Download
1 / 58
580 likes | 595 Views
Learn about Hash Tables and Hashing techniques for efficient data operations with constant average time complexity. Explore applications and implementation of Hash ADT. Discover the efficiency and advantages of Hash Tables.

E N D
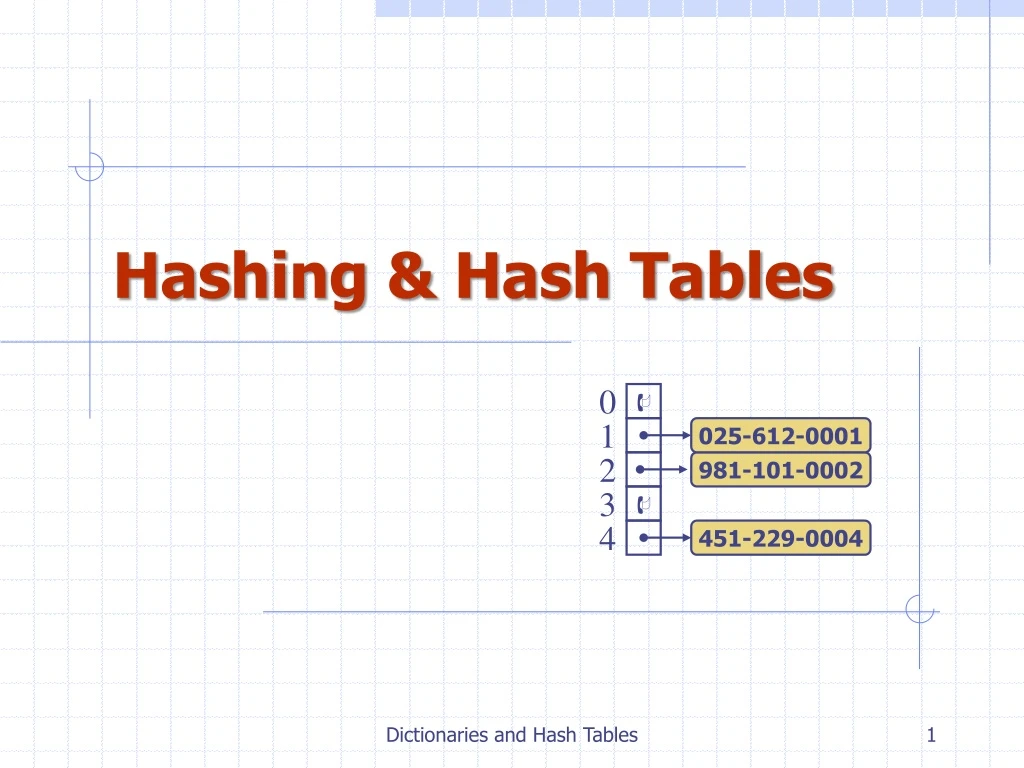
Hashing & Hash Tables 0 1 025-612-0001 2 981-101-0002 3 4 451-229-0004 Dictionaries and Hash Tables
Izmir University of Economics Introduction • Search Tree ADT was disccussed. • Now, Hash Table ADT • Hashing is a technique used for performing insertions and deletions in constant average time. • Thus, findMin, findMax and printAll are not supported.
