Download

1 / 41
430 likes | 620 Views
ARCHITECTURE DE SYSTEMES RELATIONNELS Le SGBD ORACLE ORACLE a été édité par la société Oracle Corporation, implantée aux USA à RedWood Shores en Californie. Premier prototype 1977. Oracle version1 en 1979 premier SGBDR au monde.

E N D
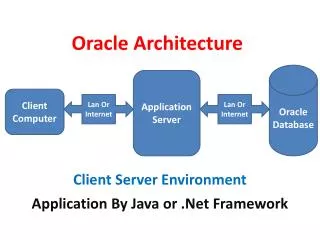
ARCHITECTURE DE SYSTEMES RELATIONNELS • Le SGBD ORACLE • ORACLE a été édité par la société Oracle Corporation, implantée aux USA àRedWoodShores en Californie.Premier prototype 1977. Oracle version1 en 1979 premier SGBDR au monde. • Depuis, les produits ORACLE n’ont cessé d’évoluer avec l’évolution des technologies de l’information et de la communication. Aujourd’hui ORACLE est un SGBD réparti, qui s’est tourné vers le Web. L’environnement ORACLE est un ensemble de produits autour de sa base de données : • ORACLE Server, gestionnaire de la base de données : il contrôle toutes les actions au niveau de la BD comme l’accès utilisateur et la sécurité, stockage et intégrité des données. • Le langage SQL et l’extension PL/SQL (langage comprenant des commandes procédurales supportant la gestion des erreurs et déclaration de variables) • ORACLE Designer est un ensemble de produits intégrés dans un référentiel unique d’entreprise pour la conception des applications. • ORACLE Developer : outils de développement d’applications client/serveur ou Internet. • ORACLE Discoverer : outil d’interrogation pour des utilisateurs qui ont besoin d’accéder par eux-mêmes aux données, Datawarehouse, Datamart.
Environnement des Produits ORACLE Designer c-ap Client Developer d-ap Discovererentr-d SQL*Plus PL/SQL SQL Serveur ORACLE SERVER
ORACLE est aujourd’hui considéré comme étant l’un des meilleurs SGBD dans le monde, ce qui nous a mené à vouloir comprendre le fonctionnement d’un tel système. La version actuelle d’ ORACLE est : Oracle11g . Les composants principaux de l’architecture d’ORACLE sont les suivants : • Les process • Les structures mémoires • Les fichiers
La System Global Area(SGA) représente l’ensemble des buffers nécessaires à la gestion des transactions. • La SGA est également appelée Shared Global Area, elle est partagée entre plusieurs utilisateurs. • La SGA est une zone mémoire allouée au démarrage d’une instance, elle est restituée à la fermeture de cette instance. • Les données de la SGA sont partagées par l’ensemble des utilisateurs connectés à un moment donné ; • elles sont divisées en plusieurs types de buffers :
Data Base Buffer Cache: Il contient les blocs de données, les blocs d’index, des blocs contenant les RollBack Segments(ils enregistrent les actions d’une transaction pour la reprise en cas de panne) et des blocs pour la gestion du système, les plus récemment utilisés; il peut contenir des données modifiées qui n’ont pas encore été enregistrées sur disque. • Redo Log Buffer: Il contient les redo entries, ensemble des modifications réalisées sur la base ; ces redo entries sont mémorisées sur un fichier redo log, qui pourra être utilisé en cas de panne. • Shared Pool ou zone de partage des ordres SQL: cette zone est utilisée pour mémoriser, analyser et traiter les ordres SQL soumis par les utilisateurs. Elle peut réutiliser les ordres SQL déjà exécutés.
Les Process Les Oracle Process sont divisés en trois catégories : les process utilisateurs, les Process Server et les background Process. • Les Background Process (Process détachés) prennent en charge les mécanismes internes d’Oracle. Une instance Oracle contient au minimum quatre background process : DBWR, LGWR, SMON et PMON. • DBWR : DataBaseWriter : Son rôle est de mettre à jour les fichiers de données. Les blocs de données modifiés en SGA sont stockés dans la base de données. • LGWR : LoGWriter : • Ce process écrit séquentiellement dans le fichier Redo Log courant des enregistrements Redo Log de la SGA. • SMON : System MONitor : Il vérifie si la base a été arrêtée proprement. Si ce n’est pas le cas, il récupère dans les fichiers redo log les enregistrements validés, qui n’ont pas encore été écrits dans la base par Oracle, pour les insérer. • PMON : ProcessMONitor : Il administre les différents process d’Oracle. Il est chargé de la libération des ressources occupées, par exemple dans le cas où un client éteint sa machine sans se déconnecter.
