Download
1 / 49
490 likes | 503 Views
Explore the concept of cluster analysis, maximizing inter-cluster distances and minimizing intra-cluster distances. Learn the applications, similarity measures, and types of clustering for data summarization in various fields and industries.

E N D
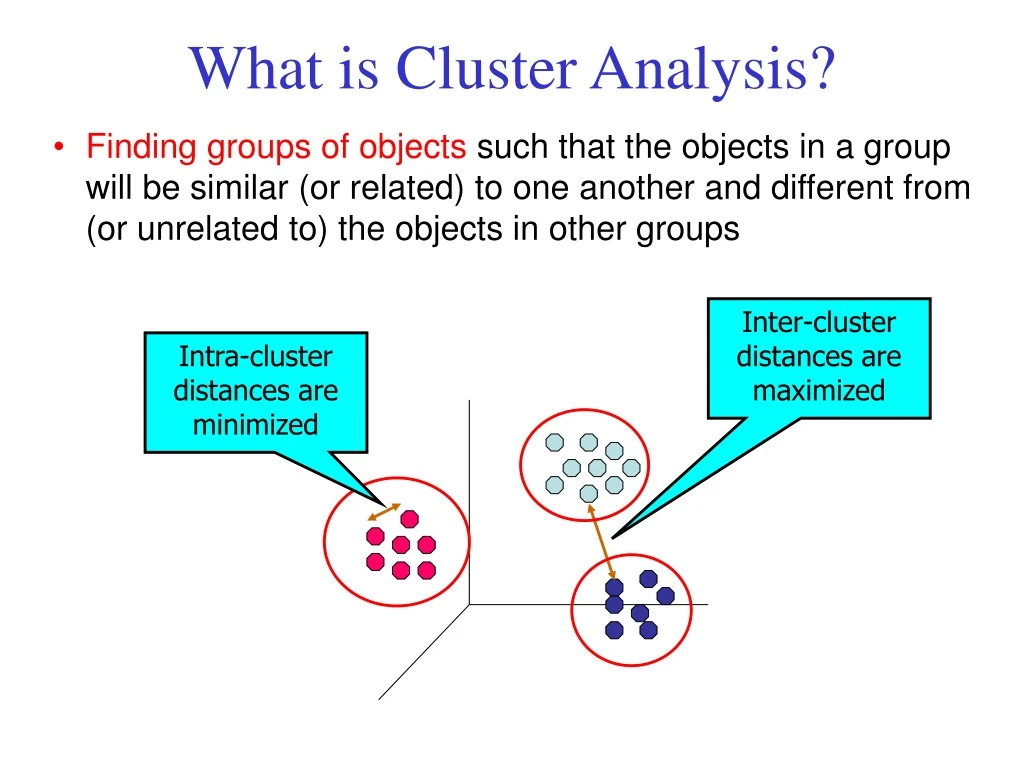
Inter-cluster distances are maximized Intra-cluster distances are minimized What is Cluster Analysis? • Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groups
Clustering precipitation in Australia Applications of Cluster Analysis • Clustering for Understanding • Group related documents for browsing • Group genes and proteins that have similar functionality • Group stocks with similar price fluctuations • Segment customers into a small number of groups for additional analysis and marketing activities. • Clustering for Summarization • Reduce the size of large data sets
Similarity and Dissimilarity • Similarity • Numerical measure of how alike two data objects are. • Higher when objects are more alike. • Can be transformed to fall in interval [0,1] by doing: s’ = (s – min_s)/(max_s – min_s) • Dissimilarity • Numerical measure of how different are two data objects • Lower when objects are more alike • Minimum dissimilarity is often 0 • Can be transformed to fall in interval [0,1] by doing: d’ = (d – min_d)/(max_d – min_d) • These proximity measures for objects with a number of attributes is defined by combining the proximities of individual attributes. • Thus, we first discuss proximity between objects having a single attribute.
Similarity/Dissimilarity for Simple Attributes • p and q are the attribute values for two data objects. • Nominal • E.g. province attribute of an address with values: • {BC, AB, ON, QC, …} • Order not important. • Dissimilarity • d=0 if p=q • d=1 if pq • Similarity • s=1 if p=q • s=0 if pq
Similarity/Dissimilarity for Simple Attributes • p and q are the attribute values for two data objects. • Ordinal • E.g. quality attribute of a product with values: • {poor, fair, OK, good, wonderful} • Order is important, but the difference between values not defined or not important. • Map the values of the attribute to successive integers • {poor=0, fair=1, OK=2, good=3, wonderful=4} • Dissimilarity • d(p,q) = |p – q| / (max_d – min_d) • e.g.d(wonderful, fair) = |4-1| / (4-0) = .75 • Similarity • s(p,q) = 1 – d(p,q)e.g.d(wonderful, fair) = .25
Similarity/Dissimilarity for Simple Attributes • p and q are the attribute values for two data objects. • Continuous (or Interval) • E.g. weight attribute of a product • Dissimilarity • d(p,q) = |p – q| • Similarity • s(p,q) = – d(p,q) • Of course, we can transform them in the [0,1] scale.