Izmir University of Economics Tree Structures
Izmir University of Economics Goal • Develop a structure that will allow users to insert/delete/find records in • constant average time • structure will be a table (relatively small) • table completely contained in memory • implemented by an array • ability to access any element of the array in constant time
The hash ADT models a searchable collection of key-element items The main operations of a hash system (e.g., dictionary) are searching, inserting, and deleting items Multiple items with the same key are allowed Applications: address book credit card authorization mapping host names (e.g., www.me.com) to internet addresses (e.g., 128.148.34.101) Hash(dictionary) ADT operations: find(k): if the dictionary has an item with key k, returns the position of this element, else, returns a null position. insertItem(k, o): inserts item (k, o) into the dictionary removeElement(k): if the dictionary has an item with key k, removes it from the dictionary and returns its element. An error occurs if there is no such element. size(), isEmpty() keys(), Elements() Hash ADT
0 1 0256120001 2 9811010002 3 4 4512290004 … 9997 9998 2007519998 9999 Example • We design a hash table for a dictionary storing items (TC-no, Name), where TC-no (social security number) is a nine-digit positive integer • Our hash table uses an array of sizeN= 10,000 and the hash functionh(x) = last four digits of x
A dictionary is a hash table implemented by means of an unsorted sequence We store the items of the dictionary in a sequence (based on a doubly-linked lists or a circular array), in arbitrary order Performance: insertItem takes O(1) time since we can insert the new item at the beginning or at the end of the sequence find and removeElement take O(n) time since in the worst case (the item is not found) we traverse the entire sequence to look for an item with the given key Efficiency of Hash Tables
Implementation of Hashtables Which is better, an array or a linked list? Well, an array is better if we know how many objects will be stored because we can access each element of an array in O(1) time!!! But, a linked list is better if we have to change the number of objects stored dynamically and the changes are significant, or if there are complex relationships between objects that indicate “neighbors”. What to do? Combine the advantages of both!!! WELCOME HASHTABLES
Hashtables Wouldn't it be great if arrays could be made of infinite size without penalty? Then every object would have a place in the array
Hashtables Wouldn't it be great if arrays could be made of infinite size without penalty? Then every object would have a place in the array ... 453664 Object 453665 453666 ...
Hashtables Wouldn't it be great if arrays could be made of infinite size without penalty? Then every object would have a place in the array ... 453664 Object 453665 453666 ... But this is impractical
Hashtables So we “fold” the array infinitely many times. In other words, the number of spaces for holding objects is small but each space may hold lots of objects. ... Object 64 Object 65 66 Object ... ...
Hashtables But how do we maintain all the objects belonging to the same space? ... Object 64 Object 65 66 Object ... ...
Hashtables But how do we maintain all the objects belonging to the same space? Answer: object chaining by linked-list ... Object 64 Object 65 66 Object ... ...
Hashtables How do we locate an object? ... Object 64 Object 65 66 Object ... ...
Hashtables How do we locate an object? 1. Use a hash function to locate an array element ... Object 64 Object 65 66 Object ... ...
Hashtables How do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object ... Object 64 Object 65 66 Object ... ...
Hashtables How do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object ... Object 64 Object 65 66 Object ... ...
Hashtables How do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object ... Object 64 Object 65 66 Object ... ...
Hashtables How do we locate an object? 1. Use a hash function to locate an array element 2. Follow the linked list from that element to find the object ... Object 64 Object 65 66 Object ... ...
Hashtables Now the problem is how to construct the hash function and the hash table size!!!
Hashtables Now the problem is how to construct the hash function and the hash table size!!! Let's do the hash function first. The idea is to take some object identity and convert it to some random number.
Hashtables Now the problem is how to construct the hash function and the hash table size!!! Let's do the hash function first. The idea is to take some object identity and convert it to some random number. Consider... long hashvalue (void *object) { long n = (long)valfun->value(object); return (long)(n*357 % size); }
A hash functionh maps keys of a given type to integers in a fixed interval [0, N- 1] Example:h(x) =x mod Nis a hash function for integer keys The integer h(x) is called the hash value of key x A hash table for a given key type consists of A hash function h An array (called table) of size N When implementing a dictionary with a hash table, the goal is to store item (k, o) at index i=h(k) Hash Functions and Hash Tables
A hash function is usually specified as the composition of two functions: Hash code map:h1:keysintegers Compression map:h2: integers [0, N- 1] The hash code map is applied first, and the compression map is applied next on the result, i.e., h(x) = h2(h1(x)) The goal of the hash function is to “disperse” the keys in an apparently random way Hash Functions
Memory address: We reinterpret the memory address of the key object as an integer Good in general, except for numeric and string keys Integer cast: We reinterpret the bits of the key as an integer Suitable for keys of length less than or equal to the number of bits of the integer type (e.g., char, short, int and float on many machines) Component sum: We partition the bits of the key into components of fixed length (e.g., 16 or 32 bits) and we sum the components (ignoring overflows) Suitable for numeric keys of fixed length greater than or equal to the number of bits of the integer type (e.g., long and double on many machines) Hash Code Maps
Polynomial accumulation: We partition the bits of the key into a sequence of components of fixed length (e.g., 8, 16 or 32 bits)a0 a1 … an-1 We evaluate the polynomial p(z)= a0+a1 z+a2 z2+ … … +an-1zn-1 at a fixed value z, ignoring overflows Especially suitable for strings (e.g., the choice z =33gives at most 6 collisions on a set of 50,000 English words) Polynomial p(z) can be evaluated in O(n) time using Horner’s rule: The following polynomials are successively computed, each from the previous one in O(1) time p0(z)= an-1 pi(z)= an-i-1 +zpi-1(z) (i =1, 2, …, n -1) We have p(z) = pn-1(z) Hash Code Maps (cont.)
