Download

1 / 11
110 likes | 234 Views
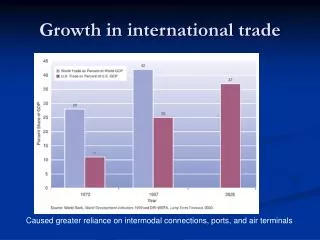
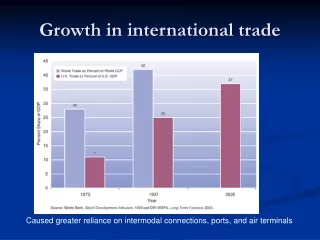
SELEKT in the International Trade in Services. International Trade in Services. Statistics on international trade in services, wages and transfers are based on a quarterly sample survey involving about 5 000 enterprises and organizations.

E N D
International Trade in Services Statistics on international trade in services, wages and transfers are based on a quarterly sample survey involving about 5 000 enterprises and organizations.
The variable of interest is valueand is reported for three levels Expenditure and income • for each company
The variable of interest is valueand is reported for three levels Expenditure and income • for each company • for each company and service
The variable of interest is valueand is reported for three levels Expenditure and income • for each company • for each company and service • for each company and service and country
The variable of interest is valueand is reported for three levels Expenditure and income • for each company • for each company and service • for each company and service and country The second level is the primary input in the statistical output.
The data structure Service Code 410 Computer services 411 Information services 432 Accounting Direction 1 Expenditure 5 Income
Potential impact The potential impacts of a variable value on the estimates are calculated as the weighted difference between the expected value and the observed value relative to the estimated standard errors of the estimated sums. Each type of output table has a coefficient of importance multiplied to the potential impact which creates a local score for selective editing. These coefficients are set to achieve a balanced editing of data on the three levels simultaneously. This minimizes the number of re-contacts with each company.
Expected values Selekt offers two possibilities to calculate the expected values: • Time series data for company, service and direction have been used when available, even if it consists of only one observation. • Cross sectional data for similar observations based on edit groups. The cross sectional data are a poor source of information to use when calculating the expected values. The edit groups are not homogenous. How to find good expected values for event-based data?