Combining Similarities • Sometimes attributes are of many different types, but an overall similarity/dissimilarity is needed. • Similar formula for dissimilarity
Euclidean Distance • When all the attributes are continuous we can use the Euclidean Distance Where n is the number of dimensions (attributes) and pk and qk are, respectively, the kth attributes (components) or data objects p and q. • Standardization is necessary, if scales differ • E.g. weight, salary have different scales
Euclidean Distance Distance Matrix
Minkowski Distance • Minkowski Distance is a generalization of Euclidean Distance Where r is a parameter, n is the number of dimensions (attributes) and pk and qk are, respectively, the kth attributes (components) or data objects p and q.
Minkowski Distance: Examples • r = 1. City block (Manhattan, taxicab, L1 norm) distance. • r = 2. Euclidean distance • r. “supremum” (Lmax norm, Lnorm) distance. • This is the maximum difference between any component of the vectors • Do not confuse r with n, i.e., all these distances are defined for all numbers of dimensions.
Minkowski Distance Distance Matrix
Similarity Between Binary Vectors • Common situation is that objects, p and q, have only binary attributes • Compute similarities using the following quantities M01= the number of attributes where pwas 0 and qwas 1 M10 = the number of attributes where pwas 1 and qwas 0 M00= the number of attributes where pwas 0 and qwas 0 M11= the number of attributes where pwas 1 and qwas 1 • Simple Matching and Jaccard Coefficients SMC = number of matches / number of attributes = (M11 + M00) / (M01 + M10 + M11 + M00) J = number of M11 matches / number of not-both-zero attributes values = (M11) / (M01 + M10 + M11)
SMC versus Jaccard: Example p = 1 0 0 0 0 0 0 0 0 0 q = 0 0 0 0 0 0 1 0 0 1 M01= 2 (the number of attributes where p was 0 and q was 1) M10= 1 (the number of attributes where p was 1 and q was 0) M00= 7 (the number of attributes where p was 0 and q was 0) M11= 0 (the number of attributes where p was 1 and q was 1) SMC = (M11 + M00)/(M01 + M10 + M11 + M00) = (0+7) / (2+1+0+7) = 0.7 J = (M11) / (M01 + M10 + M11) = 0 / (2 + 1 + 0) = 0
Cosine Similarity If D1 and D2 are two document vectors, then cos( D1, D2 ) = (D1 D2) / ||D1||.||D2|| , where indicates vector dot product and || D|| is the length of vector D. Example: D1 D2= .4*0 + .33*0 + 0*.33 + 0*1 + .17*.33 = .0561 ||D1|| = sqrt(.40^2 + .33^2 + .17^2) = .55 ||D2|| = sqrt(.33^2 + 1^2 + .33^2) = 1.1 cos( D1, D2 ) = .0561 / (.55 * 1.1) = .093 If the cosine similarity is 1, the angle between D1 and D2 is 0o, and D1 and D2 are the same except for the magnitude. If the cosine similarity is 0, then the angle between D1 and D2 is 90o, and they don’t share any terms (words).
Extended Jaccard Coefficient (Tanimoto) • Variation of Jaccard for document data • Reduces to Jaccard for binary attributes T( D1, D2 ) = (D1 D2) / ( ||D1||2 + ||D2||2 - D1 D2)
Inter-cluster distances are maximized Intra-cluster distances are minimized What is Cluster Analysis? • Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groups
A Partitional Clustering Partitional Clustering A division of data objects into non-overlapping subsets (clusters) such that each data object is in exactly one subset. Original Points
Hierarchical Clustering • A set of nested clusters organized as a hierarchical tree • Each node (cluster) in the tree (except for the leaf nodes) is the union of its children (subclusters), and the root of the tree is the cluster containing all the objects.
3 well-separated clusters Types of Clusters: Well-Separated • Well-Separated Clusters: • A cluster is a set of points such that any point in a cluster is closer (or more similar) to every other point in the cluster than to any point not in the cluster.
4 center-based clusters Types of Clusters: Center-Based • Center-based • A cluster is a set of objects such that an object in a cluster is closer (more similar) to the “center” of a cluster, than to the center of any other cluster • The center of a cluster is often a centroid, the average of all the points in the cluster, or a medoid, the most “representative” point of a cluster
8 contiguous clusters Types of Clusters: Contiguity-Based • Contiguous Cluster (Nearest neighbor or Transitive) • A cluster is a set of points such that a point in a cluster is closer (or more similar) to one or more other points in the cluster than to any point not in the cluster.