Hash Functions Using Horner’s Rule compute this by Horner’s Rule Izmir University of Economics 28
Horner’s Method: Compute a hash value Compute the has value of string junk A3X3+A2X2+A1X1+A0X0 Can be evaluated as X = 128 (((A3)X+A2)X+A1 )X+A0 ‘j’ ‘u’ ‘n’ ‘k’ Apply mod (%) after each multiplication!
Exercise: A hash function • #include<string.h> • unsigned int hash(const string &key, int tableSize){ • unsigned int hashVal = 0; • for (int i= 0;i <key.length(); i++) • hashVal = (hashVal * 128 + key[i]) % tableSize; • return hashVal; • }
Exercise: Another hash function • // A hash routine for string objects • // key is the string to hash. • // tableSize is the size of the hash table. • #include<string.h> • unsigned int hash(const string &key, int tableSize){ • unsigned int hashVal = 0; • for (int i= 0;i <key.length(); i++) • hashVal = (hashVal * 37 + key[i]); • return hashVal % tableSize; • }
Division: h2 (y) = y mod N The size N of the hash table is usually chosen to be a prime The reason has to do with number theory and is beyond the scope of this course Multiply, Add and Divide (MAD): h2 (y) =(ay + b)mod N a and b are nonnegative integers such thata mod N 0 Otherwise, every integer would map to the same value b Compression Maps
Collisions occur when different elements are mapped to the same cell Separte Chaining: let each cell in the table point to a linked list of elements that map there Chaining is simple, but requires additional memory outside the table 0 1 0256120001 2 3 4 4512290004 9811010004 Collision Handling
Handling Collisions Separate Chaining Open Addressing Linear Probing Quadratic Probing Double Hashing Izmir University of Economics 34
Separate Chaining Keep a list of elements that hash to the same value New elements can be inserted at the front of the list ex: x=i2 and hash(x)=x%10 Izmir University of Economics 35
Performance of Separate Chaining Load factor of a hash table, λ λ = N/M (# of elements in the table/TableSize) So the average length of list is λ Search Time = Time to evaluate hash function + the time to traverse the list Unsuccessful search= λnodes are examined Successful search=1 + ½*(N-1)/M (the node searched + half the expected # of other nodes) =1+1/2*λ Observation: Table size is not important but load factor is. For separate chaining make λ 1 Izmir University of Economics 36
Separate Chaining: Disadvantages Parts of the array might never be used. As chains get longer, search time increases to O(N) in the worst case. Constructing new chain nodes is relatively expensive (still constant time, but the constant is high). Is there a way to use the “unused” space in the array instead of using chains to make more space? Izmir University of Economics 37
Open addressing: the colliding item is placed in a different cell of the table Linear probing handles collisions by placing the colliding item in the next (circularly) available table cell Each table cell inspected is referred to as a “probe” Colliding items lump together, causing future collisions to cause a longer sequence of probes Example: h(x) = x mod13 Insert keys 18, 41, 22, 44, 59, 32, 31, 73, in this order Linear Probing 0 1 2 3 4 5 6 7 8 9 10 11 12 41 18 44 59 32 22 31 73 0 1 2 3 4 5 6 7 8 9 10 11 12
Linear Probing: i = h(x) = key % tableSize i A A A A A 0 49 49 49 Hash(89,10) = 9 Hash(18,10) = 8 Hash(49,10) = 9 Hash(58,10) = 8 Hash(9,10) = 9 1 58 58 2 9 3 4 5 6 7 8 18 18 18 18 9 89 89 89 89 89 After insert 89 After insert 18 After insert 49 After insert 58 After insert 9 Formula: A[(i+1) %N], A[(i+2) %N], A[(i+3) %N],... Employing wrap around
Quadratic Probing: i = h(x) = key % tableSize i A A A A A 0 49 49 49 Hash(89,10) = 9 Hash(18,10) = 8 Hash(49,10) = 9 Hash(58,10) = 8 Hash(9,10) = 9 1 2 58 58 9 3 4 5 6 7 8 18 18 18 18 9 89 89 89 89 89 After insert 89 After insert 18 After insert 49 After insert 58 After insert 9 Strategy: A[(i+12) %N], A[(i+2 2) %N], A[(i+3 2) %N], ..., Employing wrap around