Les autres process sont les suivants : CKPT : Checkpoint ARCH : Archiver RECO : Recover LCKn : LOCK SNPn : Snapshot Refresh Snnn : Shared server Dnnn : Dispatcher Pnnn : ParallelQuery
Lesprocessutilsateurs • Un process utilisateur est démarré lorsqu’un utilisateur exécute un programme applicatif. • Le process utilisateur : • Exécute l’outil ou l’application et est considéré comme étant le client. • En guise d’exemple citons : SQL*plus, Forms, • Il transmet le SQL au process serveur et en reçoit les résultats.
Process Server : • ils prennent en charge les demandes des utilisateurs. • Ils sont responsables de la communication entre la SGA et le Process User. • Les taches du process serveur • Analyser et exécuter les commandes SQL • Lire les blocs de données à partir du disque dans les zones partagées de la SGA • Renvoyer les résultats des commandes SQL au Process utilisateur • L’instance d’ORACLE : C’est la combinaison de la SGA et des process détachés de la base de données. Quand une instance est démarrée, les zones mémoires de la SGA sont allouées et les process détachés sont lancés. Ne pas confondre une BD ORACLE et une instance d’ORACLE : l’instance est d’abord démarrée puis elle monte la BD (ouverture des fichiers). Les process serveurs et utilisateurs ne font pas partie de l’instance d’ORACLE.
Mécanisme : Lorsqu’un utilisateur demande une donnée, son processus va la chercher en SGA, si elle n’y est pas, le processus va la chercher dans les fichiers de données. Toutes les transactions sont enregistrées dans les fichiers Redo Log, en cas de problème la reprise après panne est assurée par le process SMON au démarrage d’une nouvelle instance.
Structure interne d’une base de données ORACLE : Tablespace SYSTEM Tablespace DATA Tablespace INDEX Table Index Table Table Index Index ROLLBACK SEGMENT Index Index DBfile1 DBfiles… • DBfiles…
LES TABLESPACES : Les données d’une base Oracle sont mémorisées dans une ou plusieurs unités logiques appelées tablespaceset physiquement dans des fichiers associés à ces tablespaces. Chaque base contient obligatoirement un tablespace SYSTEM, celui-ci contient les tables du dictionnaire de données, les procédures, les fonctions, les packages, les triggers et le rollback segment SYSTEM. Les autres tablespaces contiennent les segments de la base de données (tables, index,…). LES ROLLBACK SEGMENTS Une base de données contient un ou plusieurs ROLLBACK SEGMENTS ; un rollback segment enregistre les actions d’une transaction qui peuvent être annulées en cas d’incident. Le rollback segment SYSTEM est créé lors de la création de la base dans le tablespace SYSTEM ; il n’est utilisé que pour les transactions portant sur les données du dictionnaire. Un ou plusieurs autres rollback segments doivent exister pour les transactions portant sur des données utilisateur.
. 2. L’architecture générale de « SYSTEM R » Prog. en PL/1 ou Cobol Usager 1 Usager n Langage SQL RDS : Relationnel Data System • Gestion de catalogues • Optimisation de requêtes • Mécanismes d’autorisation • Contraintes d’intégrité Méta Base (Description relations de base et relations systèmes DBSS : Data Base Storage System • Gestionespace physique • Gestion des index • Gestion des transactions • Accèsconcurrents • Reprise après pannes BD
La structure de « System R » est relativement complexe, et le produit comporte un grand nombre de composants, que nous pouvons regrouper en deux grands sous-systèmes : • Le sous-système de données relationnel (RDS) qui gère globalement toutes les interactions avec les utilisateurs, et certaines fonctions systèmes comme l’optimisation des requêtes ou le contrôle des autorisations. C’est ce sous-système qui prépare à l’exécution de la requête. • Le sous-système de stockage qui peut être vu comme un S.G.B.D de bas niveau. Il comporte une interface interne qui fournit des opérateurs d’accès « un tuple à la fois » aux relations de base. Les appels aux fonctions du DBSS doivent spécifier explicitement les segments et index à utiliser. Le DBSS gère : • Les allocations en mémoire secondaire • La mémoire tampon • Le contrôle de transactions (concurrence et reprise après pannes) • Le maintien automatique des index (la méthode d’accès supportée est VSAM).
