Download

1 / 27
270 likes | 388 Views
Lecture 5 Sept 9 Goals: Selection sorting Insertion sorting (completion) 2-d arrays Image representation Image processing examples. Recursive version of insert void insert(int k, int posn) {

E N D
Lecture 5 Sept 9 • Goals: • Selection sorting • Insertion sorting (completion) • 2-d arrays • Image representation • Image processing examples
Recursive version of insert void insert(int k, int posn) { // insert k as the first item of the list Node* tmp = new Node(k); if (head ==0) // in this case, posn must be 1 head = tmp; else if (posn == 1) { tmp->next = head; head = tmp; } else { List* temp = new List(head->next); temp->insert(k, posn - 1); head -> next = temp->head; } }
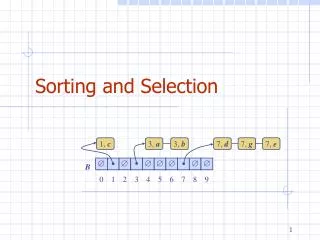
Selection Sort • Selection Sorting Algorithm: • During the j-th pass (j = 0, 1, …, n – 2), we will examine the elements of the array a[j] , a[j+1], …, a[n-1] and determine the index min of the smallest key. • Swap a[min] and a[j]. • selection_sort(int_array a) { • if (a.size() == 1) return; • for (int j = 0; j < n – 1; ++j) { • min = j; • for (int k= j+1; k<=n-1; ++k) • if (a[k] < a[min]) min = k; • swap a[min] and a[j]; • } • } • http://math.hws.edu/TMCM/java/xSortLab/
Algorithm analysis • Analysis is the process of estimating the number of computational steps performed by a program (usually as a function of the input size). • Useful to compare different approaches. Can be done before coding. Does not require a computer (paper and pencil). • Order of magnitude (rough) estimate is often enough. We will introduce a notation to convey the estimates. (O notation).
Analysis of selection sorting Consider the program to find the min number in an array: min = a[0]; for (j = 1; j < n; ++j) if (A[j] > min) min = A[j]; The number of comparisons performed is n – 1. loop starts with j = 1 and ends with j = n so the number of iterations = n – 1. In each iteration, one comparison is performed.
Selection sorting – analysis The inner loop: n – 1 comparisons during the first iteration of the inner loop n – 2 comparisons during the 2nd iteration of the inner loop . . . . 1 comparison during the last iteration of the inner loop Total number of comparisons = 1 + 2 + … + (n – 1) = n(n – 1)/ 2 (best as well as the worst-case)
O (order) notation • Definition: Let f(n) and g(n) be two functions defined on the set of integers. If there is a c > 0 such that f(n) <= c g(n) for all large enough n. Then, we say f(n) = O(g(n)). • Example: n2 + 2n – 15 is O(n2) • Rule: When the expression involves a sum, keep only the term with the highest power, drop the rest. You can also drop constant multiplying terms. • (3n2 + 2 n + 1) (4 n – 5) is O(n3)
How to Measure Algorithm Performance • What metric should be used to judge algorithms? • Length of the program (lines of code) since the personnel cost is related to this. • Ease of programming (bugs, maintenance) • Memory required • Running time (most important criterion) • Running time is the dominant standard • Quantifiable and easy to compare • Often the critical bottleneck • Particularly important when real-time response is expected
Average, Best, and Worst-Case • On which input instances should the algorithm’s performance be judged? • Average case: • Real world distributions difficult to predict • Best case: • Unrealistic • Rarely occurs in practice • Worst case: (most commonly used) • Gives an absolute guarantee • Easier to analyze
Examples • Vector addition Z = A+B for (int i=0; i<n; i++) Z[i] = A[i] + B[i]; T(n) = c n • Vector multiplication Z=A*B z = 0; for (int i=0; i<n; i++) z = z + A[i]*B[i]; T(n) = c’ + c1 n
Simplifying the Bound • T(n) = ck nk + ck-1 nk-1 + ck-2 nk-2 + … + c1 n + co • too complicated • too many terms • Difficult to compare two expressions, each with 10 or 20 terms • Do we really need all the terms? For approximation, we can drop all but the biggest term. • When n is large, the first term (the one with the highest power) is dominant.
Simplifications • Keep just one term! • the fastest growing term (dominates the runtime) • No constant coefficients are kept • Constant coefficients affected by machines, languages, etc. • Order of magnitude (as n gets large) is captured well by the leading term. • Example. T(n) = 10 n3 + n2 + 40n + 800 • If n = 1,000, then T(n) = 10,001,040,800 • error is 0.01% if we drop all but the n3 term
O (order) notation - formally • Definition: Let f(n) and g(n) be two functions defined on the set of integers. If there is a c > 0 such that f(n) <= c g(n) for all large enough n. Then, we say f(n) = O(g(n)). • Example: n2 + 2n – 15 is O(n2) • Rule: When the expression involves a sum, keep only the term with the highest power, drop the rest. You can also drop constant coefficients from this term. • (3n2 + 2 n + 1) (4 n – 5) is O(n3)
Problem size vs. time taken Assume the computer does 1 billion ops per sec.
