Download

1 / 41

E N D
ODHADY PARAMETRŮ ZÁKLADNÍHO SOUBORU Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021) za přispění finančních prostředků EU a státního rozpočtu České republiky.
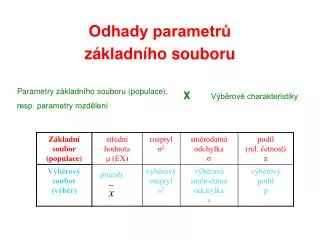
ZÁKLADNÍ x VÝBĚROVÝ SOUBOR ZÁKLADNÍ SOUBOR – skládá se ze všech jednotek, které patří k množině, jež je předmětem analýzy (tedy všechny teoreticky změřitelné jednotky – jejich počet nemusí být znám, velikost ZS může být teoreticky nekonečně veliká – na obrázku vpravo naznačeno rozmlženým okrajem). ZS musí být dobře definován. Popisem ZS se zabývá popisná statistika. VÝBĚROVÝ SOUBOR – skládá se z podmnožiny ZS, jeho prvky jsou vybírány náhodným výběrem (naznačeno červenými obdélníčky). Je to množina reálně měřených dat, která slouží k odhadu vlastností ZS. Znamená to, že při praktickém měření reálně známe pouze údaje o prvcích (stromečcích) v rámečku, ale odhadujeme z nich vlasntnosti všech prvků ZS (všech stromečků, i těch, které nejsou na obrázku, pokud má ZS větší velikost). Analýzou VS a odhadem vlastností ZS se zabývá matematická statistika.
ZÁKLADNÍ PRINCIP ODHADU PARAMETRŮ Proč musíme parametry a další vlastnosti základního souboru (ZS) odhadovat? Protože ve většině případů neznáme (nemáme změřeny) všechny prvky ZS. Pokud bychom všechny tyto údaje znali, nemusíme nic odhadovat a vše (tj. všechny statistické vlastnosti) víme „přesně“, „stoprocentně“. Ovšem ZS může být nezměřitelně nebo nekonečně veliký. Potom na vlastnosti ZS můžeme usuzovat jen na základě údajů získaných z jeho podmnožiny – výběrového souboru (VS) – a všechny soudy o ZS jsou zatíženy určitou nejistotou vyplývající z toho, že o ZS nemáme úplnou informaci. Proto veškeré parametry a další vlastnosti ZS je možné pouze odhadnout se stanovenou pravděpodobností. Tento postup je nejčastější (v 99,999… % případů) – celý ZS známe jen zcela výjimečně. Celý proces odhadu ukazuje následující obrázek
PARAMETRje statistická charakteristika základního souboru (značí se řeckými písmeny, např. střední hodnota ). STATISTIKA je statistická charakteristika výběrového souboru (značí se latinkou, např. výběrový průměr ). ZÁKLADNÍ POJMY SPOJENÉ S VÝBĚROVÝMI ŠETŘENÍMI ODHAD PARAMETRU ZÁKLADNÍHO SOUBORU je určitá hodnota (hodnoty) vhodné statistiky získaná postupem zvaným bodový nebo intervalový odhad.
VÝBĚROVÝ PRŮMĚR a jeho vlastnosti Pro rozdělení výběrového průměru platí: Odhadem střední hodnoty ZS je střední hodnota(E(.)) výběrových průměrů, tedy „průměr průměrů“. Znamená to, že kdybychom provedli velké množství výběrů (teoreticky nekonečně mnoho) a ze všech spočítali průměry, potom nejlepším odhadem střední hodnoty ZS (kterou neznáme, protože neznáme celý ZS) by byl průměr všech takto zjištěných průměrů jednotlivých výběrů Tato veličina se nazývá střední chyba průměru (SE - standard error) a je to vlastně směrodatná odchylka výběrového průměru, tj. ukazuje míru možného kolísání hodnot výběrových průměrů vypočítaných z různých výběrů provedených ze stejného ZS. Čím je tato hodnota menší, tím je toto možné kolísání hodnot vývěrových průměrů menší – a tím je tedy určení střední hodnoty ZS spolehlivější. SE závisí přímo úměrně na variabilitě ZS (σ) – čím jsou data variabilnější, tím je také možnost větší variability výběrových průměrů SE závisí nepřímo úměrně na velikosti výběru (n) – čím máme větší výběr (tedy víme toho víc o ZS), tím je určení střední hodnoty ZS spolehlivější.
