Download

1 / 63
660 likes | 695 Views
Learn about stochastic models in time series analysis, including trends, seasonality, and noise models. Explore concepts like stationarity, detrending techniques, and autocorrelation functions. Dive into removing cycles and seasons to analyze data effectively.

E N D
Math 419W/519 2015-01-16 Prof. Andrew Ross Eastern Michigan University Time Series
Overview of Stochastic Models Slightly, but not directly, related to Chapter 10 in our textbook, and no other chapters.
Outline • Day 1: • Look at the data! • Notation • Trends • Day 2: Seasonality • Day 3: Models for Noise, ACF/PACF, AR, MA, ARMA, etc • Day 4: Multivariate data, cross-correlation, filters
or else! Look at the data!
Atmospheric CO2 “Keeling curve”, from Wikipedia
Our Basic Procedure • Look at the data • Quantify any pattern you see • Remove the pattern • Look at the residuals • Repeat at step 2 until no patterns left
Our basic procedure, version 2.0 • Look at the data • Suck the life out of it • Spend hours poring over the noise • What should noise look like?
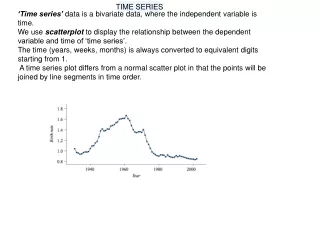
Stationarity • The upper-right-corner plot is Stationary. • Mean doesn't change in time • no Trend • no Seasons (known frequency) • no Cycles (unknown frequency) • Variance doesn't change in time • Correlations don't change in time • Up to here, weakly stationary • Joint Distributions don't change in time • That makes it strongly stationary
Our Basic Notation • Time is “t”, not “n” • even though it's discrete • State (value) is Y, not X • to avoid confusion with x-axis, which is time. • Value at time t is Yt, not Y(t) • because time is discrete • Of course, other books do other things.
Detrending: deterministic trend • Deterministic linear trend model: • Yt = m*t + b + random error
Detrending: deterministic trend • Deterministic linear trend model: • Yt = m*t + b + random error • Fit a plain linear regression, then subtract it out: • Fit Yt = m*t + b, • New data is Zt = Yt – m*t – b • Or use quadratic fit, exponential fit, etc.
Detrending: stochastic trend • Y(t+1) = Yt + m + random error • Differencing • For linear trend, new data is Zt = Yt – Yt-1 • To remove quadratic trend, do it again: • Wt = Zt – Zt-1=Yt – 2Yt-1 + Yt-2 • Like taking derivatives • What’s the equivalent if you think the trend is exponential, not linear? • Y(t+1)=1.03*Yt + random error • Compute Y(t+1)/Yt • Hard to decide: regression or differencing?
Wisdom on Stochastic vs Deterministic • From users.vcu.org/~sppeters/econ641/StochasticTrendModels.doc : “Nelson and Plosser wrote an interesting seminal paper in 1992 on this topic and argued that most macroeconomic series are difference stationary (meaning they have stochastic trends and removal using the estimated time trend would have resulted in serious and spurious specification).”Seminal paper:Nelson, C.R. and Plosser, C.I. (1982), Trends and Random Walks in Macroeconomic Time Series, Journal of Monetary Economics, 10, 139–162.R data available at http://rss.acs.unt.edu/Rdoc/library/urca/html/NPORG.htmlClassroom discussion at users.vcu.org/~sppeters/econ641/StochasticTrendModels.doc • Actuary thoughts on lifespans and deterministic vs. stochastic trends: http://www.soa.org/library/monographs/retirement-systems/living-to-100-and-beyond/2008/january/mono-li08-6a-chan.pdf • Deterministic and stochastic trends in the time series models: A guide for the applied economistRao, B. Bhaskara (2007):http://mpra.ub.uni-muenchen.de/3580/ • More in notes field
Removing Cycles/Seasons • Will get to it later. • For the next few slides, assume no cycles/seasons.
