Download

1 / 31
320 likes | 513 Views
RELIABILITY AND VALIDITY Module 3. Rosseni Din Muhammad Faisal Kamarul Zaman Nurainshah Abdul Mutalib Universiti Kebangsaan Malaysia. RELIABILITY USING ALPHA CRONBACH CLASSIC TEST.

E N D
RELIABILITY AND VALIDITYModule 3 • Rosseni Din • Muhammad Faisal Kamarul Zaman • Nurainshah Abdul Mutalib • Universiti Kebangsaan Malaysia
RELIABILITY USING ALPHA CRONBACH CLASSIC TEST there are many ways to calculate validity, “cronbach coefficient alpha” is the most common. According to Nunally (1978) , minimum value for alpha cronbach is 0.70. the procedures are: 1. Click Analyze, choose scale then choose Reliability Analisis
Step 2 and 3 Select all items then move them into the Items box in Model section, make sure you choose Alpha
Step 4 Click on Statistic. For Descriptive choices, choose Item, Scale, Scale if Item Deleted. for inter-Item section, choose correlation. for Summaries, choose Correlation also.
Step 5 Click Continue then OK. Output will be displayed as follows: in matrix Inter-item correlation, all values must be POSITIVE. This means all items in one same characteristic. Next, we look at the Cronbach Alpha value that we hope for. minimum value ( Item Reliability) for Cronbach Alpha should be 0.7 ( Pallant : 2007).
next we look at the values inCorrected Item-Total Correlation - minimum value for this is 0.3 ( Pallant : 2007). The value in next table indicates that the item need to be reconsidered whether it should be removed. When we have few/limited items (e.g. less that 10), the inter item correlation valuewill be high which is within 0.48 to 0.76 ( Pallant : 2007).
Hands On Exercise:download survey3ED.sav from www.allenandunwin.com/spss
Procedure for checking reliability of a scale • 1. Analyze > Scale > Reliability Analysis • 2. click on all of the individual items that make up the scale (lifsat1, lifsat2, lifsat3, lifsat4, lifsat5). Move these into the box marked Items. • 3. In Model Section select Alpha
Procedure for checking reliability of a scale • 4. In Scale Label box type in the name of the scale or subscale (life satisfaction) • 5. Click on the Statistic button. In the Descriptive for section, click on Item, Scale and Scale if item deleted. In the Inter-item section, click on Correlations. In the Summariessection,click on Correlations • 6. Click on Continue and then OK
VALIDITY, RELIABILITY & PRACTICALITY Information from these slides onwards are taken and modified from Prof. Rosynella Cardozo Prof. Jonathan Magdalena
QUALITIES OF MEASUREMENT DEVICES • Validity Does it measure what it is supposed to measure? • Reliability How representative is the measurement? • Practicality Is it easy to construct, administer, score and interpret?
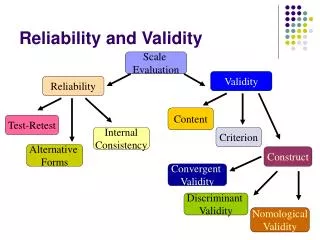
VALIDITY The term validity refers to whether or not a test measures what it intends to measure. On a test with high validity the items will be closely linked to the test’s intended focus. For many certification and licensure tests this means that the items will be highly related to a specific job or occupation. If a test has poor validity then it does not measure the job-related content and competencies it ought to. There are several ways to estimate the validity of a test, including content validity, construct validity, criterion-related validity (concurrent & predictive), convergent validity, discriminant validity and face validity.
VALIDITY • Content”: related to objectives and their sampling. • “Construct”: referring to the theory underlying the target. • “Criterion”: related to concrete criteria in the real world. It can be concurrent or predictive. • “Concurrent”: correlating high with another measure already validated. • “Predictive”: Capable of anticipating some later measure. • “Face”: related to the test overall appearance.
1. CONTENT VALIDITY Content validity refers to the connections between the test items and the subject-related tasks. The test should evaluate only the content related to the field of study in a manner sufficiently representative, relevant, and comprehensible.
2. CONSTRUCT VALIDITY It implies using the construct correctly (concepts, ideas, notions). Construct validity seeks agreement between a theoretical concept and a specific measuring device or procedure. For example, a test of intelligence nowadays must include measures of multiple intelligences, rather than just logical-mathematical and linguistic ability measures.