VÝBĚROVÝ PRŮMĚR a jeho vlastnosti Centrální limitní věta (CLV): Jestliže výběr pochází ze ZS s libovolným rozdělením se střední hodnotou a směrodatnou odchylkou , potom výběrový průměr má při dostatečné velikosti výběru nvýběrové normální rozdělení se střední hodnotou a mírou variability 2/n, tedy N(,2/n) Rozdělení výběrového průměru (hnědá plocha) Hustota (pravděpodobnost výskytu hodnot) Směrodatná odch. výb. průměru σ/n Směrodatná odchylka (σ) základního souboru Rozdělení základního souboru (není normální) Hodnoty Střední hodnota ZS i výběrového průměru
VÝBĚROVÝ PRŮMĚR a jeho vlastnosti Nenormální (levostranné) Obrázek ukazuje, že pro „dostatečnou“ velikost výběru (obvykle n = 30 nebo víc) je rozdělení výběrového průměru normální, ať je rozdělení základního souboru jakékoliv. Pro malé velikosti výběru (n = 2,10) toto neplatí, výběrová rozdělení jsou blízká původnímu rozdělení základního souboru. Rovnoměrné Normální Rozdělení základního souboru Rozdělení výb. průměru
VÝBĚROVÝ PRŮMĚR a jeho vlastnosti Ilustrace CLV: Horní obrázek ukazuje ZS, který nemá nornální rozdělení (je levostranný, průměr (modrá čárka) a medián (fialová čárka) se liší, variabilita je značná (červená svorka - +- 1S). Dolní grafy ukazují rozdělení 1000 výběrových průměrů o velikosti 5 a 25. Je vidět, že obě rozdělení jsou velmi blízká normálnímu rozdělení, z dolního grafu vyplývá, že větší výběr (N=25) má nižší variabilitu rozdělení průměrů. S nastavením těchto dat a různými počty a velikostmi výběrů je možné „experimentovat“ na stránce: http://onlinestatbook.com/stat_sim/sampling_dist/index.html
ZÁKLADNÍ VLASTNOSTI BODOVÝCH ODHADŮ • nespornost (konzistence) – se vzrůstající velikostí výběru vzrůstá i pravděpodobnost, že odhad bude blízký skutečnému parametru. • nevychýlenost (nestrannost) - střední hodnota výběrové statistiky T se rovná odhadovanému parametru P základního souboru („průměr průměrů“) • E(T) = P • vydatnost – znamená, že daný nevychýlený odhad má se srovnání se všemi ostatními nevychýlenými odhady nejmenší variabilitu (rozptyl)
ZÁKLADNÍ VLASTNOSTI BODOVÝCH ODHADŮ skutečná hodnota parametru ZS jednotlivé výběrové průměry
ZÁKLADNÍ VLASTNOSTI BODOVÝCH ODHADŮ vychýlení odhadu skutečná hodnota parametru ZS y - výběrové průměry M - „průměr průměrů“ z hodnot y – vypočítaný odhad střední hodnoty ZS Grafické znázornění vychýleného odhadu – pokud se střední hodnota výběrových statistik M liší od skutečné hodnoty parametru, potom se jedná o vychýlený odhad.
