Download

1 / 16
190 likes | 868 Views
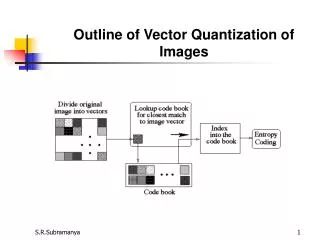
Vector Quantization. CAP5015 Fall 2005. Voronoi Region. Blocks: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1)

E N D
Vector Quantization CAP5015 Fall 2005
Voronoi Region • Blocks: • A sequence of audio. • A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) • A vector quantizer maps k-dimensional vectors in the vector space Rk into a finite set of vectors Y = {yi: i = 1, 2, ..., N}. Each vector yi is called a code vector or a codeword. and the set of all the codewords is called a codebook. Associated with each codeword, yi, is a nearest neighbor region called Voronoi region, and it is defined by: • The set of Voronoi regions partition the entire space Rk .
Two Dimensional Voronoi Diagram Codewords in 2-dimensional space. Input vectors are marked with an x, codewords are marked with red circles, and the Voronoi regions are separated with boundary lines.
Compression Formula • Amount of compression: • Codebook size is K, input vector of dimension L • In order to inform the decoder of which code vector is selected, we need to use bits. • E.g. need 8 bits to represent 256 code vectors. • Rate: each code vector contains the reconstruction value of L source output samples, the number of bits per sample would be: . • Sample: a scalar value in vector. • K: level of vector quantizer.
VQ vs SQ Advantage of VQ over SQ: • For a given rate, VQ results in a lower distortion than SQ. • If the source output is correlate, vectors of source output values will tend to fall in clusters. • E.g. Sayood’s book Exp 9.3.1 • Even if no dependency: greater flexibility. • E.g. Sayood’s book Exp 9.3.2
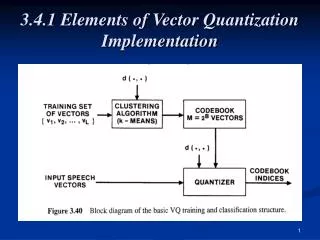
Algorithms • Lloyd algorithm: pdf-optimized quantizer, assume that distribution is known • LBG: (VQ) • Continuous (require integral ooperation) • Modified: with training set.
LBG Algorithm • Determine the number of codewords, N, or the size of the codebook. • Select N codewords at random, and let that be the initial codebook. The initial codewords can be randomly chosen from the set of input vectors. • Using the Euclidean distance measure clusterize the vectors around each codeword. This is done by taking each input vector and finding the Euclidean distance between it and each codeword. The input vector belongs to the cluster of the codeword that yields the minimum distance.
LBG Algorithm (contd.) 4.Compute the new set of codewords. This is done by obtaining the average of each cluster. Add the component of each vector and divide by the number of vectors in the cluster. where i is the component of each vector (x, y, z, ... directions), m is the number of vectors in the cluster. 5. Repeat steps 2 and 3 until the either the codewords don't change or the change in the codewords is small.
Other Algorithms • Problems: LBG is a greedy algorithm, may fall into Local minimum. • Four methods selecting initial vectors: • Random • Splitting ( with perturbation vector) Animation • Train with different subset • PNN (pairwise nearest neighbor) • Empty cell problem: • No input correspond to a output vector • Solution: give to other clusters, e.g. most populate cluster.
LBG for image compression • Taking blocks of images as vector L=NM. • If K vectors in code book: • need to use bits. • Rate: • The higher the value K, the better quality, but lower compression ratio. • Overhead to transmit code book: • Train with a set of images.
Rate_Dimension Product • Rate-dimension product • The size of the codebook increase exponentially with the rate. • Suppose we want to encode a source using R bits/sample. If we use an L-d quantizer, we would group L samples together into vectors. This means that we would have RL bits available to represent wach vector. • With RL bits, we can represent 2^(RL) output vectors.
Tree structured VQ • Set vectors in different quadrant. Only signs of vectors need to be compared. Thus reduce the number of comparisons by 2^L for L-d vector problem. • It works well for symmetric distribution. But not when we lose more and more symmetry.
Tree Structured Vector Quantizer • Extend to non-symmetric case: • Divide the set of output points into two groups, g0 and g1, and assign to each group a test vector s.t. output points in each group are closer to test vector assigned to that group than to the test vector assigned to the other group. • Label the two test vectors 0 and 1. • When we got an input vector, compare it against the test vectors. Depending on the outcome, the input is compared to the output points associated with the test vector closest to the input. • After these two comparisons, we can discard half of the output points. • Comparison with the test vectors takes the place of looking at the signs of the components to decide which set of output points to discard from contention. • If the total number of output points is K, we make( K/2)+2 comparisons instead of K comparisons. • Can continue to expand the number of groups. Finally: 2logK comparisons instead of K.( 2 comparisons with the test vectors and a total of logK stages
Tree Structured VQ (continued) • Since the test vectors are assigned to groups: 0, 1, 00,01,10,11,000,001,010,011,100,101,110,111 etc. which are the nodes of a binary tree, the VQ has the name “Tree Structured VQ”. • Penalty: • Possible increase in distortion: it is possible that at some stage the input is closer to one test vector while at the same time being closest to an output belonging to the rejected group. • Increase storage: output points from VQ codebook plus the test vectors.
Additional Links • Slides are adapted from: http://www.data-compression.com and http://www.geocities.com/mohamedqasem/vectorquantization/vq.html