3. FACE VALIDITY Like content validity, face validity is determined by a review of the items and not through the use of statistical analyses. Unlike content validity, face validity is not investigated through formal procedures. Instead, anyone who looks over the test, including examinees, may develop an informal opinion as to whether or not the test is measuring what it is supposed to measure. While it is clearly of some value to have the test appear to be valid, face validity alone is insufficient for establishing that the test is measuring what it claims to measure.
QUALITIES OF MEASUREMENT DEVICES • Validity Does it measure what it is supposed to measure? • Reliability How representative is the measurement? • Practicality Is it easy to construct, administer, score and interpret?
RELIABILITY Reliability is the extent to which an experiment, test, or any measuring procedure shows the same result on repeated trials. Without the agreement of independent observers able to replicate research procedures, or the ability to use research tools and procedures that produce consistent measurements, researchers would be unable to satisfactorily draw conclusions, formulate theories, or make claims about the generalizability of their research.
RELIABILITY • “Equivalency”: related to the co-occurrence of two items • “Stability”: related to time consistency • “Internal”: related to the instruments • “Inter-rater”: related to the examiners’ criterion • “Intra-rater”: related to the examiners’ criterion
1. INTERNAL CONSISTENCY Internal consistency is the extent to which tests or procedures assess the same characteristic, skill or quality. It is a measure of the precision between the measuring instruments used in a study. This type of reliability often helps researchers interpret data and predict the value of scores and the limits of the relationship among variables. For example, analyzing the internal reliability of the items on a vocabulary quiz will reveal the extent to which the quiz focuses on the examinee’s knowledge of words.
2. EQUIVALENCY RELIABILITY Equivalency reliability is the extent to which two items measure identical concepts at an identical level of difficulty. Equivalency reliability is determined by relating two sets of test scores to one another to highlight the degree of relationship or association. For example, a researcher studying university English students happened to notice that when some students were studying for finals, they got sick. Intrigued by this, the researcher attempted to observe how often, or to what degree, these two behaviors co-occurred throughout the academic year. The researcher used the results of the observations to assess the correlation between “studying throughout the academic year” and “getting sick”. The researcher concluded there was poor equivalency reliability between the two actions. In other words, studying was not a reliable predictor of getting sick.
3. STABILITY RELIABILITY Stability reliability (sometimes called test, re-test reliability) is the agreement of measuring instruments over time. To determine stability, a measure or test is repeated on the same subjects at a future date. Results are compared and correlated with the initial test to give a measure of stability. This method of evaluating reliability is appropriate only if the phenomenon that the test measures is known to be stable over the interval between assessments. The possibility of practice effects should also be taken into account.
4. INTER-RATER RELIABILITY Inter-rater reliability is the extent to which two or more individuals (coders or raters) agree. Inter-rater reliability assesses the consistency of how a measuring system is implemented. For example, when two or more teachers use a rating scale with which they are rating the students’ oral responses in an interview (1 being most negative, 5 being most positive). If one researcher gives a "1" to a student response, while another researcher gives a "5," obviously the inter-rater reliability would be inconsistent. Inter-rater reliability is dependent upon the ability of two or more individuals to be consistent. Training, education and monitoring skills can enhance inter-rater reliability.
4. INTRA-RATER RELIABILITY Intra-rater reliability is a type of reliability assessment in which the same assessment is completed by the same rater on two or more occasions. These different ratings are then compared, generally by means of correlation. Since the same individual is completing both assessments, the rater's subsequent ratings are contaminated by knowledge of earlier ratings.
SOURCES OF ERROR • Examinee • (is a human being) • Examiner • (is a human being) • Examination • (is designed by and for human beings)
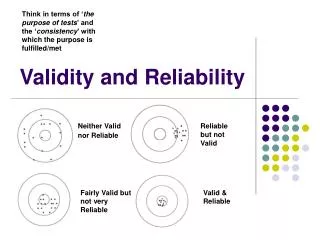
RELATIONSHIP BETWEEN VALIDITY & RELIABILITY Validity and reliability are closely related. A test cannot be considered valid unless the measurements resulting from it are reliable. Likewise, results from a test can be reliable and not necessarily valid.
QUALITIES OF MEASUREMENT DEVICES • Validity Does it measure what it is supposed to measure? • Reliability How representative is the measurement? • Practicality Is it easy to construct, administer, score and interpret?
PRACTICALITY It refers to the economy of time, effort and money in testing. In other words, a test should be… • Easy to design • Easy to administer • Easy to mark • Easy to interpret (the results)