ZÁKLADNÍ VLASTNOSTI BODOVÝCH ODHADŮ nevychýlený a vydatný odhad nevychýlený odhad s velkou variabilitou (nevydatný)
BODOVÉ ODHADYZÁKLADNÍCH PARAMETRŮ Odhad střední hodnoty: Odhad rozptylu: Výraz S2*(n/(n-1) je nestranný konzistentní odhad rozptylu D(X) náhodné veličiny X. korekce vychýlení
hustota pravděpodobnosti základního souboru („nekonečný“ počet šedých bodů) tato vzdálenost je pro jeden konkrétní výběr neznámá (protože neznáme polohu )není možné určit spolehlivost konkrétního odhadu (tj. zda vychýlení výběrového průměru je „milimetr nebo kilometr“) – proto se pro odhad parametrů ZS používají raději intervalové odhady hodnoty výběrového souboru BODOVÉ ODHADYZÁKLADNÍCH PARAMETRŮ střední hodnota ZS – v praxi ji neznáme, znali bychom ji pouze, pokud bychom znali celý ZS -všechny šedé body výběrový průměr – vypočítaný z červených bodů – z výběrového souboru – tuto hodnotu známe
toto je bodový odhad neznámé střední hodnoty vypočítaný z prvků výběru – nevíme nic o jeho vztahu ke skutečné střední hodnotě T2 T1 toto je intervalový odhad neznámé střední hodnoty - předpokládáme, že s pravděpodobností P =1- leží nám neznámé kdekoli v tomto úseku číselné osy INTERVALOVÉ ODHADY PARAMETRŮ ZS Interval spolehlivosti pro parametr při hladině významnosti (0,1) je určen statistikami T1 a T2:. Čteme: Pravděpodobnost, že parametr základního souboru leží v intervalu (T1;T2), je 1 – α. Označení je obecné, parametrem může být střední hodnota, směrodatná odchylka, rozptyl,… atd.) prvky výběru
INTERVALOVÉ ODHADYPARAMETRŮ ZS A VÝZNAM HODNOTY α Hlavní rozdílem intervalového odhadu oproti bodovému je to, že místo jedné hodnoty určujeme zpravidla dvě hodnoty – hranice intervalu. Hlavní výhodou intervalového odhadu je fakt, že můžeme určit pravděpodobnost (spolehlivost) odhadu, tj. že můžeme prohlásit, že neznámý parametr leží v daném intervalu s pravděpodobností …. %. Pravděpodobnost odhadu určujeme pomocí hladiny významnosti α, přičemž platí, že s pravděpodobností 1-α vypočítaný interval obsahuje skutečnou hodnotu parametru ZS. Hodnota α je tedy pravděpodobnost („riziko“) toho, že intervalový odhad nebude skutečnou hodnotu parametru obsahovat. Nejčastější používanou hodnotou α je 0,05 (tj. 5%). V tomto případě interval spolehlivosti (IS) platí s pravděpodobností 95%. Připouštíme 5% „riziko“, že vypočítaný IS je „chybný“, tj. neobsahuje skutečnou hodnotu parametru. Musíme totiž připustit, že „náhodou“ se může stát, že náš náhodně zvolený výběr bude tak „extrémní“, že skutečná hodnota parametru bude mimo něj. Tento případ ukazuje následující obrázek.
tyto intervaly spolehlivosti „obsahují“ střední hodnotu (jsou tedy „správné“), těch (při opakovaných výběrech) bude nejméně (1- ).100 % tento interval spolehlivosti „neobsahuje“ střední hodnotu (je tedy „chybný“), těchto intervalů se objeví nejvýše (100) % HLADINA VÝZNAMNOSTI V INTERVALOVÝCH ODHADECH Zde jsou ze ZS (všechny možné body pod zelenomodrou křivkou) se střední hodnotou (modrá čárkovaná čára) vybrány 3 náhodné výběry – červený zelený a fialový (jsou to 3 výběry z teoreticky nekonečného počtu výběrů). Zatímco IS vypočítané z červeného a zeleného výběru obsahují hodnotu parametru (modrá čára označující jimi prochází), fialové body jsou natolik vychýleny, že jejich IS je příliš vlevo a skutečnou hodnotu parametru neobsahuje). Hodnota α = 0,05 zaručuje, že těchto „chybných“ odhadů nebude víc než max. 5 %, tj. např. 5 ze 100 výběrů.
