Download

1 / 16
160 likes | 209 Views
Explore binary encoding of characters, images, and more in computer storage. Learn about EBCDIC, ASCII, Unicode, and their usage in information interchange.

E N D
Department of Computer and Information Science,School of Science, IUPUI Information Representation:Characters and Images CSCI N305
Information Representation Review • All information must be rendered into binary in order to be stored on a computer. • Prior example of binary information representations include positive integers, negative integers, and floating point. • Besides numbers, almost all applications must store characters and string information. • Images are pervasive in today’s internet world and must be rendered in binary to be handled by internet browsers. • Crucial to make general purpose computers, computers that can easily perform many different tasks, is the idea that the program is just data. Like any other information, programs must be rendered into binary in order to be stored within a computer.
Character Representations • EBCDIC – IBM Mainframes • ASCII – PC workstations • Unicode – International Character sets
EBCDIC • EBCDIC • Expanded name Extended Binary Coded Decimal Interchange Code • Area covered 8-bit coded character set for information interchange between IBM computers • Sponsoring body Proprietary specification developed by IBM • Characteristics/description A set of national character sets for interchange of documents between IBM mainframes. Most EBCDIC character sets do not contain all of the characters defined in the ASCII code set but there is a special International Reference Version (IRV) code set that contains all of the characters in ISO/IEC 646 (and, therefore, ASCII). Several national versions have been updated to support the encoding of the euro sign (in lieu of the currency sign). • Usage Not much used outside of IBM and similar mainframe environments. When transmitting EBCDIC files between systems care needs to be taken to ensure that the systems are set up for the relevant national code set. • Further details available from Your local IBM office. • Other references Details of the most commonly used sets of EBCDIC codes can be obtained from http://www.dkuug.dk/i18n/charmaps which, however, has not necessarily been updated to cover the new code pages that also support the euro sign..
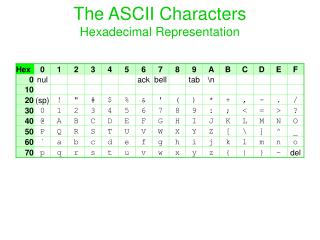
ASCII • ASCII • Expanded name American Standard Code for Information Interchange • Area covered 7-bit coded character set for information interchange • Sponsoring body American National Standards Institute (ANSI) • Source documents Information Systems – Coded Character Sets – 7-Bit American National Standard Code for Information Interchange (7-Bit ASCII) • Characteristics/description Specifies coding of space and a set of 94 characters (letters, digits and punctuation or mathematical symbols) suitable for the interchange of basic English language documents. Forms the basis for most computer code sets and is the American National Version of ISO/IEC 646. • Usage Used as the basic US code set for personal and workstation computers. • Further details available from ANSI, 25 West 43rd Street, New York, NY 10036, USA • Other references A list of ASCII codes can be obtained from http://www.dkuug.dk/i18n/charmaps/ANSI_X3.4-1968.
Unicode • From MSDN: Unicode can represent all of the world's characters in modern computer use, including technical symbols and special characters used in publishing. Because each Unicode code value is 16 bits wide, it is possible to have separate values for up to 65,536 characters. Unicode-enabled functions are often referred to as "wide-character" functions. Note that the implementation of Unicode in 16-bit values is referred to as UTF-16. For compatibility with 8- and 7-bit environments, UTF-8 and UTF-7 are two transformations of 16-bit Unicode values. For more information, see The Unicode Standard, Version 2.0.