A brief big-picture moment • How do you compare two quantities? • Multiply them! • If they’re both positive, you’ll get a big, positive answer • If they’re both big and negative… • If one is positive and one is negative… • If one is big&positive and the other is small&positive…
Where have we seen this? • Dot product of two vectors • Proportional to the cosine of the angle between them (do they point in the same direction?) • Inner product of two functions • Integral from a to b of f(x)*g(x) dx • Covariance of two data sets x_i, y_i • Main idea is Sum_i (x_i * y_i)
Autocorrelation Function • How correlated is the series with itself at various lag values? • E.g. If you plot Yt+1 versus Yt and find the correlation, that's the correl. at lag 1 • ACF lets you calculate all these correls. without plotting at each lag value. • ACF is a basic building block of time series analysis.
Properties of ACF • At lag 0, ACF=1 • Symmetric around lag 0 • Approx. confidence-interval bars around ACF=0 • To help you decide when ACF drops to near-0 • Less reliable at higher lags • Often assume ACF dies off fast enough so its absolute sum is finite. • If not, called “long-term memory”; e.g. • River flow data over many decades • Traffic on computer networks
How to calculate ACF • R, Splus, SAS, SPSS, Matlab, Scilab will do it for you • Excel: download PopTools (free!) • http://www.cse.csiro.au/poptools/ • Excel, etc: quick-and-almost-right way: =correl(data set with absolute references, same data set without absolute references) =correl( $B$11:$B$200, B11:B200)
ACVF at lag h • Y-bar is mean of whole data set • Not just mean of N-h data points • Left side: old way, can produce correl>1 • Right side: new way (see Notes field below) • Difference is “End Effects” • Pg 30 of Peña, Tiao, Tsay; also see notes below • (if it makes a difference, you're up to no good?)
Common Models • White Noise • AR • MA • ARMA • ARIMA • SARIMA • ARMAX • Kalman Filter • Exponential Smoothing, trend, seasons
White Noise • Sequence of I.I.D. Variables et • mean=zero, Finite std.dev., often unknown • Often, but not always, Gaussian
AR: AutoRegressive • Order 1: Yt=a*Yt-1 + et • E.g. New = (90% of old) + random fluctuation • Order 2: Yt=a1*Yt-1 +a2*Yt-2+ et • Order p denoted AR(p) • p=1,2 common; >2 rare • AR(p) like p'th order ODE • AR(1) not stationary if |a|>=1 • E[Yt] = 0, can generalize
Things to do with AR • Find appropriate order • Estimate coefficients • via Yule-Walker eqn. • Estimate std.dev. of white noise • If estimated |a|>0.98, try differencing.
MA: Moving Average • Order 1: • Yt = b0et +b1et-1 • Order q: MA(q) • In real data, much less common than AR • But still important in theory of filters • Stationary regardless of b values • E[Yt] = 0, can generalize
ACF of an MA process • Drops to zero after lag=q • That's a good way to determine what q should be!
ACF of an AR process? • Never completely dies off, not useful for finding order p. • AR(1) has exponential decay in ACF • Instead, use Partial ACF=PACF, which dies after lag=p • PACF of MA never dies.
AR(2) can have cyclic steady state • Requirements for stationarity:http://freakonometrics.hypotheses.org/12081x_t = phi_1 x_(t-1) + phi_2 x_(t-2) + epsilon_t • needsphi2 - phi1 < 1phi2 + phi1 < 1abs(phi2) < 1 See note fieldbelow
Quick AR(2) Coeff. calculation • page 61-62:\hat{\alpha}_1 \approx r_1 (1-r_2) / (1-r_1^2)\hat{\alpha}_2 \approx (r_2 - r_1^2)/(1-r_1^2)where alpha_2 is the coefficient at lag 2. "The coefficient alphahat_2 is called the (sample) partial autocorrelation coefficient of order two.”
ARMA • ARMA(p,q) combines AR and MA • Often p,q <= 1 or 2
ARIMA • AR-Integrated-MA • ARIMA(p,d,q) • d=order of differencing before applying ARMA(p,q) • For nonstationary data w/stochastic trend
SARIMA, ARMAX • Seasonal ARIMA(p,d,q)-and-(P,D,Q)S • Often S= • 12 (monthly) or • 4 (quarterly) or • 52 (weekly) • Or, S=7 for daily data inside a week • ARMAX=ARMA with outside explanatory variables (halfway to multivariate time series)
State Space Model, Kalman Filter • Underlying process that we don't see • We get noisy observations of it • Like a Hidden Markov Model (HMM), but state is continuous rather than discrete. • AR/MA, etc. can be written in this form too. • State evolution (vector): St = F * St-1 + ht • Observations (scalar): Yt = H * St + et
ARCH, GARCH(p,q) • (Generalized) AutoRegressive Conditional Heteroskedastic (heteroscedastic?) • Like ARMA but variance changes randomly in time too. • Used for many financial models
Exponential Smoothing • More a method than a model.