HLADINA VÝZNAMNOSTI V INTERVALOVÝCH ODHADECH Obrázek ukazuje křivku rozdělení výběrového průměru se středem a směrodatnou odchylkou σ/n . Ze ZS se známou střední hodnotou bylo na počítači náhodně vygenerováno padesát výběrů o rozsahu n = 10 a byly spočteny a nakresleny intervaly spolehlivosti. Z padesáti intervalů pouze dva nepokrývají průměr ZS , který je znázorněn vertikální čárou (tyto dva intervaly jsou na obrázku označeny šipkami). Teorie předvídá, že 5 % takových intervalů nepokryje střední hodnotu ZS (v našem případě 5% z 50, tj. 2,5. Naše simulace je tedy v dobrém souladu s teorií, protože pouze 2 IS nepokrývají skutečnou střední hodnotu. V praxi samozřejmě provedeme pouze jediný výběr o rozsahu n a spočteme intervalový odhad parametru . Nevíme ovšem, zda náš interval pokryje , nebo ne. Protože ale známe vlastnosti výběrového rozdělení průměru, můžeme se stanovenou spolehlivostí (např. 95%) předpokládat, že jsme nedostali jeden z těch neobvyklých intervalů, které nepokrývají . Proto také vypočtenému intervalu říkáme 95% interval spolehlivosti pro . (podle http://ucebnice.euromise.cz/index.php?conn=0§ion=biostat1&node=8#SECTION00820000000000000000)
1= /2 P = 1 - = 1 – (1 + 2) 2= /2 T1 T2 T OBOUSTRANNÉ INTERVALOVÉ ODHADY PARAMETRŮ ZS Při konstrukci oboustranného IS musíme „rozložit“ pravděpodobnost α na obě strany intervalu. Je tomu tak proto, že pokud se toto „riziko“ naplní (tj. IS nebude obsahovat skutečnou hodnotu parametru ZS), my nevíme, kde je skutečná hodnota parametru, zda vlevo nebo vpravo od IS. Proto se obě hranice oboustranného IS konstruují na základě pravděpodobnosti α/2, nikoli α. Oboustranné IS se používají jako základní, vždy, pokud chceme odhadnout hodnotu parametru ZS a tuto hodnotu neporovnáváme s nějakou hraniční hodnotou (normou apod.).
JEDNOSTRANNÉ INTERVALOVÉ ODHADY Jednostranné intervaly spolehlivosti používáme tehdy, pokud chceme porovnat hodnotu parametru ZS s nějakou hraniční hodnotou (normou apod.), kdy na druhé straně intervalu „nezáleží“, kdy je pro nás hlavně podstatné, zda hodnota parametru může nebo nemůže v ZS přesáhnout uvedenou hraniční hodnotu. Příkladem může být měření škodlivin v ovzduší. Každá škodlivina (SO2, prachové částice, …) má stanovenou normu středních hodnot za určitý čas (např. za den), která by neměla být „překonána“. ZS je zde teoreticky nekonečný počet možných měření. My samozřejmě můžeme změřit pouze omezený reálný počet měření – a to bude výběrový soubor (VS). Otázka zní, zda v případě, že bychom změřili „nekonečný“ počet měření, by střední hodnota obsahu škodliviny v ovzduší přesáhla normu. Na obrázcích zelené body představují VS, žlutá čára výběrový průměr (vypočítaný z hodnot VS), červená čára normu, a fialová čára je jednostranný (pravostranný ) IS. norma V tomto případě vypočítaný výběrový průměr je sice menší než norma, ale my potřebujeme vědět, zda je pravděpodobné, že vy střední hodnota „nekonečného počtu“ měření mohla s danou pravděpodobností přesáhnout normu. V tomto případě tomu tak není (pravá hranice IS je pod normou). norma V tomto případě vypočítaný výběrový průměr je sice menší než norma, ale my potřebujeme vědět, zda je pravděpodobné, že vy střední hodnota „nekonečného počtu“ měření mohla s danou pravděpodobností přesáhnout normu. V tomto případě tomu tak je (pravá hranice IS je nad normou, možnou příčinou je vyšší variabilita těchto měření). Znamená to, že v tomto případě bychom učinili závěr, že norma byla překročena.
JEDNOSTRANNÉ INTERVALOVÉ ODHADY U jednostranných odhadů používáme k výpočtu hranice (levé nebo pravé) hodnotu α, a to proto, že IS může neobsahovat skutečnou hodnotu parametru pouze na jedné straně, na druhé straně jde interval do „nekonečna“. pravostranný odhad levostranný odhad
1 T jednostranný intervalový odhad P = 1 - T1 2 T1 T2 oboustranný intervalový odhad P = 1 - = 1 – (1 + 2) POROVNÁNÍ JEDNOSTRANNÉHO A ODOUSTRANNÉHO ODHADU
POROVNÁNÍ JEDNOSTRANNÉHO A ODOUSTRANNÉHO ODHADU Obrázek ukazuje hodnoty (kvantily) normovaného normálního rozdělení, které odpovídají hodnotám α 0,05 (pro IS platný s 95% pravděpodobností), 0,01 (pro IS platný s 99% pravděpodobností) a 0,001 (pro IS platný s 99,9% pravděpodobností), a to pro jednostranný levostranný IS (obr. a), pro oboustranný IS (obr. b) a pro jednostranný pravostranný IS (obr. c) . Tyto hodnoty(kvantily) se využívají při výpočtu IS (viz dále).