6 density-based clusters Types of Clusters: Density-Based • Density-based • A cluster is a dense region of points, which is separated by low-density regions, from other regions of high density. • Used when the clusters are irregular or intertwined, and when noise and outliers are present.
K-means Clustering • Partitional clustering approach • Each cluster is associated with a centroid (center point) • Each point is assigned to the cluster with the closest centroid • Number of clusters, K, must be specified • The basic algorithm is very simple
K-means Clustering – Details • Initial centroids may be chosen randomly. • Clusters produced vary from one run to another. • The centroid is (typically) the mean of the points in the cluster. • ‘Closeness’ is measured by Euclidean distance, cosine similarity, etc. • Most of the convergence happens in the first few iterations. • Often the stopping condition is changed to ‘Until relatively few points change clusters’ • Complexity is O(I * K* n * d ) • n = number of points, K = number of clusters, I = number of iterations, d = number of attributes
Document Data • Kmeans is not restricted to data in Euclidean space. • Document data is represented as a documentterm matrix. • For document data, we consider the cosine similarity measure. (dot product of frequency vectors) • Objective is to maximize the similarity of the documents in a cluster to the cluster centroid; • this quantity is known as the cohesion of the cluster. • For this objective it can be shown that the cluster centroid is, as for Euclidean data, the mean.
Evaluating K-means Clusters • Most common measure is Sum of Squared Error (SSE) • For each point, the error is the distance to the nearest cluster • To get SSE, we square these errors and sum them. • xis a data point in cluster Ci and mi is the representative point for cluster Ci • It can be shown that to minimize SSE, mishould correspond to the center (mean) of the cluster. • This is the rationale behind adjusting the centroid to be the mean of the cluster points.
Optimal Clustering Sub-optimal Clustering Two different K-means Clusterings Original Points
Problems with Selecting Initial Points • Of course, the ideal would be to choose initial centroids, one from each true cluster. However, this is very difficult. • If there are K ‘real’ clusters then the chance of selecting one centroid from each cluster is small. • Chance is relatively small when K is large • If clusters are the same size, n, then • For example, if K= 10, then probability = 10!/1010 = 0.00036 • Sometimes the initial centroids will readjust themselves in the ‘right’ way, and sometimes they don’t. • Consider an example of five pairs of clusters
10 Clusters Example Starting with two initial centroids in one cluster of each pair of clusters
10 Clusters Example Starting with two initial centroids in one cluster of each pair of clusters
10 Clusters Example Starting with some pairs of clusters having three initial centroids, while other have only one.
10 Clusters Example Starting with some pairs of clusters having three initial centroids, while other have only one.
Solutions to Initial Centroids Problem • Multiple runs • Helps, but probability is not on your side • Bisecting K-means • Not as susceptible to initialization issues
Bisecting Kmeans • Straightforward extension of the basic Kmeans algorithm. Simple idea: To obtain K clusters, split the set of points into two clusters, select one of these clusters to split, and so on, until K clusters have been produced. Algorithm Initialize the list of clusters to contain the cluster consisting of all points. repeat Remove a cluster from the list of clusters. //Perform several ``trial'' bisections of the chosen cluster. fori = 1 to number of trials do Bisect the selected cluster using basic Kmeans (i.e. 2-means). end for Select the two clusters from the bisection with the lowest total SSE. Add these two clusters to the list of clusters. until the list of clusters contains K clusters.
Reducing SSE with Post-processing • Obvious way to reduce the SSE is to find more clusters, i.e., to use a larger K. • However, in many cases, we would like to improve the SSE, but don't want to increase the number of clusters. • Various techniques are used to “fix up” the resulting clusters in order to produce a clustering that has lower SSE. • Commonly used approach: Use alternate cluster splitting and merging phases. • Split a cluster: • split the cluster with the largest SSE, or • split the cluster with the largest standard deviation for one particular attribute. • Merge two clusters: • merge the two clusters with the closest centroids, or • merge the two clusters that result in the smallest increase in total SSE.
Limitations of K-means • K-means has problems when clusters are of differing • Sizes • Densities • Non-globular shapes • K-means has problems when the data contains outliers.
Limitations of K-means: Differing Sizes K-means (3 Clusters) Original Points
Limitations of K-means: Differing Density K-means (3 Clusters) Original Points
Limitations of K-means: Non-globular Shapes Original Points K-means (2 Clusters)
Overcoming K-means Limitations Original Points K-means Clusters • One solution is to use many clusters. • Find parts of clusters, but need to put together. • Apply merge strategy
Overcoming K-means Limitations Original Points K-means Clusters
Overcoming K-means Limitations Original Points K-means Clusters