Exécution d’une requête • De manière générale, une requête est analysée en suivant les étapes suivantes : • analyse syntaxique de la question • optimisation • génération d’un plan d’exécution de la requête • Il existe deux manières d’interroger une base de données : • En mode interactif : • l’utilisateur interroge directement la base de données par des requêtes en langage SQL, directement interprétables. Un plan d’exécution de la requête est généré en passant d’abord par les phases d’analyse syntaxique et d’optimisation :
Requête ANALYSEUR SYSTEME DESTOCKAGE Arbre A OPTIMISEUR ENSEMBLES DES OPERATEUR RELATIONNELS Arbre A’ INTERPRETEUR Résultat de la Requête
L’analyseur transforme la question sous forme d’arbre où les nœuds correspondent aux opérateurs et les feuilles aux attributs et aux relations. Exemple : SELECT NOM, CODE FROM FOURNISSEUR, FOURNITURE WHERE VILLE = ‘TUNIS’ AND NP = ‘P2’ ; Cette requête SQL qui donne le nom et le code des fournisseurs domiciliés à Tunis et qui fournissent la pièce P2, est traduite par l’arborescence suivante :
Project NOM, CODE Restrict = Restrict Ville Tunis = .JOIN P2 NP = NF NF Fourniture Fournisseur
Différentes interprétations selon différents ordres d’application de ces opérateurs conduisent à des temps d’exploitation différents. D’où la nécessité de trouver des techniques qui permettent de trouver le meilleur ordre d’application des opérateurs, les meilleurs chemins d’accès aux relations. Ces techniques qui améliorent les performances des systèmes se retrouvent au niveau de l’optimiseur. En sortie de l’optimiseur on aura donc un arbre optimisé. L’arbre précédent sera transformé par l’optimiseur comme suit :
Project Nom, Code .JOIN = Restrict Restrict NF NF Fourniture Fournisseur = = Ville Tunis NP P2
Cet arbre est obtenu par application des opérateurs de réduction d’abord en laissant les opérateurs de jointure à la fin si possible. • L’interpréteur de requêtes fournit le résultat de la requête en exécutant les opérateurs contenus dans l’arborescence à l’aide de procédure associée à ces opérateurs. • Le système de stockage doit permettre une organisation efficace des données et un accès rapide grâce à l’implémentation de méthodes d’accès appropriées.
En mode programmé : • Les ordres SQL sont incorporés à un programme d’application écrit en langage de programmation PL/1, C, COBOL, ou autre,appelés langages hôtes. Dans ce cas la démarche nécessite une approche de précompilation. • Le précompilateur est un processeur qui regroupe les instructions SQL du programme d’application dans un module de requêtes de la BD, et les remplace dans le programme initial par des appels (CALLs) du langage hôte à un superviseur d’exécution qui surveille les programmes SQL.
Module Source $ select *fromemploye Module source modifié …Call M M : Module d’accès ou plan d’exécution (code machine) Compilateur Module objet Module exécutable Module d’accès DBSS : Gestion de données mémoire et zone tampon Supervision de l’exécution Précompilateur • Optimisation Editeur de liens Module exécutable Analyse syntaxique Génération de code
Fonctions du précompilateur : analyse le programme source, remplacement des ordres SQL par des instructions d’appels. Génération d’un module de requête de base de données qui passe par l’interpréteur SQL pour être exécuté. • Compilation du programme avec édition de liens ayant pour résultat un module exécutable. • L’exécution s’effectue par le sous-système de stockage : le module exécutable s’exécute normalement, lorsque le premier call est atteint, le superviseur prend la main et exécute le module d’accès en invoquant le gestionnaire de données et le gestionnaire des tampons.
Fonction Création / modification dans les SGBD relationnels La structure de données primaire dans les systèmes relationnels est la relation de base. La forme générale de la requête permettant la création d’une relation dans SQL est la suivante : • CREATE TABLE <nom de table> • (définition d’attribut [, définition d’attribut]…) ; Où définition d’attribut est : • <nom-attribut (type-donnée [, NONULL])> Les principaux types de données prédéfinis sont : • CHAR (n) : n précise la longueur maximum, par défaut 254 • DATE : format mm/jj/aa • DECIMAL(x,y) : x nombre total de chiffres • y détermine la place de la virgule en partant de la droite • FLOAT (x,y) • INTEGER • LOGICAL De plus, on peut imposer à la valeur d’un attribut de n’être jamais indéfinie (NONULL), évitant ainsi certaines incohérences dans une expression arithmétique dans laquelle une des opérandes est indéfinie.