Consider a hash table A that uses linear probing find(k) We start at cell h(k) We probe consecutive locations until one of the following occurs An item with key k is found, or An empty cell is found, or N cells have been unsuccessfully probed Search with Linear Probing Algorithmfind(k) i h(k) p0 repeat c A[i] if c= returnPosition(null) else if c.key () =k returnPosition(c) else i(i+1)mod N p p+1 untilp=N returnPosition(null)
To handle insertions and deletions, we introduce a special object, called AVAILABLE, which replaces deleted elements removeElement(k) We search for an item with key k If such an item (k, o) is found, we replace it with the special item AVAILABLE and we return the position of this item Else, we return a null position insertItem(k, o) We throw an exception if the table is full We start at cell h(k) We probe consecutive cells until one of the following occurs A cell i is found that is either empty or stores AVAILABLE, or N cells have been unsuccessfully probed We store item (k, o) in cell i Updates with Linear Probing
Izmir University of Economics Linear Probing Performance (1) • If the table is relatively empty, blocks of occupied cells start forming (primary clustering) • Expected # of probes • for insertions and unsuccessfulsearches is ½(1+1/(1-λ)2) • for successful searches is • ½(1+1/(1-λ))
Izmir University of Economics Linear Probing Performance (2) • Assumptions: If clustering is not a problem, large table, probes are independent of each other • Expected # of probes for unsuccessful searches(=expected # of probes until an empty cell is found) • Expected # of probes for successful searches(=expected # of probes when an element was inserted) • (=expected # of probes for an unsuccessful search) • Average cost of an insertion (fraction of empty cells = 1 -λ) (earlier insertion are cheaper)
Izmir University of Economics Double Hashing • f(i)=i*hash2(x) is a popular choice • hash2(x)should never evaluate to zero • Now the increment is a function of the key • The slots visited by the hash function will vary even if the initial slot was the same • Avoids clustering • Theoretically interesting, but in practice slower than quadratic probing, because of the need to evaluate a second hash function.
Izmir University of Economics Double Hashing • Typical second hash function hash2(x)=R − ( x % R ) where R is a prime number, R < N
Izmir University of Economics Double Hashing • Where do you store 99 ? hash(99)=t=9 • Let hash2(x)= 11 − (x % 11),hash2(99)=d=11 • Note: R=11, N=15 • Attempt to store key in array elements (t+d)%N, (t+2d)%N, (t+3d)%N … • Array: • 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 • 14 16 47 35 36 65 129 25 2501 99 29 • • t+22 t+11 t t+33 • attempts • Where would you store: 127?
Izmir University of Economics Double Hashing Let f2(x)= 11 − (x % 11) hash2(127)=d=5 Array: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 16 47 35 36 65 129 25 2501 99 29 t+10 t t+5 attempts Infinite loop!
Izmir University of Economics Rehashing • If the table gets too full, the running times for the operations will start taking too long. • When the load factor exceeds a threshold, double the table size (smallest prime > 2 * old table size). • Rehash each record in the old table into the new table. • Expensive: O(N) work done in copying. • However, if the threshold is large (e.g., ½), then we need to rehash only once per O(N) insertions, so the cost is “amortized” constant-time.
Izmir University of Economics Factors affecting efficiency • Choice of hash function • Collision resolution strategy • Load Factor • Hashing offers excellent performance for insertion and retrieval of data.
