Universal Character Set (Unicode) • ISO/IEC 10646 • Expanded name ISO/IEC 10646: Universal Multiple-Octet Coded Character Set (UCS) • Area covered Multilingual, multi-octet character set covering all major trading languages. The intent is to provide coding for all the characters of all the scripts of the world. • Sponsoring body ISO/IEC JTC1/SC2 and ISO/IEC JTC1/SC22 WG20 • Source documents • ISO/IEC 10646-1 Information technology -- Universal Multiple-Octet Coded Character Set (UCS) • Part 1: Architecture and Basic Multilingual Plane • Part 2: Supplementary Planes • ISO/IEC DIS 14651International string ordering and comparison -- Method for comparing character strings and description of the common template tailorable ordering • ISO/IEC PRF TR 14652Information technology -- Specification method for cultural conventions • ISO/IEC 14755:1997Information technology -- Input methods to enter characters from the repertoire of ISO/IEC 10646 with a keyboard or other input devices • Unicode 3.2 • RFC 2279UTF-8, a transformation format of ISO 10646 • Characteristics/description Integrates previous internationally/nationally agreed character sets into a single code set together with additional characters to previously encoded scripts and new, both current and ancient scripts. ISO/IEC 10646 is based on 4 octet (32-bit) coding scheme known as the "canonical form" (UCS-4), but a 2-octet (16-bit) form (UCS-2) is used for the Basic Multilingual Plane (BMP), where the missing two high order octets are assumed to be 00 00. The code set is split into 128 "groups" of 256 "planes", each containing 256 "rows" with 256 "cells" for characters. Each character is given a code position using multiple octets, the third (first) of which identifies the row containing the character and the fourth (second) its cell number. • Usage This standard has become the basic coding form for all 16 and 32-bit computer systems. Users of Internet Explorer 5, and XLink-aware XML browsers, can obtain more details about applications of ISO 10646 from our Diffuse Topic Map service. • Further details available from ISO and national standards bodies. • Other references Details of the Unicode standard, the repertoire and coding of which are identical to those of the ISO/IEC 10646 code set can be obtained from http://www.unicode.org.
Comparing Characters: Collating Sequence • If you look at the ASCII Character Code Table the ASCII binary number for “A” is 1000001, which is 65 decimal. The ASCII binary number for “a” is 1100001, which is 97 decimal. Therefore, “A” is less than “a”. A blank is stored as 0100000, or 32 decimal. The blank has the smallest value of the digits or characters. Rules: Upper case < lower case Space < any other character
Comparing Strings • A useful operation is the comparison of two strings. Two strings are related in the same three basic ways as number values. One string is either less than, equal to, or greater than the other. String comparison is usually based on the positions of the characters in the character set. • Scanning along both strings and comparing corresponding characters establish the relationship between two strings. The strings are equal as long as corresponding characters are equal. If two characters are different, the comparisons are based on their relative order in the character set. The character whose code is less belongs to the lesser string. • Ex. “abcd” < “abcz” • If the two strings are of different length, but identical up to the end of the shorter one, then the shorter string is the lesser of the two: • Ex. “abc” < “abcd” • If the two strings are of different length and consist of Upper and lowercase letters, Upper case letters come before lower case letter and a blank has a lower value than all other letters. • Ex. “AZZZ” < “Aaaah” • Below is an example of a comparison of strings that contain blanks. Scanning along both strings and comparing corresponding characters, you see the strings are equal for the first two characters. You then compare the blank and the t; you then reach the conclusion below. • Ex. “hi there” < “hit a ball”
Image Data Image Data Because of the number of different shapes, colors, textures, sizes and shadings of images, there is no standard representational format and there is with alphanumeric codes. There are 2 ways of representing images: 1 Bit map or raster images 2 Object or vector images are made up of simple geometrical elements. Each element is specified by its geometric parameters, its location in the picture and other details. Common Graphics Formats
Rastor Images • Bit map or raster images consist of an array of pixel values (pixel stands for 'picture element'). Each pixel represents the sampling of a small area of the picture.In its simplest form an image is represented as a long string of bits representing the rows of pixels in the image, where each bit is either 1 or 0 depending on whether the corresponding pixel is black or white. • Color images are only slightly more complicated, since each pixel can be represented by a combination of bits indicating the color of that pixel. It is common to record the color of each pixel as three components: red green blue • One byte is typically used to represent the intensity of each color component
Acknowledgements • A list of character standard was obtained from www.diffuse.org. • A portion of the discussion regarding character and string comparisons was obtained from Emad Hayajneh. • A portion of the discussion regarding images was obtained from Dr. Robert Stephens.