Download
1 / 37
380 likes | 602 Views
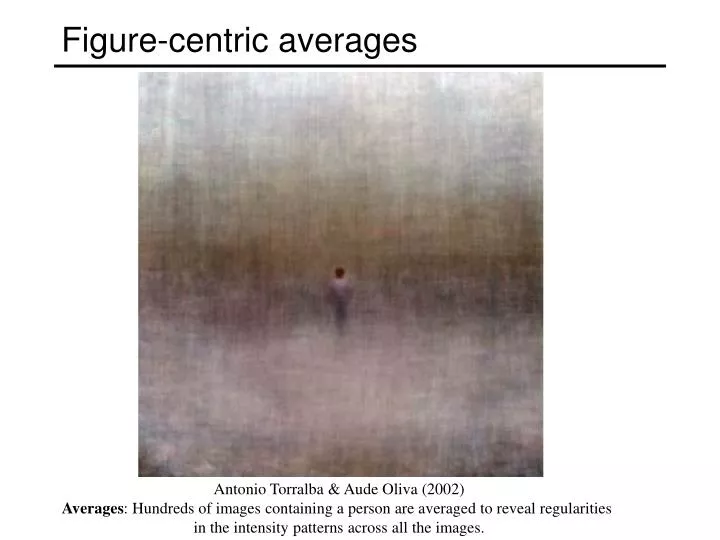
Figure-centric averages. Antonio Torralba & Aude Oliva (2002) Averages : Hundreds of images containing a person are averaged to reveal regularities in the intensity patterns across all the images. More by Jason Salavon. More at: http://www.salavon.com /.

E N D
Figure-centric averages Antonio Torralba & Aude Oliva (2002) Averages: Hundreds of images containing a person are averaged to reveal regularities in the intensity patterns across all the images.
More by Jason Salavon More at: http://www.salavon.com/
“100 Special Moments” by Jason Salavon Why blurry?
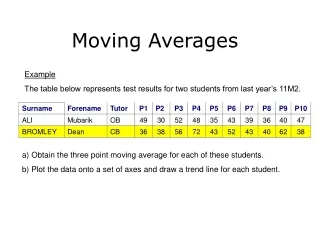
Computing Means • Two Requirements: • Alignment of objects • Objects must span a subspace • Useful concepts: • Subpopulation means • Deviations from the mean
Images as Vectors n = m n*m
Vector Mean: Importance of Alignment n = = m ½ + ½ = mean image n*m n*m
How to align faces? http://www2.imm.dtu.dk/~aam/datasets/datasets.html
Shape Vector = Provides alignment! 43
Average Face 1. Warp to mean shape 2. Average pixels http://graphics.cs.cmu.edu/courses/15-463/2004_fall/www/handins/brh/final/
Objects must span a subspace (0,1) (.5,.5) (1,0)
Example mean Does not span a subspace
Examples: Happy faces Young faces Asian faces Etc. Sunny days Rainy days Etc. Etc. Subpopulation means Average female Average male
Deviations from the mean - Mean X Image X = DX = X - X
= + = + 1.7 Deviations from the mean X DX = X - X
Manipulating Facial Appearance through Shape and Color Duncan A. Rowland and David I. Perrett St Andrews University IEEE CG&A, September 1995
Face Modeling • Compute average faces (color and shape) • Compute deviations between male and female (vector and color differences)
Deform shape and/or color of an input face in the direction of “more female” original shape color both Changing gender
Enhancing gender • more same original androgynous more opposite
Face becomes “rounder” and “more textured” and “grayer” original shape color both Changing age
Linear Subspace: convex combinations Any new image X can be obtained as weighted sum of stored “basis” images. Our old friend, change of basis! What are the new coordinates of X?
The Morphable Face Model • The actual structure of a face is captured in the shape vector S = (x1, y1, x2, …, yn)T, containing the (x, y) coordinates of the n vertices of a face, and the appearance (texture) vector T= (R1, G1, B1, R2, …, Gn, Bn)T, containing the color values of the mean-warped face image. Shape S Appearance T
The Morphable face model • Again, assuming that we have m such vector pairs in full correspondence, we can form new shapes Smodel and new appearances Tmodel as: • If number of basis faces m is large enough to span the face subspace then: • Any new face can be represented as a pair of vectors • (a1, a2, ... , am)T and (b1, b2, ... , bm)T !
Using 3D Geometry: Blinz & Vetter, 1999 show SIGGRAPH video
Joint Alignment: What’s It Good For? Erik Learned-Miller
Five Applications • Image factorizations • For transfer learning, learning from one example • Alignment for Data Pooling • 3D MR registration • EEG registration • Artifact removal • Magnetic resonance bias removal • Improvements to recognition algorithms • Alignment before recognition • Defining anchor points for registration • Find highly repeatable regions for future registrations
Congealing • Process of joint “alignment” of sets of arrays (samples of continuous fields). • 3 ingredients • A set of arrays in some class • A parameterized family of continuoustransformations • A criterion of joint alignment
Congealing Binary Digits • 3 ingredients • A set of arrays in some class: • Binary images • A parameterized family of continuous transformations: • Affine transforms • A criterion of joint alignment: • Entropy minimization
Criterion of Joint Alignment • Minimize sum of pixel stack entropies by transforming each image. A pixel stack
An Image Factorization “Latent Image” Observed Image Transform (Previous work by Grenander,, Frey and Jojic.)
The Independent Pixel Assumption • Model assumes independent pixels • A poor generative model: • True image probabilities don’t match model probabilities. • Reason: heavy dependence of neighboring pixels. • However! This model is great for alignment and separation of causes! • Why? • Relative probabilities of “better aligned” and “worse aligned” are usually correct. • Once components are separated, a more accurate (and computationally expensive) model can be used to model each component.
Congealing Before After A transform Each pair implicitly creates a sample of the transform T.
Character Models Image Kernel Density Estimator (or other estimator) P(IL) Latent Images Latent Image Probability Density for Zeroes Congealing Transform Kernel Density Estimator (CVPR 2003) P(T) Transform Probability Density for Zeroes Transforms
How do we line up a new image? Sequence of successively “sharper” models step 0 step 1 step N … … Take one gradient step with respect to each model.