Exponential Smoothing = EWMA • Very common in practice • Forecasting w/o much modeling of the process. • At = forecast of series at time t • Pick some parameter a between 0 and 1 • At = a Yt + (1-a)At-1 • or At = At-1 + a*(error in period t) • Why call it “Exponential”? • Weight on Yt at lag k is (1-a)k
How to determine the parameter • Train the model: try various values of a • Pick the one that gives the lowest sum of absolute forecast errors • The larger a is, the more weight given to recent observations • Common values are 0.10, 0.30, 0.50 • If best a is over 0.50, there's probably some trend or seasonality present
Holt-Winters • Exponential smoothing: no trend or seasonality • Excel/Analysis Toolpak can do it if you tell it a • Holt's method: accounts for trend. • Also known as double-exponential smoothing • Holt-Winters: accounts for trend & seasons • Also known as triple-exponential smoothing • http://www.solver.com/xlminer/help/time-series-analysisXlminer: also does Holt-Winters and SARIMA ( Seasonal ARIMA )If we fit ARIMA (0,1,1) the result is same as exponential smoothing. ARIMA (0,2,2) works same as double exponential smoothing.
Guidelines on forecasting for electric power demand • https://www.misoenergy.org/Library/Repository/Communication%20Material/Key%20Presentations%20and%20Whitepapers/Peak%20Forecasting%20Methodology%20Review%20Whitepaper.pdfpage 11:Description of equations including: o Variables (data series) used Full names Abbreviations used Description of variable Data source Links to data used in development o Statistical output for estimations (as typically provided by software) adjusted R² coefficient values standard errors of coefficients t-statistics of coefficients standard error of regression Durbin-Watson statistic mean of dependent variable values used standard deviation of dependent variable values used time span of data employed in estimation o Graphical depiction of residuals o Tabular presentation of residuals o Graphical depiction of fitted and actual dependent variable values o Description of any adjustments made to data employed in equation Non-statistical assessment of the reasonableness of the estimated coefficients
Additive vs Multiplicative Seasonality • CrystalBall software menu:
Multivariate • Along with ACF, use Cross-Correlation • Cross-Correl is not 1 at lag=0 • Cross-Correl is not symmetric around lag=0 • Leading Indicator: one series' behavior helps predict another after a little lag • Leading means “coming before”, not “better than others” • Can also do cross-spectrum, aka coherence
Cross-Correlation Thoughts page 158:... the variances of sample cross-correlations depend on the autocorrelation functions of the two components. In general, the variances will be inflated. Thus, even for moderately large values of N up to about 200, or even higher, it is possible for two series, which are actually unrelated, to give rise to apparently "large" cross-correlation coefficients, which are spurious, in that they arise solely from autocorrelations within the two time series. Thus, if a test is required for non-zero correlation between two time series, then (at least) one of the series should first be filtered to convert it to (approximate) white noise. The same filter should then be applied to the second series before computing the cross-correlation function.
Cycles/Seasonality • Suppose a yearly cycle • Sample quarterly: 3-med, 6-hi, 9-med, 12-lo • Sample every 6 months: 3-med, 9-med • Or 6-hi, 12-lo • To see a cycle, must sample at twice its freq. • Demo spreadsheet • This is the Nyquist limit • Compact Disc: samples at 44.1 kHz, top of human hearing is 20 kHz
The basic problem • We have data, want to find • Cycle length (e.g. Business cycles), or • Strength of seasonal components • Idea: use sine waves as explanatory variables • If a sine wave at a certain frequency explains things well, then there's a lot of strength. • Could be our cycle's frequency • Or strength of known seasonal component • Explains=correlates
Correlate with Sine Waves • Ordinary covar: • At freq. Omega, (means are zero) • Problem: what if that sine is out of phase with our cycle?