2n n2 2n n2 n3 n log n n n3 n log n log n n log n
Basic rules and examples about magnitude and growth of functions • Constant = O(1) refers to functions f such that there is a constant c: f(n) < c for all n. • Ex: accessing an array element A[j] given j. • log n grows much slower than n. log n < 30 when n is a 1 trillion. • Ex: binary search on array of size n takes O(log n) time. • Usually, query systems are expected to perform in O(log n) time to answer about or update database of size n.
Magnitudes and growth functions • n may be acceptable for off-line processing but not for on-line (real-time) processing. When the data is unstructured (un-preprocessed), it usually takes O(n) time to give any non-trivial answer. • Ex: maximum in a given collection of keys, a key in the top 10% etc. • Algorithms whose time complexity is O(2n) is totally impractical.
Array representation of images • Image: A pixel is a square region on a display device that can be illuminated with one of the color combinations. • A wide range of colors can be specified using 3 bytes – one for each color R, G and B. • R = 255, G = 255, B = 255 represents White. • R = 0, G = 0, B = 0 represents Black. • Bitmap format: uncompressed, each pixel information stored. • Header + each pixel description
Image processing problems • image storage and access problems • format conversion • rotate, combine and other edit operations • compress, decompress • image enhancement problems • Remove noise • Extract features • Identify objects in image • Medical analysis (e.g. tumor or not)
An image filtering problem A small percentage (~ 5%) of pixels have become corrupted – randomly changed to arbitrary value. (salt and pepper noise). How should we remove this noise? Original image image with noise after filtering The image has become blurred, but this can be corrected.
Another kind of filter – cosine filter Helpful in removing periodic noise.
Mean filtering For each pixel, consider its eight neighbors. Replace its color value by the average of the 9 color values, itself and the 8 neighbors. Example: Suppose all the neighbors were blue pixels (0, 0, 150), but the center was red (noise), say (200, 0, 0). Then, the average value = (22, 0, 133). This color is much closer to blue, so the noise has been removed.
Algorithm for mean filtering I = input image; O = output image; w = width of the image; h = height of the image; for j from 1 to w-2 do for k from 1 to h-2 do O(j,k)->Blue = (I(j,k)->Blue + I(j-1,k)->Blue + I(j+1,k)->Blue + I(j,k-1)->Blue + I(j-1,k-1)->Blue+ I(j+1,k-1)->Blue +I(j,k+1)->Blue + I(j-1,k+1)->Blue+ I(j+k+1)->Blue)/9; . . . . // similarly for other colors end do; end do; On a 1024 x 1024 pixel image, how many operations does this perform? More generally, on an n x n image? Answer: O(n2) which is linear since the size of the input is O(n2). More precisely, ~ 30 n2 operations.
Algorithm for mean filtering I = input image; O = output image; w = width of the image; h = height of the image; for j from 0 to w-1 do O(0,j)->Blue = I(0,j)->Blue; // etc. for all colors end for; for k from 0 to h-1 do O(k,0)->Blue = I(k,0)->Blue; // etc. for all colors end for; for j from 1 to w-2 do for k from 1 to h-2 do O(j,k)->Blue = (I(j,k)->Blue + I(j-1,k)->Blue + I(j+1,k)->Blue + I(j,k-1)->Blue + I(j-1,k-1)->Blue+ I(j+1,k-1)->Blue +I(j,k+1)->Blue + I(j-1,k+1)->Blue+ I(j+k+1)->Blue)/9; . . . . // similarly for other colors end for; end for;
Median filter A problem with mean filter is that the image loses its sharpness. Median filter does a better job. Median filter examines the neighborhood pixel values and sort them, replace the current pixel value by the median value. Example: Sorted sequence: 37, 38, 38, 39, 40, 41, 42, 44, 234 A good choice to find the median is insertion sorting. Better than selection sorting. Why?
Median filter algorithm I = input image with random noise O = output image by median filtering I w = width of the image; h = height of the image; for j from 0 to w-1 do O(0,j)->Blue = I(0,j)->Blue; // etc. for all colors end for; for k from 0 to h-1 do O(k,0)->Blue = I(k,0)->Blue; // etc. for all colors end for; for j from 1 to w-2 do for k from 1 to h-2 do copy { I(j-1,k)->Blue, I(j+1,k)->Blue, I(j,k-1)->Blue, I(j-1,k-1)->Blue, I(j+1,k-1)->Blue, I(j,k+1)->Blue, I(j-1,k+1)->Blue, I(j+k+1)->Blue)} into a temp array of size 9; sort(temp) using insertion sorting O(j,k)-> Blue = temp[4]; . . . . // similarly for other colors end for; end for;
Time complexity of median filtering • Worst-case: • for each color component, sorting an array of size 9 involves about 45 comparisons and about 45 data movements. • Total number of operations is ~ 270 n2. • For a 1024 x 1024 image, the total number of operations is ~ 270 million. • Typical case is likely to be much better. Why? • On a fast computer, this may only take a few seconds.