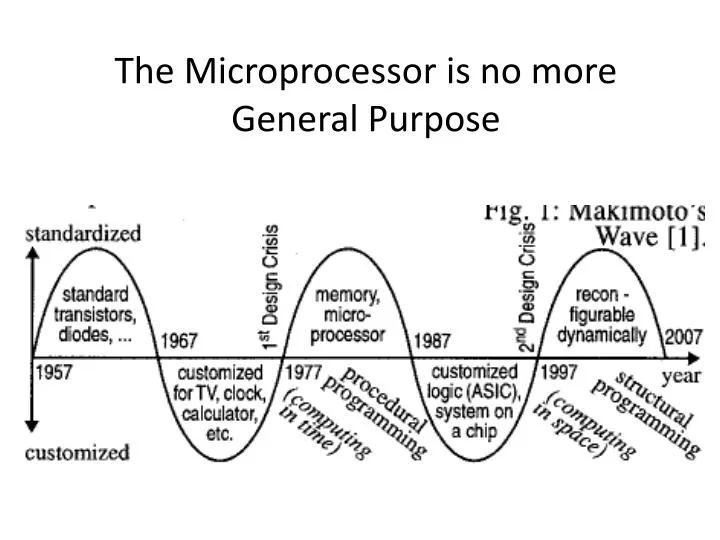
The Microprocessor is no more General Purpose. Design Gap. Problems with Fine Grained Approach FPGAs. Area in-efficient Percentage of chip area for wiring far too high Too slow Unavoidable critical paths too long Routing and Placement is very complex. Problems with Fine Grained FPGAs.

E N D
Problems with Fine Grained Approach FPGAs • Area in-efficient • Percentage of chip area for wiring far too high • Too slow • Unavoidable critical paths too long • Routing and Placement is very complex
Coarse Grained Reconfigurable computing • Uses reconfigurable arrays with path-widths greater than 1 bit • More area-efficient • Massive reduction in configuration memory and configuration time • Drastic reduction in complexity of Placement & Routing
Coarse Grained ArchitecturesClassification • Mesh-based • Linear Arrays based • Cross-bar based
Mesh Based Architectures • Arranges PEs in a 2-D array • Encourages nearest neighbor links between adjacent PEs • Eg. KressArray, Matrix, RAW, CHESS
Architectures based on Linear Arrays • Aimed at mapping pipelines on linear arrays • If pipeline has forks longer lines spanning whole or part of the array are used • Eg. RaPiD, PipeRench
Cross-bar based Architectures • Communication Network is easy to route • Uses restricted cross-bars with hierarchical interconnect to save area • Eg. PADDI-1, PADDI-2, Pleiades
EGRA • Architectural template to enable design space exploration • Execute expressions as opposed to operations • Supports heterogeneous cells and various memory interfaces
EGRA – at array level • Organized as a mesh of cells of three types • RACs • Memories • Multipliers • Cells are connected using both nearest neighbor and horizontal-vertical buses • Each cell has a I/O interface, context memory and core
EGRA Operation • DMA mode • Used to transfer data in bursts to EGRA • To program cells and to read/write from scratchpad memories • Execution mode • Control unit orchestrates data flow between cells
EGRA Memory Interface • Data register at the output of computational cells • Memory cells can be scattered around in the array • A scratchpad memory outside reconfigurable mesh
Interconnection Topology • Hierarchical • Level 1 used within 4x4 quadrant to provide nearest neighbor connectivity • Interleaved Horizontal and Vertical connectivity of length two • Each RC can receive data from at most two other RCs and send data to at-most four other RCs • Data and control across quadrants is guaranteed over Level 2 interconnection
Computational Strategies • Temporal computational load balancing • Spatial computational load balancing