Download
1 / 1
10 likes | 221 Views
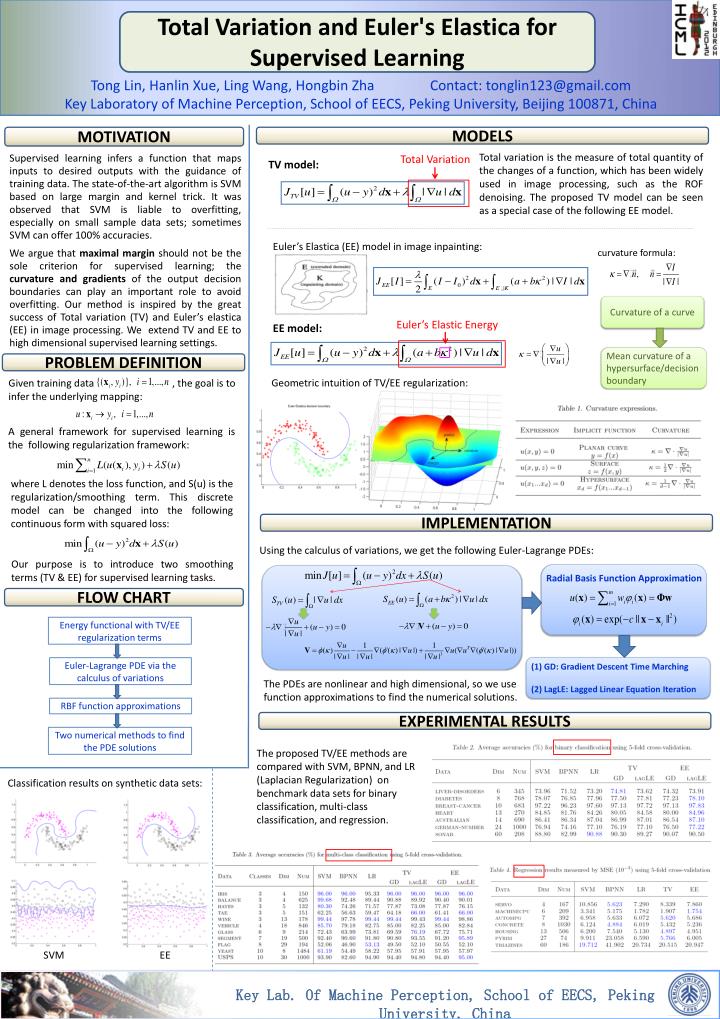
Total Variation and Euler's Elastica for Supervised Learning. Tong Lin, Hanlin Xue , Ling Wang, Hongbin Zha Contact: tonglin123@gmail.com Key Laboratory of Machine Perception, School of EECS, Peking University, Beijing 100871, China. MOTIVATION. MODELS.

E N D
Total Variation and Euler's Elastica for Supervised Learning Tong Lin, HanlinXue, Ling Wang, HongbinZha Contact: tonglin123@gmail.com Key Laboratory of Machine Perception, School of EECS, Peking University, Beijing 100871, China MOTIVATION MODELS Total variation is the measure of total quantity of the changes of a function, which has been widely used in image processing, such as the ROF denoising. The proposed TV model can be seen as a special case of the following EE model. Supervised learning infers a function that maps inputs to desired outputs with the guidance of training data. The state-of-the-art algorithm is SVM based on large margin and kernel trick. It was observed that SVM is liable to overfitting, especially on small sample data sets; sometimes SVM can offer 100% accuracies. We argue that maximal margin should not be the sole criterion for supervised learning; the curvature and gradients of the output decision boundaries can play an important role to avoid overfitting. Our method is inspired by the great success of Total variation (TV) and Euler’s elastica (EE) in image processing. We extend TV and EE to high dimensional supervised learning settings. Euler’s Elastica (EE) model in image inpainting: TV model: curvature formula: Curvature of a curve Mean curvature of a hypersurface/decision boundary Total Variation EE model: PROBLEM DEFINITION Euler’s Elastic Energy Geometric intuition of TV/EE regularization: Using the calculus of variations, we get the following Euler-Lagrange PDEs: IMPLEMENTATION Radial Basis Function Approximation Energy functional with TV/EE regularization terms • Euler-Lagrange PDE via the • calculus of variations RBF function approximations (1) GD: Gradient Descent Time Marching (2) LagLE: Lagged Linear Equation Iteration Two numerical methods to find the PDE solutions The PDEs are nonlinear and high dimensional, so we use function approximations to find the numerical solutions. Given training data , the goal is to infer the underlying mapping: FLOW CHART A general framework for supervised learning is the following regularization framework: EXPERIMENTAL RESULTS where L denotes the loss function, and S(u) is the regularization/smoothing term. This discrete model can be changed into the following continuous form with squared loss: The proposed TV/EE methods are compared with SVM, BPNN, and LR (Laplacian Regularization) on benchmark data sets for binary classification, multi-class classification, and regression. Classification results on synthetic data sets: Our purpose is to introduce two smoothing terms (TV & EE) for supervised learning tasks. SVM EE Key Lab. Of Machine Perception, School of EECS, Peking University, China


