Exemple : Notre base de données approvisionnement sera décrite à l’aide de cette commande de la manière suivante : CREATE TABLE FOURNISSEUR (NF CHAR(5) NONULL, NOM CHAR(20), CODE INTEGER, VILLE (CHAR (15)) ; CREATE TABLE PIECE (NP CHAR(5) NONULL, NOM CHAR(20), MATERIAU CHAR(6), POIDS INTEGER, VILLE CHAR (15)) ; CREATE TABLE FOURNITURE (NF CHAR (5) NONULL, NP CHAR(5) NONULL, QTE INTEGER) ;
Les ordres CREATE TABLE peuvent être émis à tout moment dans la vie de la base et non pas comme les systèmes classiques seulement à la phase de création du module ou du schéma de la base. Pour les clés primaires, il est recommandé de les définir dès la création de table car les données sont stockées selon l’ordre de cette clé. La commande de la création de table est dans ce cas : CREATE TABLE <nom de table> (définition d’attribut [, définition d’attribut]…) CONSTRAINT nom_constrainte PRIMARY KEY (nom_Att1,…,nom_Attn) Les attributs Att1, …Attn représentent les attributs qui composent la clé primaire.
Les SGBD Rel peuvent aussi modifier à tout moment le schéma des relations existantes. • Supprimer une relation : • DROP TABLE <nom table> ; • Ajouter un nouveau constituant afin de prendre en compte une information qui n’avait pas été prévue au départ. • ALTER TABLE <nom table> • ADD FIELD (< nom attribut> type de donnée) ; Exemple : ALTER TABLE FOURNITURE ADD FIELD (DATE CHAR (6)); Tous les n-uplets de la relation vont être étendus de trois à quatre champs. La valeur du nouveau champ est indéfinie dans tous les cas. Modifier une colonne existante : ALTER TABLE <nom table> MODIFY FIELD (< nom attribut> type de donnée) ; Exemple modifier la taille du nom dans la relation fournisseur : ALTER TABLE Fournisseur MODIFY FIELD NOM (CHAR (40)) ;
Après la création des tables, l’utilisateur peut maintenant procéder au chargement des données en utilisant l’instruction INSERT de SQL. Pour insérer la pièce P7 qui est un clou dans la relation PIECE nous écrivons : INSERT INTO PIECE (NP, NOM, MATERIAU, POIDS, VILLE) values (‘P7’, ‘clou’,?,?,?); Les trois derniers champs de la pièce insérée sont indéfinis, cela est possible car ces champs n’ont pas été définis avec l’option NONULL.
Pour l’insertion d’un grand nombre de n-uplets dans la relation, il est évident que la commande d’insertion s’avère inadéquate. De plus, les informations correspondantes se trouvent généralement à l’extérieur de la base de données, dans un fichier de saisie ou dans une autre base. Pour résoudre ce problème, les SGBD offrent plusieurs solutions : • En utilisant une fonction de chargement en invoquant une commande spéciale • du système et en lui précisant la relation à charger, le support des informations sources et les divers paramètres décrivant le format des données. • A l’aide d’un programme de lecture écriture écrit dans un langage hôte. • A l’aide du PL-SQL dans Oracle • On peut également copier certaines lignes à partir d’une autre relation. • Exemple : • INSERT INTO FOURNISSEUR-TUNIS (NF, NOM) • SELECT NF, NOM FROM FOURNISSEUR WHERE VILLE = ‘Tunis’ ; • Le nombre de colonnes et le type des colonnes dans le INSERT doivent correspondre à ceux du résultat du SELECT
Pour la modification d’une relation nous utilisons la commande UPDATE. UPDATE <nom de table> SET <nom attribut1> = nouvelle valeur, [nom attribut2 = nouvelle valeur, …] WHERE <prédicat> ; Exemple : modifier le code des fournisseurs qui sont localisés à Alger: UPDATE FOURNISSEUR SET CODE = CODE + 20 WHERE VILLE = ‘ALGER’ ; Modifier la ville des pièces en fer à l’identique de la ville du fournisseur F5 : UPDATE PIECE SET VILLE = (SELECT VILLE FROM FOURNISSEUR WHERE NF = ‘F5’) WHERE MATERIAU = ‘fer’ ;
Et enfin pour effacer certains n-uplets d’une relation : DELETE FROM <nom table> [WHERE <prédicat>] ; L’instruction efface les tuples complets qui satisfont le prédicat. Exemple : exprimer que les fournisseurs d’Alger ne fournissent plus de pièces : DELETE FROM FOURNITURE WHERE NF IN SELECT NF FROM FOURNISSEUR WHERE VILLE = ‘ALGER’;
Chemins d’accès Le schéma relationnel de la B.D. est le seul que doivent connaître les usagers ‘normaux’ de la base de données gérée par le SGBD. Il correspond à l’ensemble de tables de valeurs, sans description du stockage physique des n-uplets et des chemins d’accès qu’il faut utiliser pour retrouver les n-uplets d’une relation dans un ordre donné ou pour aller d’une relation à une autre. Aucune requête relationnelle ne précise les chemins d’accès aux informations ou l’ordre dans lequel les opérateurs de produit s’appliquent. C’est à l’administrateur de demander au système la création des chemins d’accès sur les relations stockées et au système de choisir, grâce à l’optimiseur, parmi les chemins disponibles celui qui est le plus adéquat (indépendance physique).Un chemin d’accès défini sur une relation est appelé INDEX. Un index est un ‘’arrangement’’ des tuples d’une relation en fonction des valeurs d’un constituant ou d’un groupe de constituants. Nous distinguons deux types d’index : index primaire et index secondaire. L’index primaire est défini sur la clé de la relation : à une valeur de la clé, la fonction index ramènera un tuple. L’index primaire fournit un accès direct aux tuples d’une relation, i.e., l’ordre des tuples sur la clé coïncide avec l’ordre physique. L’index secondaire peut être défini sur des constituants non clé : à une valeur de l’attribut de l’index, celui-ci ramènera un ou plusieurs tuples. L’index secondaire est un réarrangement logique des tuples d’une relation en fonction des valeurs d’un attribut ou groupe d’attributs.
