Download

1 / 14
140 likes | 158 Views
Explore the concept of failover operations, uptime guarantees, and downtime causes for critical systems. Learn about local and geo-failover mechanisms, HA load balancing, and practical examples on ensuring system reliability.

E N D
Failover Procedures A. Cavalli A. Pagano
Lyon 27-29/03/2006 Outline • Failover idea • Local failover concepts • Points from last COD (Barcelona) • Geo-failover proposal • Conclusions
Lyon 27-29/03/2006 Failover idea • A backup operation that automatically switches to a standby database, server or network if the primary system fails or is temporarily shut down for servicing. • Failover is an important fault tolerance function of mission-critical systems that rely on constant accessibility. • Failover automatically and transparently to the user redirects requests from the failed or down system to the backup system that mimics the operations of the primary system.
Lyon 27-29/03/2006 Uptime… How much availability must we guarantee?
Lyon 27-29/03/2006 Downtime causes • Magic words are: • Redundancy • Remove SPOF (Single Point of Failure)
Lyon 27-29/03/2006 • LB: forward and balances requests from clients among a set of servers, single IP address. • Server Array: a set of servers running actual network services. • Shared Storage: so that it is easy for the servers to have the same contents and provide the same services.
Lyon 27-29/03/2006 Example HA load balance Split Brain... “STONITH”Shoot The Other Node In The Head DRBD = mirroring a whole block device via network. Like raid-1 --> SAN/NAS (GPFS?) HEARTBEAT = switch system when a machine go down --> (only Ping check, but services ?) MON = alert system and take a decision (mail,reboot...)
Lyon 27-29/03/2006 Points from COD-6 • SFT SERVER • Ask for the status of CNAF Oracle support: DONE CNAF is active in “3D Project”, Oracle replication tested, waiting for customers (contact is: barbara.martelli@cnaf.infn.it) • Register a new domain to do DNS and geographical failover:idea came out with Piotr and Kostas at COD-6: see the PROPOSAL • Implement the mechanism to detect failure and switch to backup: see the PROPOSAL –TODO • SFT SERVER replica installation started, but based on old documentation and release: need to be in sync with last release in production • SFT CLIENT • Client update: CVS (Piotr - SFT dev.) • Implement client failure detection and let job know where to publish: see the PROPOSAL -TODO
Lyon 27-29/03/2006 Points from COD-6 (2) • CIC PORTAL Web + DB (Oracle) + Lavoisier: we can do the same as SFT + rule: if just one element fails we switch all to a backup site • SFT ADMIN Failover is done with inclusion in CIC portal • GGUS • Local failover: 2 separate network accesses + heartbeat • Geo failover: too expensive • GSTAT 2nd GSTAT installed but still in baby-sitting with Min • MAILING LISTS Organize, centralize and replicate them (?): TODO
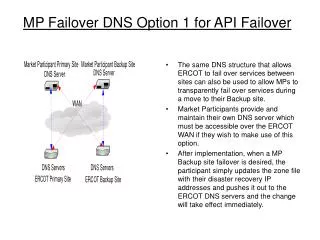
Lyon 27-29/03/2006 Proposal: Geographical Failover • New DNS domain to remap services under new names. E.g.: sft.gon.org points to the ip of sft.cern.ch • All the DNS servers in the participant sites are masters for the domain, and this means that: • there are no problems related to the master/slave solution (master down, stale slave records)… • but update must be done on each master (nsupdate) • Commercial solutions similar to this one are available, e.g. with spread DNSs and controllers, check frequency up to every 10 sec. • What happens when sft.cerc.ch goes down for any reason? … see next slide …
Lyon 27-29/03/2006 Geographical Failover (2) • Replication: proper technologies have to be chosen for the replication/synchronization of the backup instances: • Rely on Oracle teams support where a DB backend is needed: a slave-(ro)-replica must be able to become master-(rw) when needed • Web: static contents and dynamic procedures updated 1-2 times per day (rsync? scp with keys? AFS?) • Control: Should we attach action scripts to existing tools (nagios? mon?) or develop a completely new one (e.g. in python)? • The n-1 backup services control the master one: resolving cic.gon.org everyone knows who’s the master • When n-1 controllers detect a master failure the next in the list from “dig gon.org” become master and updates all the nameservers
Lyon 27-29/03/2006 Geographical Failover (3) Issues to take into account • Reverse resolution: do we care about? • SITE-1 is completely unreachable and SITE-2 has taken its place: we don’t want that its DNS is outdated when (1) come up again, because a sort of “split-brain” will occur. Frequent tries of nsupdate can be a solution? • Service masters (SFT, CIC, GSTAT…) shouldn’t be concentrated, so CONTROL must act per-service monitoring/switching • Can we rely on existing DNS servers/support or need to install/manage new ones? At CNAF nsupdate on institute server is almost for sure forbidden • DNS TTLs (and timeouts?) have to be short to be able to switch without the bad effect of old cached records (and slow responses?)
Lyon 27-29/03/2006 Conclusions • Local failover can be obtained with different approaches and technologies, we can invite each one other to implement it, but at last is up to the local admin • Something like a DNS based geographical failover is a complex but needed and interesting idea to be studied and put in place. Thanks to Kostas and Piotr who had the idea • Can we start with a good example of service and 2 sites for a pilot-test? • Comments, questions, ideas?