INTERVAL SPOLEHLIVOSTISTŘEDNÍ HODNOTY je známa směrodatná odchylka základního souboru nebo je používán velký výběr (nad 30 prvků) v případě velkého výběru lze použít místo výběrovou směrodatnou odchylku S dolní hranice horní hranice z/2 je kvantil normovaného normálního rozdělení pro hladinu významnosti /2
INTERVAL SPOLEHLIVOSTISTŘEDNÍ HODNOTY není známa směrodatná odchylka základního souboru a je používán malý výběr (do 30 prvků) Základní vzorec pro výpočet IS střední hodnoty. Výhodou je to, že za předpokladu normálního rozdělení je IS symetrický podle výběrového průměru. Znamená to, že vypočítáme polovinu IS (výraz v zeleném rámečku) a tuto hodnotu odečteme od výběrového průměru (tím získáme dolní hranici IS) a přičteme k výběrovému průměru (tím získáme horní hranici IS). Tento vzorec můžeme použít pro jakoukoliv velikost výběru – pro malé výběry (do 30 prvků) jej použít musíme (platí zde t-rozdělení místo normálního rozdělení) a pro velké výběry (nad 30 prvků) můžeme (se vzrůstající velikostí výběru se t-rozdělení blíží rozdělení normálnímu, až s ním prakticky splyne). horní hranice dolní hranice t/2,n-1 je kvantil Studentova t-rozdělení pro hladinu významnosti /2 a (n-1) stupňů volnosti
Účelem korekce je zmenšit standardní chybu INTERVAL SPOLEHLIVOSTISTŘEDNÍ HODNOTY velikost základního souboru je známa (N) a výběrový soubor je relativně velký (n > 5 % N) Používá se korekce na konečný základní soubor:
INTERVALY SPOLEHLIVOSTI –PROVEDENÍ V EXCELU interval spolehlivosti střední hodnoty a) pomocí doplňku Analýza dat rozsah dat výběru hodnota 100.(1-)% musí být zatrženo !!
Způsob počítá interval spolehlivosti podle vzorce Způsob počítá interval spolehlivosti podle vzorce INTERVALY SPOLEHLIVOSTI –PROVEDENÍ V EXCELU pomocí funkce CONFIDENCE hodnota směrodatná odchylka (např. vypočítaná pomocí modulu „Popisná statistika“ velikost výběru pro stejná data vychází „širší“, protože t-rozdělení má vyšší variabilitu pro stejná data vychází „užší“, protože normované normální rozdělení má nižší variabilitu
FAKTORY OVLIVŇUJÍCÍ VELIKOST INTERVALU SPOLEHLIVOSTI (IS) • velikost výběru (čím větší výběr, tím užší IS) • hladina význanosti (čím vyšší hodnota , tím užší interval – nižší hladina významnosti (např. 0,01 místo 0,05) znamená požadavek vyšší spolehlivosti určení IS - pokud určíme =0,01, požadujeme spolehlivost IS P=99%, pokud určíme =0,05, požadujeme spolehlivost IS P=95%, IS musí být širší pro P=99% než pro P=95%, protože musíme zaručit vyšší spolehlivost) • variabilita (čím vyšší hodnota směrodatné odchylky, tím širší IS) • použitý vzorec (pokud používáme t-rozdělení, je IS širší než při použití N(0,1), rozdíl je markantnější u malých výběrů)
INTERVAL SPOLEHLIVOSTI SMĚRODATNÉ ODCHYLKY pro malé výběry Výpočet intervalu spolehlivosti směrodatné odchylky využívá 2-rozdělení a je nesouměrný – nesouměrnost je vyšší u odhadů vycházejících z malých výběrů. Proto musíme vypočítat zvlášť dolní a horní hranici. S2 je rozptyl výběru, χ2 je hodnota chi-kvadrát (Pearsonova) rozdělení. Hodnoty chi-kvadrátu musíme vypočítat dvě (pro hladinu významnosti α/2 a pro 1-α/2, což je možné v Excelu pomocí funkce CHIINV, kde za „Prst“ dosadíme hladinu významnosti a za „Volnost“ počet stupňů volnosti (n-1).