En SQL, la commande de création d’un index est de la forme : • CREATE [UNIQUE] INDEX <nom index> ON < nom relation> • (nom attribut [ordre][,nom attribut [ordre]…] ) ; Où ordre est soit ASC ou DESC et s’il n’est pas spécifié, l’ordre ASC est pris par défaut. L’option UNIQUE permet d’une part de définir qu’un attribut (ou un groupe d’attributs) est clé discriminante de la relation et d’autre part de fournir un chemin d’accès direct aux n-uplets ayant une valeur de clé donnée. Pour définir les index primaires de notre base de données nous écrivons : CREATE UNIQUE INDEX XF ON FOURNISSEUR (NF) ; CREATE UNIQUE INDEX XP ON PIECE (NP) ; CREATE UNIQUE INDEX XFP ON FOURNITURE (NF, NP) ; La création d’un index secondaire selon la ville des fournisseurs serait : CREATE INDEX XV ON FOURNISSEUR (VILLE) ;
L’instruction de suppression d’un index d’une relation est : DROP INDEX <nom index> ; Remarque : En permettant l’exécution à tout moment des instructions CREATE INDEX et DROP INDEX le SGBD assure l’indépendance des programmes vis à vis des chemins d’accès (indépendance physique) : en effet, pour améliorer les performances d’une application, nous avons besoin de changer l’ordre de stockage des informations. Ceci est possible à l’aide de la définition d’un index selon le nouvel ordre sans toucher aux programmes d’application.
Catalogues ou méta-données Du point de vue d’un SGBD relationnel, une base de données comporte des relations de la base et des vues. De plus pour chaque relation stockée, il peut exister un ou plusieurs chemins d’accès. La manière la plus naturelle pour un SGBD relationnel de conserver toutes ces informations est de les stocker dans des catalogues qui sont eux mêmes des relations stockées dans la base ; le SGBD permet aux usagers de consulter, grâce au langage d’interrogation, les informations relatives à la description de la base. Principaux catalogues pour décrire une base de données relationnelle : • Relation : contient un n-uplet pour chaque relation de la base de données y compris lui même et les autres catalogues. On y trouve des informations sur le nom de la relation, son créateur, son degré, certaines statistiques sur son contenu etc.… • Attribut : pour chaque relation de la base décrite dans le catalogue Relation, le catalogue Attribut comporte autant de lignes qu’il y a d’attributs dans la relation. Chaque n-uplets décrit un attribut : son nom, son type, sa longueur, etc.… • Chemin d’accès : description des chemins d’accès définis sur les relations de la base. Pour chaque index, par exemple, on y trouve la relation et les constituants concernés et s’il s’agit d’un index primaire ou secondaire etc.… • …
Exemple d’une intension ainsi qu’une extension du schéma partiel des catalogues : Relation RELATION : Chacun de ses tuples est un descripteur de relations qui peuvent être de trois types : base, système, ou vue.
Relation ATTRIBUT : Chacun de ses tuples décrit un attribut d’une relation système, de base ou d’une vue
Relation INDEX : • Chaque tuple décrit une relation index crée sur les relations de base ou système










![Conceitos de SGBD Objeto-Relacional Oracle 10g [2]](https://cdn2.slideserve.com/4186122/conceitos-de-sgbd-objeto-relacional-oracle-10g-2-dt.jpg)