INTERVAL SPOLEHLIVOSTI SMĚRODATNÉ ODCHYLKY pro velké výběry (nad 30 prvků) Výpočet intervalu spolehlivosti směrodatné odchylky pro velké výběry využívá normovaného normálního rozdělení a je souměrný.
VELIKOST VÝBĚRU Obecně platí – čím větší – tím lepší. Nejlepší je žádný (použít základní soubor. Obvyklá otázka zní: Jakou minimální velikost výběru potřebuji vzhledem k účelu analýzy a k požadované vypovídací schopnosti o základním souboru? Jedním ze základních kritérií velikosti výběru je požadovaná přesnost a spolehlivost určení stanoveného parametru (obvykle střední hodnoty).
VELIKOST VÝBĚRU Jaká bude maximální povolená „vzdálenost“ mezi odhadem parametru a vlastním parametrem? Odpovědí je přesnost odhadu, značená D. Jakou požadujeme spolehlivost, že skutečná vzdálenost mezi odhadem a skutečným parametrem bude menší nebo nejvýše rovna D? Odpovědí je spolehlivost odhadu daná hodnotou 100.(1-). Musíme tedy určit hladinu významnosti . Jaká je variabilita základního souboru (většinou ji neznáme, je nutné použít co nejpřesnější odhad). Určíme ji pomocí rozptylu (S2) nebo variačního koeficientu (S%).
Jakou velikost výběru n ze základního souboru s variabilitou danou rozptylem S2minimálně potřebuji, abych se spolehlivostí 100.(1-) % zabezpečil, že střední hodnota se bude pohybovat v intervalu D (výběrový průměr přesnost odhadu)? +D -D VELIKOST VÝBĚRU ZALOŽENÁ NA INTERVALU SPOLEHLIVOSTI
VELIKOST VÝBĚRU ZALOŽENÁ NA INTERVALU SPOLEHLIVOSTI t/2 kvantil t-rozdělení pro hladinu významnosti /2 a pro n-1 stupňů volnosti. Pro 1. aproximaci n odhadneme, pro 2. počítáme s výsledným (n-1) z 1. aproximace a pokračujeme tak dlouho, dokud se n mění. Pro velké výběry můžeme použít přímo z /2. Vzorec vlevo se používá, pokud variabilitu (S2) i přesnost odhadu (D2) určujeme absolutně, tj.v jednotkách měřené veličiny. Vzorec vpravo se používá, pokud obé určujeme relativně (v %).
VELIKOST VÝBĚRU ZALOŽENÁ NA INTERVALU SPOLEHLIVOSTI Můžeme využít jednoduché excelovské tabulky (list „velikost výběru“) zde: http://user.mendelu.cz/drapela/Statisticke_metody/Data_do_cviceni/Velikost_vyberu.xls Řešené příklady na téma velikosti výběru jsou v souboru (první dvě strany z tohoto dokumentu) http://user.mendelu.cz/drapela/Statisticke_metody/Data_do_cviceni/Velikost_vyberu.doc Pro první aproximaci využijeme odhadnutou velikost výběru 30: Ve žlutém poli vyjde 1. vypočítaný odhad n (17), vzhledem k tomu, že se tato hodnota liší od původně zadané hodnoty 30, pro další výpočet zadáme 17 místo 30.)
VELIKOST VÝBĚRU ZALOŽENÁ NA INTERVALU SPOLEHLIVOSTI Po dalších dvou aproximacích vyjde konečná velikost výběru 18 (při zadání hodnoty 18 do buňky E3 zůstává stejná hodnota i v buňce F9). Dále se můžeme přesvědčit, že vypočítaná (skutečná) přesnost určení střední hodnoty tloušťky při použití výběru velikosti 18 je 1,989 cm (tmavě žlutá buňka E11), což splňuje naši podmínku přesnosti 2 cm.
VELIKOST VÝBĚRU ZALOŽENÁ NA INTERVALU SPOLEHLIVOSTI K řešení použijeme stejnou tabulku jako v předchozím příkladu, pouze zadáme hodnoty zjištěné z naměřeného výběru (do buňky E1 hodnotu S 4,8, do buňky E3 realizovanou velikost výběru 30. Předpokládáme, že chceme přesnost odhadu střední hodnoty určit se spolehlivostí 95 %, proto necháme hodnotu na 0,05. Ostatních hodnot si „nevšímáme“.